
平均最近隣距離法では、各地物の重心と最近隣地物の重心位置との間の距離が測定され、
次に、すべての最近隣距離の平均が計算されます。
結果は分布がランダムなのか、まとまったものなのかが評価されます。
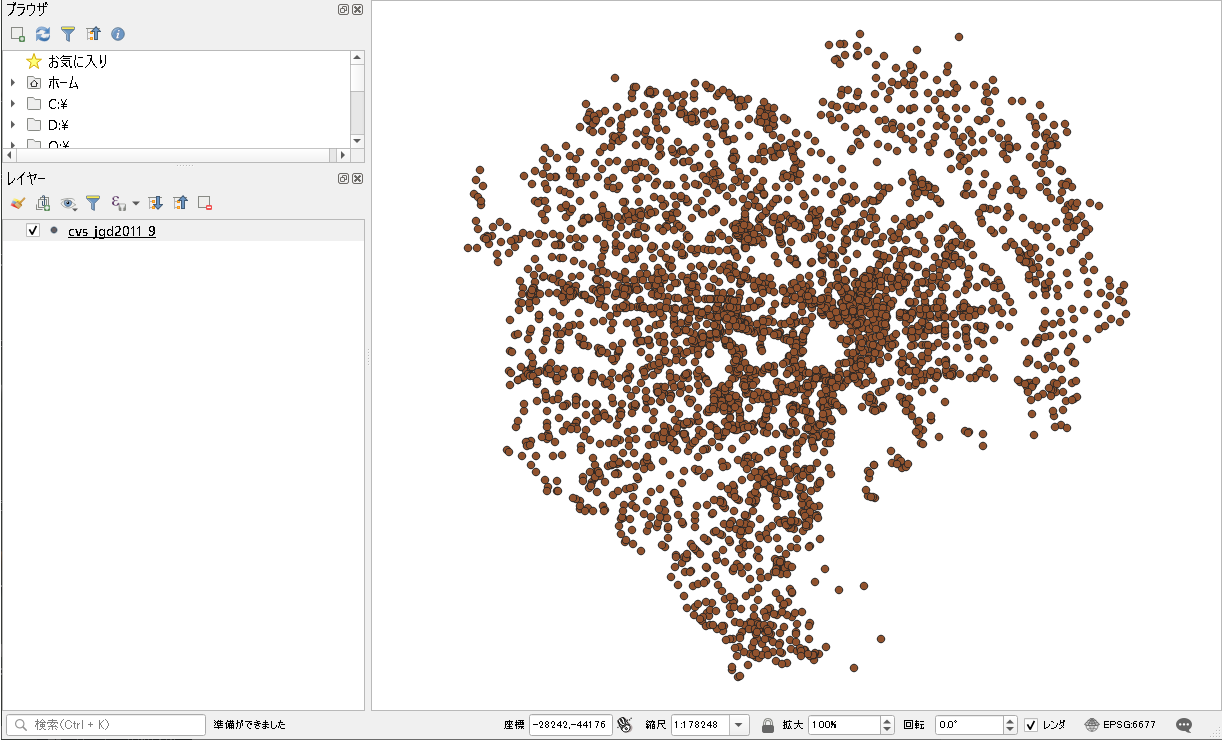
QGISを使います。
サンプルデータとして、tokyo(cvs_jgd2011_9.shp)が読み込まれているものとします。
コンビニのデータです。
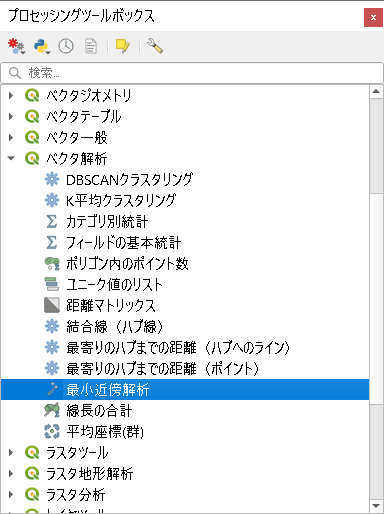
メニュで、プロセッシング -> ツールボックスを開いて、
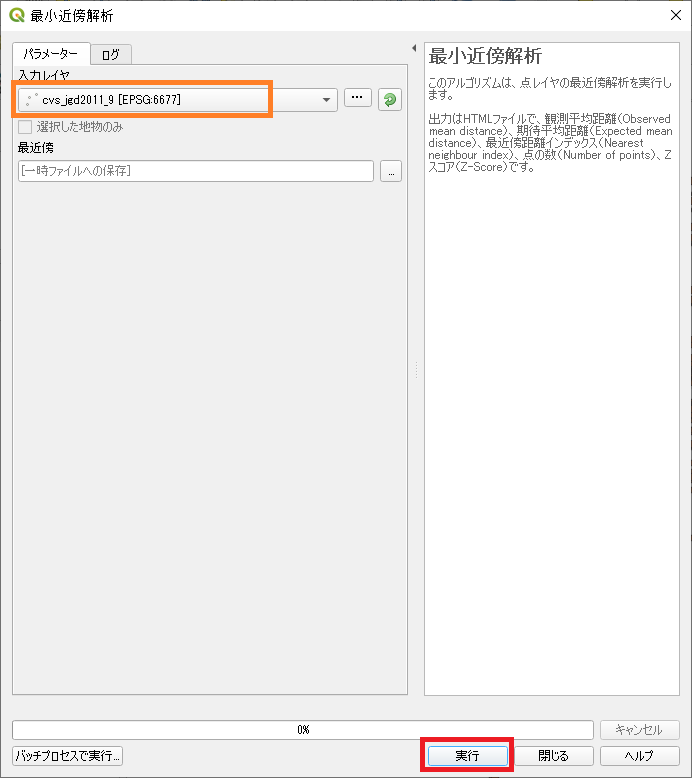
ベクタ解析 -> 最小近傍解析をダブルクリック
実行
結果をブラウザーで表示します。
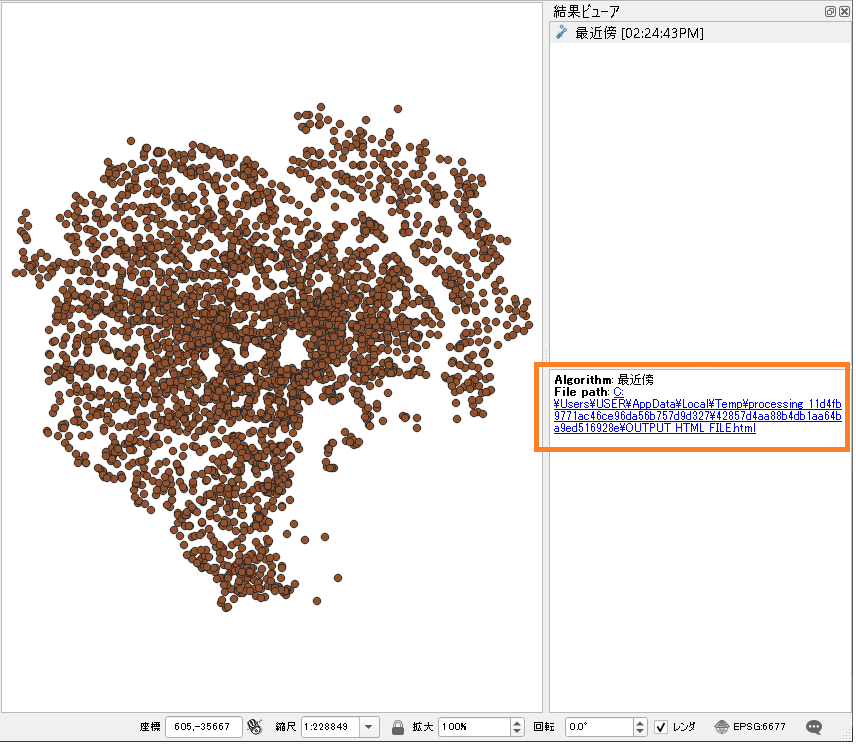
こんな感じ。
Observed mean distance: 169.79873750355532
Expected mean distance: 246.96149541862331
Nearest neighbour index: 0.6875514630964241
Number of points: 3853
Z-Score: -37.10298772962362
こういうことです。
Observed mean distance :観測された平均距離
Expected mean distance :期待される平均距離->仮説であるランダムな分布における近隣間の平均距離
Nearest naighbour index:最近隣距離インデックス(指数、指標)
(観測された平均距離/期待される平均距離)
指標が 1 未満の場合、パターンはクラスター分布(まとまった分布)であることを示しています。
指標が 1 を上回っている場合は、分散または競合に向かう傾向にあります。
Number of points:地物の総数
Z-Score:Z スコア(標準偏差)
Leave a Reply