
姿勢推定については、以前にOpenPoseを使ってやってみましたが、使ったtf_pose_estimateのリポジトリがGihubから消えてました。
作り直すのもなんなので、新規に環境を作成してみます。
trt_pose です。
TensotRTを使って少々重いネットワークモデルでもエッジデバイス上で高速に推論実行できるすぐれものです。
ただし、trt_pose では、ONNX経由やプラグインでTensotRTを使うのではなく、PytorchのモデルをダイレクトにTensorRTに転送して最適化するtorch2trt なるものを使います。どんなモデルなら使えるかはサイトをご参照ください。
で、こんなことをやってみます。

実行確認はJupyter Notebookでやります。
こんな感じ。
使うのはJetson Nano(4GB)、Jetpack(4.5.1)です。
MicroSDカードは32GBからですが、このサイズだとギリです。NanoのRAMは4GBしかないので実行にはSwap(4GBくらい)が必須です。できれば64GBのSDカードをお勧めします。
プラットフォームもストレスなしで実行するにはNanoより8GB RAMのXavier NX がいいです(高いですけど~~)。
動画像の取得にはUSBカメラを使います。

チュートリアルとは違ってPytorchとTorchVisionが実装されているNVIDIA コンテナに環境を作ってみます。
以下の記述で/home/jetsonのユーザー名は適宜ご自分の環境のユーザー名で置き換えてください。
SDカードにJetpackを焼いて初期設定は終わっているものとします。
Swapは4GBくらいで設定します。
作業用のフォルダーを作っておきます。
|
1 |
mkdir work-pose |
ドッカーイメージを取得します。
|
1 |
sudo docker pull nvcr.io/nvidia/l4t-ml:r32.5.0-py3 |
my_poseという名前でコンテナを作成します。カメラはUSB1台という前提です。deviceオプションの番号は0です。
sudo docker create -it --name my_pose --gpus all --network host -e DISPLAY=$DISPLAY -v /tmp/.X11-unix/:/tmp/.X11-unix --device /dev/video0:/dev/video0:mwr -v /home/jetson/work-pose:/work nvcr.io/nvidia/l4t-ml:r32.5.0-py3
コンテナを起動します。
|
1 |
sudo docker start -i my_pose |
お約束のアップデート&アップグレード。
|
1 2 3 |
apt update apt upgrade -y python3 -m pip install --upgrade pip |
USBカメラからの画像取得にはJetCam を使います。
An easy to use Python camera interface for NVIDIA Jetson
NVIDIAJetson用の使いやすいPythonのカメラインターフェース
だそうです。
インストールしておきます。
|
1 2 3 4 5 |
apt install python3-setuptools -y git clone https://github.com/NVIDIA-AI-IOT/jetcam cd jetcam python3 setup.py install |
マウントしておいた 作業フォルダーに移動
|
1 |
cd /work |
torch2trtをインストールするところから始めます。
|
1 2 3 |
git clone https://github.com/NVIDIA-AI-IOT/torch2trt cd torch2trt python3 setup.py install --plugins |
その他のパッケージをインストール。
|
1 2 |
pip3 install tqdm cython pycocotools apt install python3-matplotlib |
trt_pose をインストール。
|
1 2 3 |
git clone https://github.com/NVIDIA-AI-IOT/trt_pose cd trt_pose python3 setup.py install |
JetCamでUSBカメラからの画像をNotebookで表示できるように、Jupyterに拡張機能を入れておきます。
これをしないと以下のような出力になって動画像が表示されませんでした。
Image(value=b’\xff\xd8\xff\xe0\x00\x10JFIF\x00\x01\x01\x00\x00\x01\x00\x01\x00\x00\xff\xdb\x00C\x00\x02\x01\x0…
|
1 2 3 4 |
cd / pip3 install ipywidgets jupyter nbextension enable --py widgetsnbextension |
labextensionのインストールにはNode.js は10.0.0 以上が必要です。
Node.jsのバージョンを上げておきます。
|
1 2 3 4 5 6 |
wget https://nodejs.org/dist/v12.13.0/node-v12.13.0-linux-arm64.tar.xz tar -xJf node-v12.13.0-linux-arm64.tar.xz cd node-v12.13.0-linux-arm64 cp -R * /usr/local/ node -v |
インストール。細い線がクルクルするだけで進捗が分かりません。目安は4分です。
|
1 |
jupyter labextension install @jupyter-widgets/jupyterlab-manager |
インストールが終わったら、コンテナを閉じてJetsonを再起動。その後コンテナも再起動 。
|
1 2 3 |
sudo reboot sudo docker start -i my_pose |
以下をクリックして「resnet18_baseline_att_224x224_Aモデルのweights(81MB)」をダウンロード。
ダウンロードしたファイルは/home/jetson/work-pose/torch2trt/trt_pose/tasks/human_poseに移動しておきます。
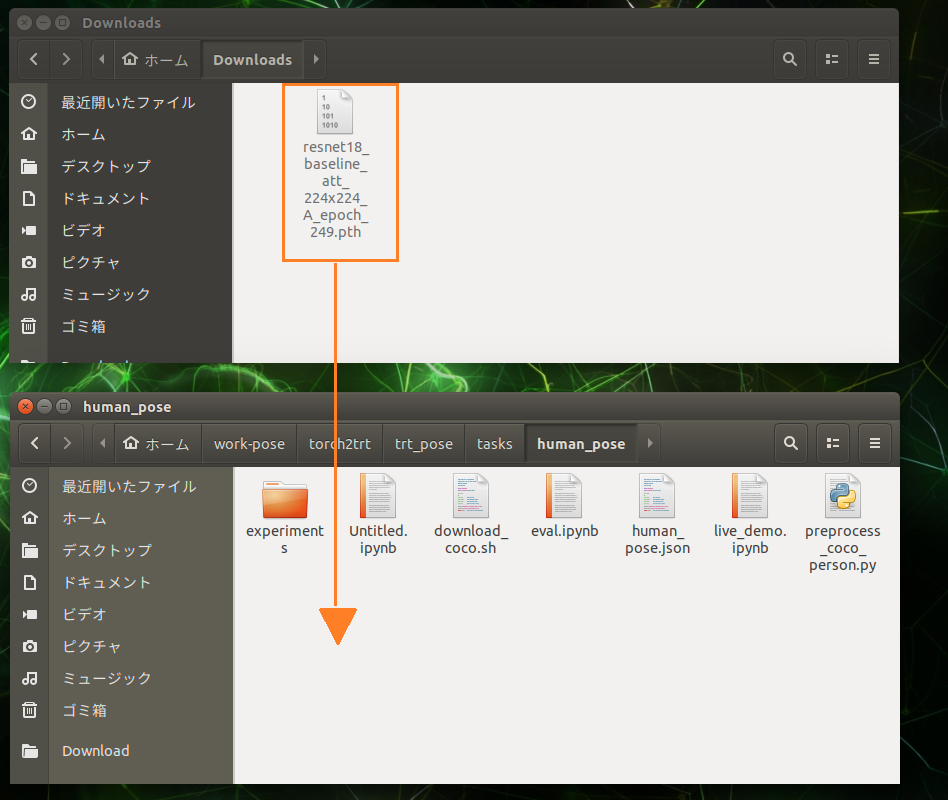
Jetsonのブラウザーでダウンロードして以下のコマンドを使う場合、「ダウンロード」フォルダー名を「Downloads」に改名してください。
sudo mv /home/jetson/Downloads/resnet18_baseline_att_224x224_A_epoch_249.pth /home/jetson/work-pose/torch2trt/trt_pose/tasks/human_pose
trt_pose を実行
コンテナ側ではJupyterは起動しています。以下のディレクトリに移動しておきます。
|
1 |
cd /work/torch2trt/trt_pose/tasks/human_pose |
ブラウザーでNotebook を開きます。
127.0.0.1:8888
パスワードを聞かれたら「nvidia」です。
Notebook でPython3を使いましょう。
First, let’s load the JSON file which describes the human pose task. This is in COCO format, it is the category descriptor pulled from the annotations file. We modify the COCO category slightly, to add a neck keypoint. We will use this task description JSON to create a topology tensor, which is an intermediate data structure that describes the part linkages, as well as which channels in the part affinity field each linkage corresponds to.
まず、人間のポーズタスクを記述したJSONファイルをロードしましょう。 これはCOCO形式であり、注釈ファイルから取得されたカテゴリ記述子です。 COCOカテゴリを少し変更して、ネックキーポイントを追加します。 このタスク記述JSONを使用して、トポロジーテンソルを作成します。これは、パーツリンケージ、および各リンケージが対応するパーツアフィニティフィールドのチャンネルを記述する中間データ構造です。
|
1 2 3 4 5 6 7 |
import json import trt_pose.coco with open('human_pose.json', 'r') as f: human_pose = json.load(f) topology = trt_pose.coco.coco_category_to_topology(human_pose) |
Next, we’ll load our model. Each model takes at least two parameters, cmap_channels and paf_channels corresponding to the number of heatmap channels and part affinity field channels. The number of part affinity field channels is 2x the number of links, because each link has a channel corresponding to the x and y direction of the vector field for each link.
次に、モデルをロードします。 各モデルは、ヒートマップチャンネルとパーツアフィニティフィールドチャンネルの数に対応するcmap_channelsとpaf_channelsの少なくとも2つのパラメータを取ります。 各リンクには、各リンクのベクトル場のx方向とy方向に対応するチャンネルがあるため、パーツアフィニティフィールドチャンネルの数はリンク数の2倍です。
|
1 2 3 4 5 6 |
import trt_pose.models num_parts = len(human_pose['keypoints']) num_links = len(human_pose['skeleton']) model = trt_pose.models.resnet18_baseline_att(num_parts, 2 * num_links).cuda().eval() |
Next, let’s load the model weights.
次に、モデルの重みをロードしましょう。
|
1 2 3 4 5 |
import torch MODEL_WEIGHTS = 'resnet18_baseline_att_224x224_A_epoch_249.pth' model.load_state_dict(torch.load(MODEL_WEIGHTS)) |
In order to optimize with TensorRT using the python library torch2trt we’ll also need to create some example data. The dimensions of this data should match the dimensions that the network was trained with. Since we’re using the resnet18 variant that was trained on an input resolution of 224×224, we set the width and height to these dimensions.
Pythonライブラリtorch2trtを使用してTensorRTで最適化するには、いくつかのサンプルデータも作成する必要があります。 このデータのディメンションは、ネットワークがトレーニングされたディメンションと一致する必要があります。 224×224の入力解像度でトレーニングされたresnet18バリアントを使用しているため、幅と高さをこれらの寸法に設定します。
|
1 2 3 4 |
WIDTH = 224 HEIGHT = 224 data = torch.zeros((1, 3, HEIGHT, WIDTH)).cuda() |
Next, we’ll use torch2trt to optimize the model. We’ll enable fp16_mode to allow optimizations to use reduced half precision.
次に、torch2trtを使用してモデルを最適化します。 fp16_modeを有効にして、最適化で半精度下げて使用できるようにします。
Jetson Nano で2~3分かかります(Xavier NXでも同じくらいです)。
|
1 2 3 |
import torch2trt model_trt = torch2trt.torch2trt(model, [data], fp16_mode=True, max_workspace_size=1<<25) |
The optimized model may be saved so that we do not need to perform optimization again, we can just load the model. Please note that TensorRT has device specific optimizations, so you can only use an optimized model on similar platforms.
最適化されたモデルを保存して、再度最適化を実行する必要がないようにすることができます。モデルをロードするだけです。 TensorRTにはデバイス固有の最適化があるため、同様のプラットフォームでのみ最適化されたモデルを使用できることに注意してください。
Colabでトレーニングしたモデルを最適化する場合はJetsonでやらなきゃいかん….ということのようです。
|
1 2 3 |
OPTIMIZED_MODEL = 'resnet18_baseline_att_224x224_A_epoch_249_trt.pth' torch.save(model_trt.state_dict(), OPTIMIZED_MODEL) |
We could then load the saved model using torch2trt as follows.
次に、torch2trtを使用して、保存したモデルを次のようにロードできます。
|
1 2 3 4 |
from torch2trt import TRTModule model_trt = TRTModule() model_trt.load_state_dict(torch.load(OPTIMIZED_MODEL)) |
We can benchmark the model in FPS with the following code
次のコードを使用して、FPSでモデルをベンチマークできます。
|
1 2 3 4 5 6 7 8 9 10 |
import time t0 = time.time() torch.cuda.current_stream().synchronize() for i in range(50): y = model_trt(data) torch.cuda.current_stream().synchronize() t1 = time.time() print(50.0 / (t1 - t0)) |
Next, let’s define a function that will preprocess the image, which is originally in BGR8 / HWC format.
次に、元々BGR8 / HWC形式の画像を前処理する関数を定義しましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
import cv2 import torchvision.transforms as transforms import PIL.Image mean = torch.Tensor([0.485, 0.456, 0.406]).cuda() std = torch.Tensor([0.229, 0.224, 0.225]).cuda() device = torch.device('cuda') def preprocess(image): global device device = torch.device('cuda') image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) image = PIL.Image.fromarray(image) image = transforms.functional.to_tensor(image).to(device) image.sub_(mean[:, None, None]).div_(std[:, None, None]) return image[None, ...] |
Next, we’ll define two callable classes that will be used to parse the objects from the neural network, as well as draw the parsed objects on an image.
次に、ニューラルネットワークからオブジェクトを解析するために使用される2つの呼び出し可能なクラスを定義し、解析されたオブジェクトを画像上に描画します。
|
1 2 3 4 5 |
from trt_pose.draw_objects import DrawObjects from trt_pose.parse_objects import ParseObjects parse_objects = ParseObjects(topology) draw_objects = DrawObjects(topology) |
Assuming you’re using NVIDIA Jetson, you can use the jetcam package to create an easy to use camera that will produce images in BGR8/HWC format.
NVIDIA Jetsonを使用していると仮定すると、jetcamパッケージを使用して、BGR8 / HWC形式で画像を生成する使いやすいカメラを作成できます。
以下は/dev/video0 のUSBカメラを使っている場合です。
|
1 2 3 4 5 6 7 8 |
from jetcam.usb_camera import USBCamera # from jetcam.csi_camera import CSICamera from jetcam.utils import bgr8_to_jpeg camera = USBCamera(width=WIDTH, height=HEIGHT, capture_fps=30,capture_device=0) # camera = CSICamera(width=WIDTH, height=HEIGHT, capture_fps=30) camera.running = True |
Next, we’ll create a widget which will be used to display the camera feed with visualizations.
次に、視覚化されたカメラフィードを表示するために使用されるウィジェットを作成します。
|
1 2 3 4 5 6 |
import ipywidgets from IPython.display import display image_w = ipywidgets.Image(format='jpeg') display(image_w) |
Finally, we’ll define the main execution loop. This will perform the following steps
最後に、メインの実行ループを定義します。 これにより、次の手順が実行されます
1.Preprocess the camera image
カメラ画像を前処理する
2.Execute the neural network
ニューラルネットワークを実行する
3.Parse the objects from the neural network output
ニューラルネットワーク出力からオブジェクトを解析します
4.Draw the objects onto the camera image
オブジェクトをカメラ画像に描画します
5.Convert the image to JPEG format and stream to the display widget
画像をJPEG形式に変換し、表示ウィジェットにストリーミングします
|
1 2 3 4 5 6 7 8 |
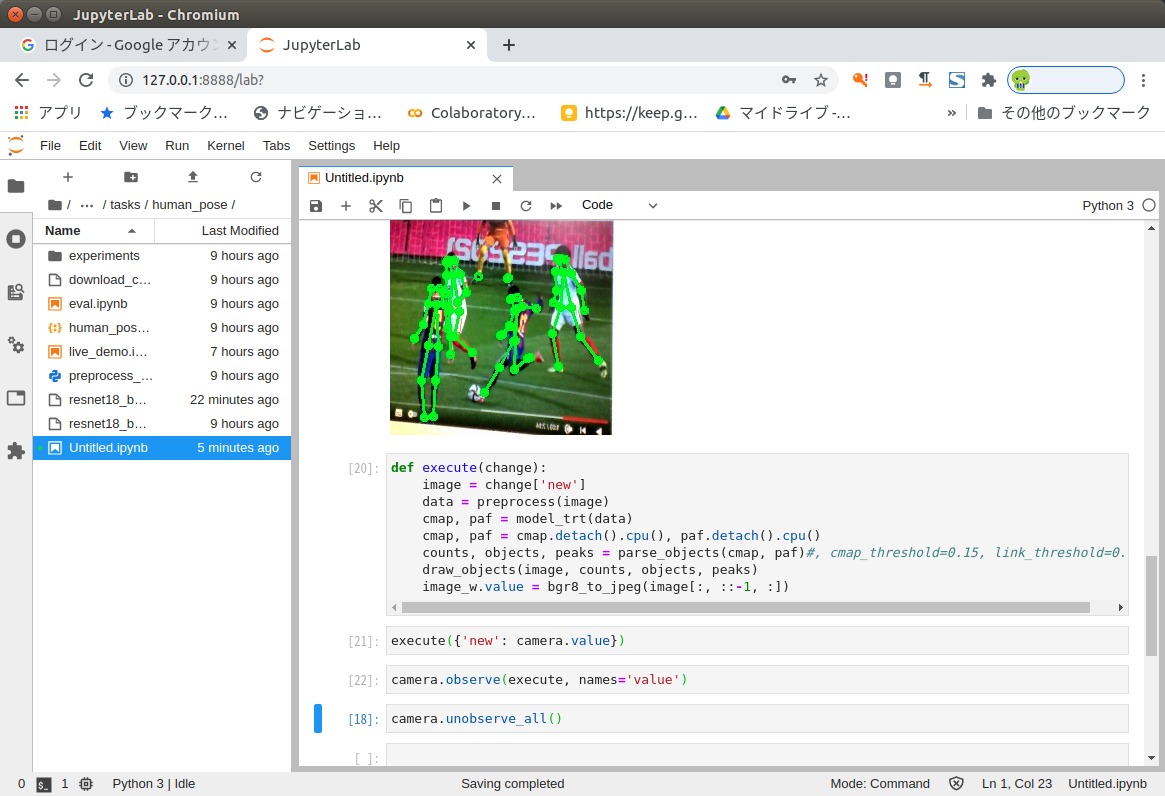
def execute(change): image = change['new'] data = preprocess(image) cmap, paf = model_trt(data) cmap, paf = cmap.detach().cpu(), paf.detach().cpu() counts, objects, peaks = parse_objects(cmap, paf)#, cmap_threshold=0.15, link_threshold=0.15) draw_objects(image, counts, objects, peaks) image_w.value = bgr8_to_jpeg(image[:, ::-1, :]) |
If we call the cell below it will execute the function once on the current camera frame.
下のセルを呼び出すと、現在のカメラフレームで関数が1回実行されます。
シングルショットで姿勢推定画像を取得できます。
|
1 |
execute({'new': camera.value}) |

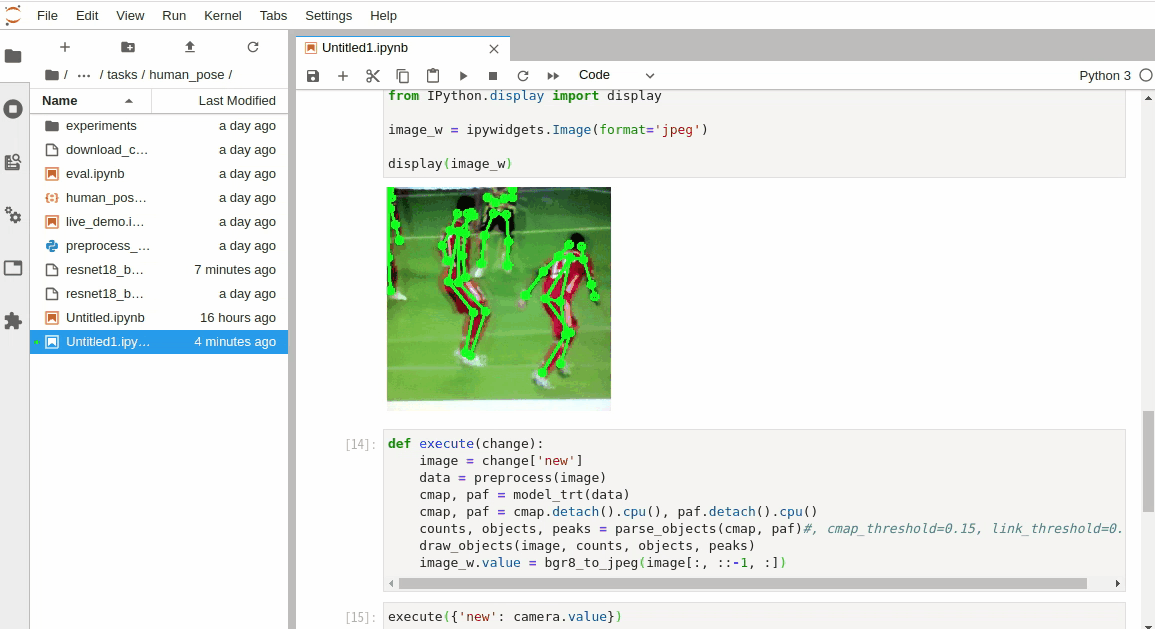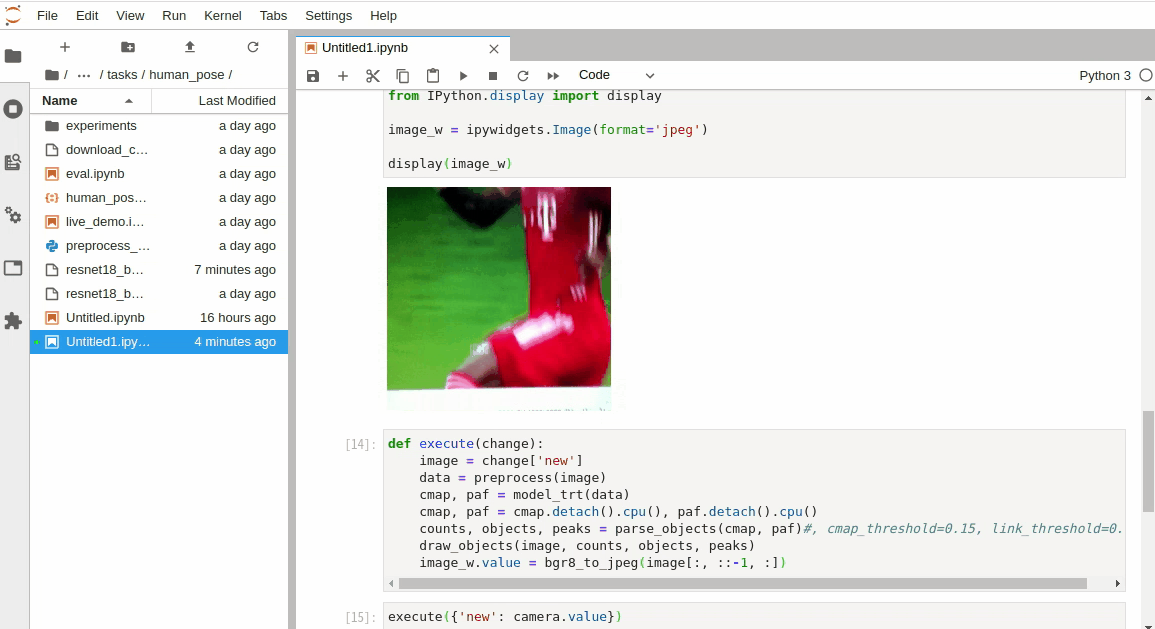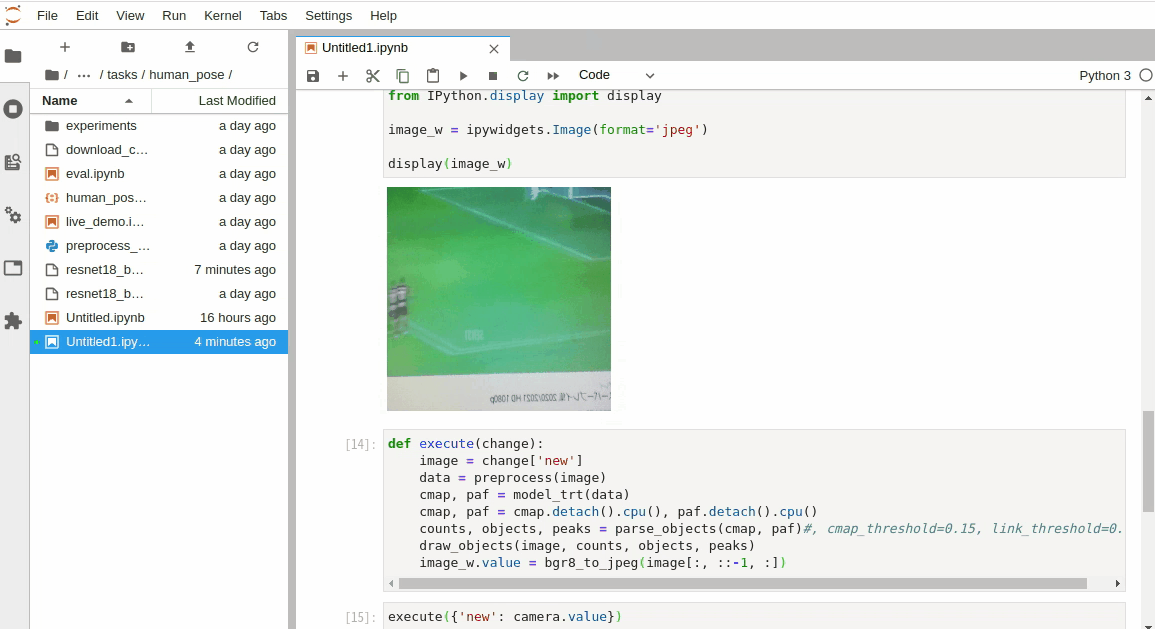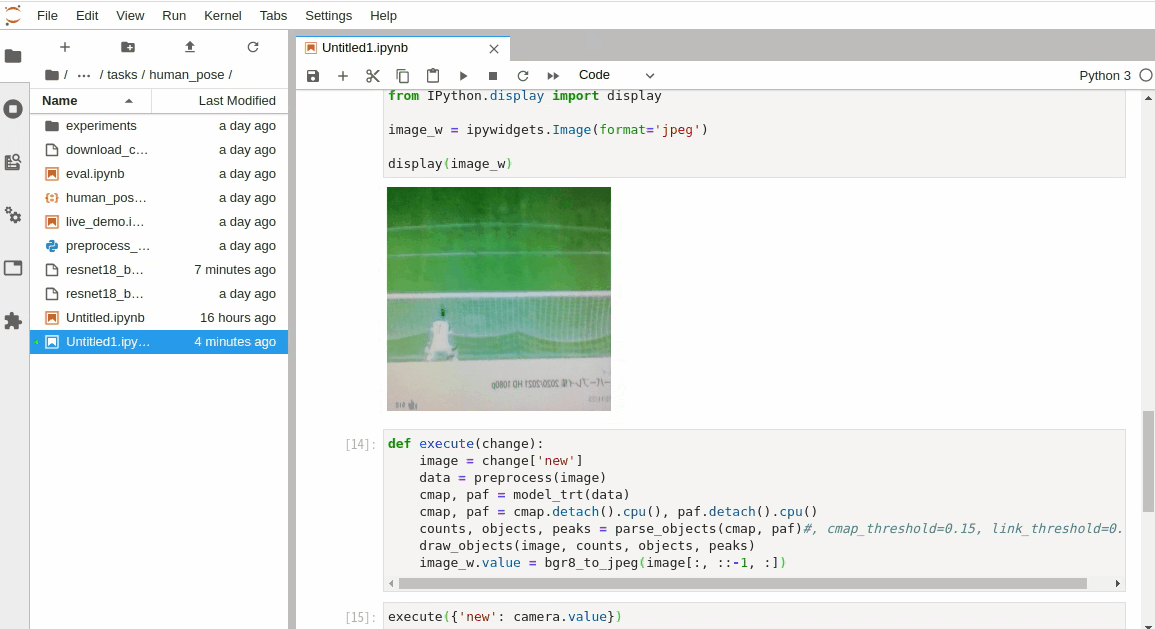
Call the cell below to attach the execution function to the camera’s internal value. This will cause the execute function to be called whenever a new camera frame is received.
下のセルを呼び出して、実行関数をカメラの内部値にアタッチします。 これにより、新しいカメラフレームが受信されるたびにexecute関数が呼び出されます。
ムービーで姿勢推定動画像を取得できます。
|
1 |
camera.observe(execute, names='value') |
パフォーマンスはNanoでもXavier NX でもこんな感じです。TensorRTはすごいですね。
Call the cell below to unattach the camera frame callbacks.
下のセルを呼び出して、カメラフレームコールバックのアタッチを解除します。
|
1 |
camera.unobserve_all() |
推定されたposeのskeleton(線)やkeypoints(円)の座標を見てみます
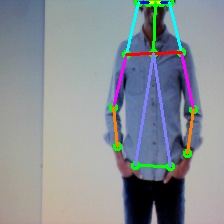
画像に円と線を描画しているのは以下のコードです。
/work/torch2trt/trt_pose/trt_pose/draw_objects.py
エディタで開いて、描画をしている行の下に以下を追加して実行時に表示してみます。
cv2.circle(image, (x, y), 3, color_green, 2)
print(“P_ID=”+ str(j+1) + “:x=” + str(x) + “,y=” + str(y)) <-これ
・
・
・
cv2.line(image, (x0, y0), (x1, y1), color, 2)
print(“L_ID=” + str(k) + “:x0=” + str(x0) + “,y0=” + str(y0) + “,x1=” + str(x1) + “,y1=” + str(y1)) <-これ
再ビルドします。
|
1 2 |
cd /work/torch2trt/trt_pose python3 setup.py install |
実行してみます。
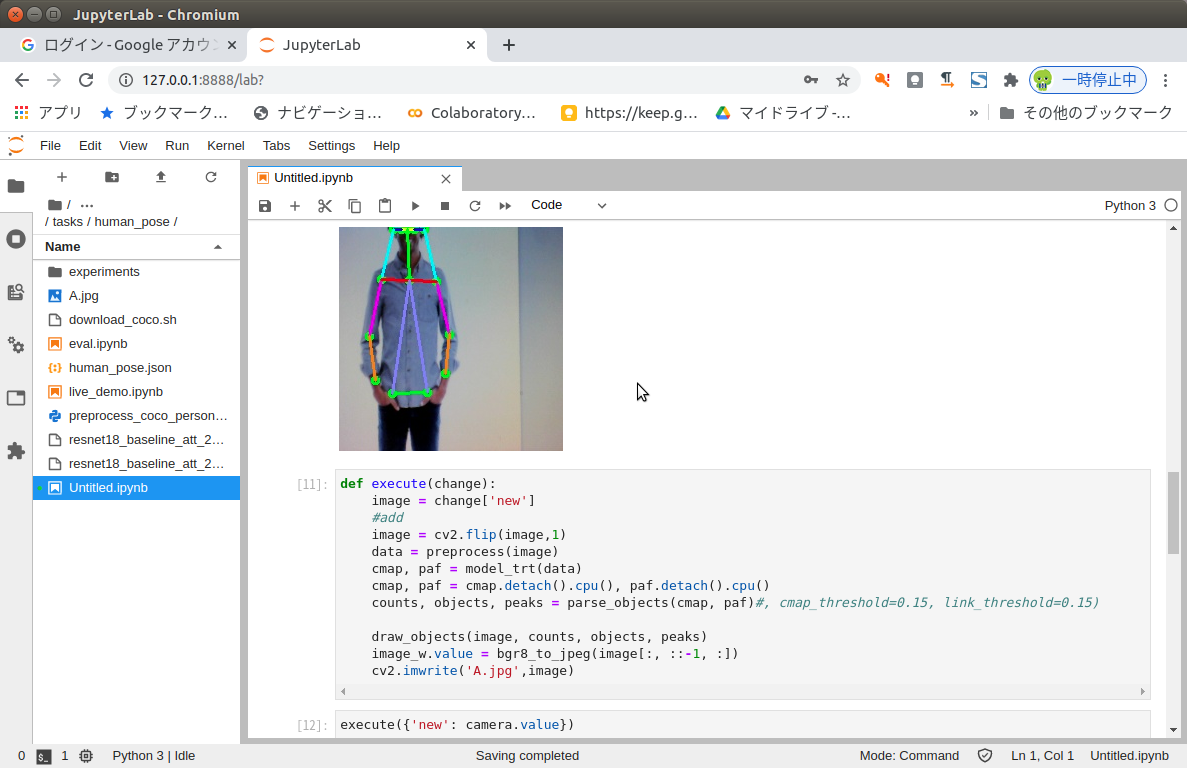
IDが飛んでいるのは、描画されるべき線や円が無いからのようです。
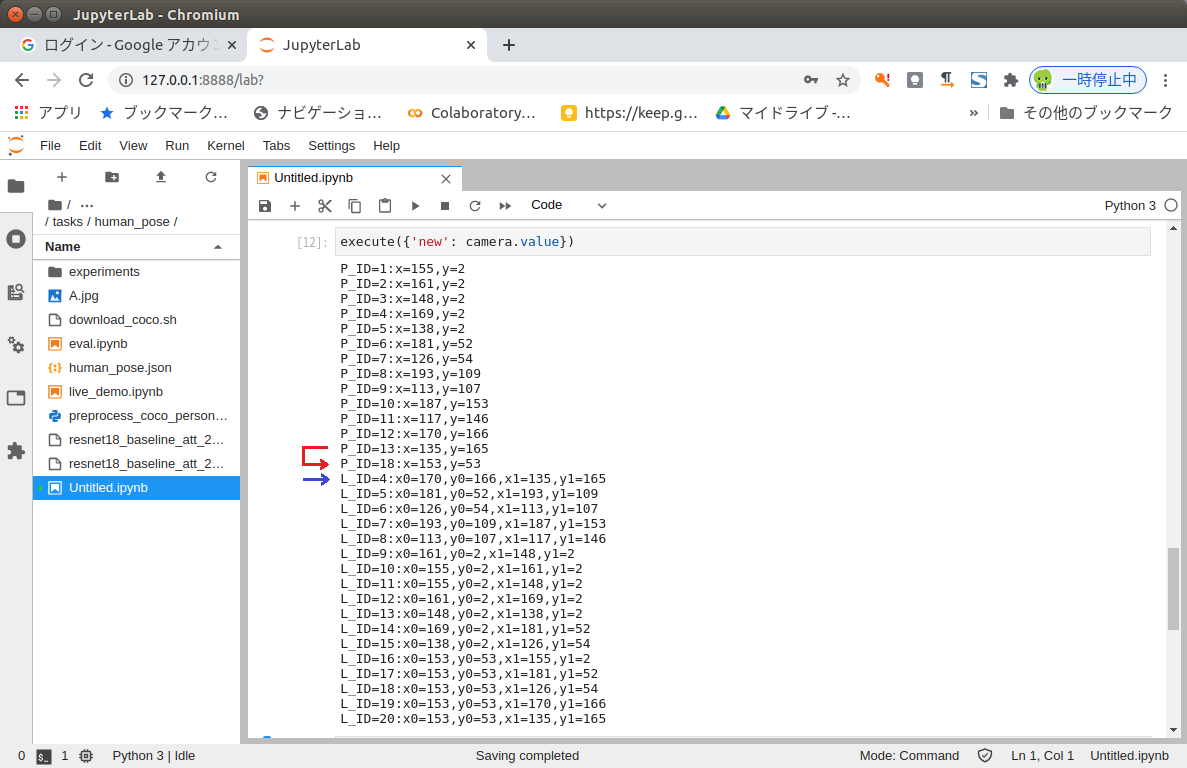
P_IDはkeypoints、L_IDはskeletoの番号に対応しています。
ちなみに、コードの中のcolorの配列の並びはBGRです。

keypointsやskeletonは「human_pose.json」で記述されています。
例えばL_IDが16の線は、nose(1)とneck(18)をつなぐ配列として[18,1]で記述されています。
{"supercategory": "person", "id": 1, "name": "person", "keypoints": ["nose", "left_eye", "right_eye", "left_ear", "right_ear", "left_shoulder", "right_shoulder", "left_elbow", "right_elbow", "left_wrist", "right_wrist", "left_hip", "right_hip", "left_knee", "right_knee", "left_ankle", "right_ankle", "neck"], "skeleton": [[16, 14], [14, 12], [17, 15], [15, 13], [12, 13], [6, 8], [7, 9], [8, 10], [9, 11], [2, 3], [1, 2], [1, 3], [2, 4], [3, 5], [4, 6], [5, 7], [18, 1], [18, 6], [18, 7], [18, 12], [18, 13]]}
例えば、体の真ん中で三角(△)で表示されている部分を四角(□)にする場合は
[18, 12], [18, 13]の配列を[6, 12], [7, 13]に変更します。
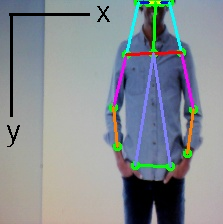
こんな感じになります。姿勢を判断する場合の体の側線が見やすくなります。

線を非表示にする場合
[4, 6], [5, 7]ー> [4, 4], [5, 5]

さらに、これを棒人形にしたければ、keypointsの12と13の座標に中点座標を計算して割り当てて(12と13の代わりの仮想点を置くイメージ?)から描画する、その際circleの描画は止めておき線の幅は4くらいにするようにしておけばいいんじゃないでしょうか(多分….)。
これらのデータをテーブルデータとして再度学習させれば、いろいろな姿勢を「意味」として分類できるんじゃないでしょうか。
このサンプルは転移学習や分類(サンプルではテーブルデータではなく画像を使ってSVMでやってますね)の良い例になっていると思います。
データを使えば、例えば相手プレイヤーがドリブルであなたを抜く時のクセも解析できると思います(^^)。
カメラ画像が反転して表示される場合や画像の保存
def execute()の中で
反転している場合は画像をフリップする(反転しているとポイントやラインの座標位置も反転します)。
こんな感じ。
|
1 2 3 |
image = change['new'] #add image = cv2.flip(image,1) |
画像の保存は最終行に以下を追加、224 x 224 の画像になります。
|
1 |
cv2.imwrite('xxx.jpg',image) |
Appendix
keypointsの座標を名前付きで取得する場合
以下のPythonコードに追加
/work/torch2trt/trt_pose/trt_pose/draw_objects.py
関数の追加
pointsの配列は「human_pose.json」から拝借
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
def points_coordinate(self,object_counts,objects,normalized_peaks,height,width): points = ["nose", "left_eye", "right_eye", "left_ear", "right_ear", "left_shoulder", "right_shoulder", "left_el$ image_idx = 0 if object_counts[image_idx ] > 0: person_idx = 0 for i in range(len(points)): points_type_idx = i points_idx = objects[image_idx, person_idx , points_type_idx ] if points_idx >= 0: part_location = normalized_peaks[image_idx, points_type_idx, points_idx, :] y, x = part_location[0], part_location[1] y_pixels, x_pixels = y * height, x * width print(points[i] + ":x=" + str(round(float(x_pixels))) + ",y=" + str(round(float(y_pixels)))) |
color= (0, 255 ,0)の下あたりに追加
|
1 |
self.points_coordinate(object_counts, objects, normalized_peaks,height,width) |
コンテナ内で再ビルドしてコンテナを再起動
|
1 2 3 |
cd /work/torch2trt/trt_pose python3 setup.py install |
|
1 |
sudo docker start -i my_pose1 |
対応

Appendix2
画像ファイルを読み込んで解析
以下のディレクトリに224 x 224 のjpg画像(test.jpg)を準備
/home/jetson/work-pose/torch2trt/trt_pose/tasks/human_pose
後は、コードを修正するだけです。
1.カメラ設定の箇所
以下だけ実行
|
1 |
from jetcam.utils import bgr8_to_jpeg |
2.実行関数を以下のように書き直す
cv2.flipは2度実行します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
def execute(): #add image = cv2.imread('test.jpg') image = cv2.flip(image,1) data = preprocess(image) cmap, paf = model_trt(data) cmap, paf = cmap.detach().cpu(), paf.detach().cpu() counts, objects, peaks = parse_objects(cmap, paf) draw_objects(image, counts, objects, peaks) image_w.value = bgr8_to_jpeg(image[:, ::-1, :]) image = cv2.flip(image,1) cv2.imwrite('A.jpg',image) |
3.実行
|
1 |
execute() |
Next
ROS 2を使ってみます。
Leave a Reply