
Amazon Web ServiceのAIサービスを使ってみました。
人工知能サービスの一つrekognitionです。
画像の特徴を解析して、ラベルやその信頼度を返してくれます。
広島の厳島神社の鳥居の画像だとこうなります。
何が写っているのかの解析結果です.
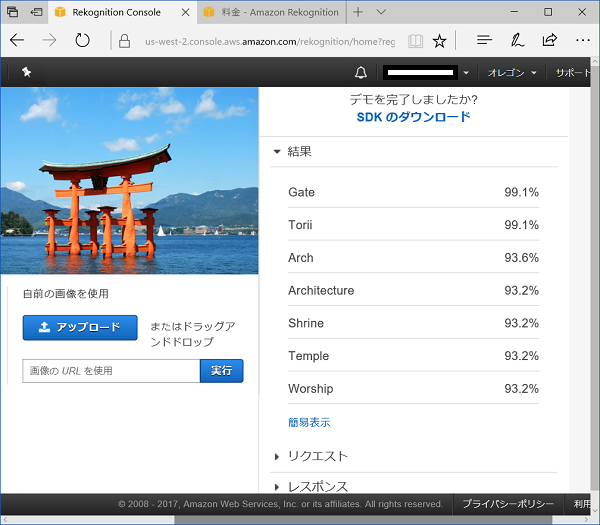
結果の左側で表示されているのがラベル(タグ)です。
現在ラベルは数千種類あって、日々更新されてカタログ化されているそうです。
ユーザーが「こういうラベルを追加してくれない?」というリクエストをだすと、Amazonが「よさげ」と判断すれば深層学習トレーニングをしてカタログに追加してくれます。
問題はこのラベルと信頼スコアをどう使うか…..ですね。
何千枚もある画像から自分の見たいものが写っている画像を抽出する場合。
この場合、以下のことがポイントになるでしょう。
1:英語表記のラベルの日本語化(つまり翻訳)
昨今翻訳のAPIは大概有料です。こんな単語訳程度に有料はつらい。日常使われる英語の普通名詞って6000語程度のようだから単純に日英の対応テーブルで間に合うんじゃなかろうか?
2:ラベルに普通名詞以外にどのくらい固有名詞を使えるのか
(GoogleのLandmark Detectionみたいなやつ)
3:数千のラベルがすべて必要とされるわけではない。目的に応じたラベルの重みづけをどうするか
4:複数のラベルから、写真に何が写っているのか、おおまかにでも推測できるようにしたいが、さて。
単語(語彙)やイディオムをベクトル化することでなんとかならんか?
以上、なんとかしてみようと思います。
1について、何とかしてみました。Githubに単語帳がありました。
3,4については、word2vecとdoc2vecでなんとかなるのか調査中。
工事中(see you soon)
Microsoft AzureのAIだとDescriptionで何が写っているのか結果を返してくれるそうです(まだ使ったことないけど)。
Leave a Reply