
機械学習がどんなものかを学ぶビデオ・レッスンです。
機械学習が何をしようとしているのかをコーディングを通して、教えてくれます。
GoogleのJosh Gordonさんのレッスンでシリーズものになっています。
その5回目
最初の分類器を書こう – 機械学習レシピ5
以下はムービーの説明を補足するヘルプです
下のコードの太字の2行を「自分のコード」で書き換えます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
#import a dataset from sklearn import datasets iris = datasets.load_iris() x = iris.data y = iris.target from sklearn.model_selection import train_test_split x_train,x_test,y_train,y_test = train_test_split(x,y,test_size = .5) <strong>from sklearn.neighbors import KNeighborsClassifier</strong> <strong>my_classifier = KNeighborsClassifier()</strong> my_classifier.fit(x_train,y_train) predictions = my_classifier.predict(x_test) from sklearn.metrics import accuracy_score print(accuracy_score(y_test,predictions)) |
「自分のコード」とは、つまり 「分類器を自分で書いてみる」ということ、で「K近傍法の簡易版」
を書いてみましょう。
【test7.py】
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
<strong>import random</strong> <strong>class ScrappyKNN():</strong> <strong> def fit(self,x_train,y_train):</strong> <strong> self.x_train = x_train</strong> <strong> self.y_train = y_train</strong> <strong> def predict(self,x_test):</strong> <strong> predictions = []</strong> <strong> for row in x_test:</strong> <strong> label = random.choice(self.y_train)</strong> <strong> predictions.append(label)</strong> <strong> return predictions</strong> from sklearn import datasets iris = datasets.load_iris() x = iris.data y = iris.target from sklearn.model_selection import train_test_split x_train,x_test,y_train,y_test = train_test_split(x,y,test_size = .5) <strong>#from sklearn.neighbors import KNeighborsClassifier</strong> <strong>#my_classifier = KNeighborsClassifier()</strong> <strong>my_classifier = ScrappyKNN()</strong> my_classifier.fit(x_train,y_train) predictions = my_classifier.predict(x_test) from sklearn.metrics import accuracy_score print(accuracy_score(y_test,predictions)) |
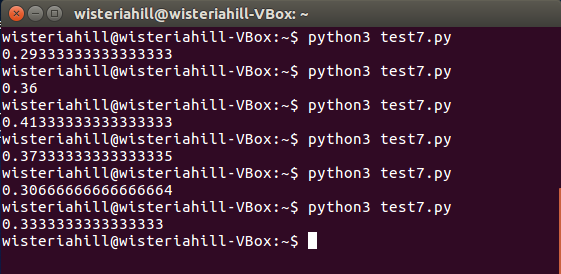
$python3 test7.py
結果
【test8.py】
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
<strong>#import random</strong> <strong>from scipy.spatial import distance def euc(a,b): return distance.euclidean(a,b)</strong> class ScrappyKNN(): def fit(self,x_train,y_train): self.x_train = x_train self.y_train = y_train def predict(self,x_test): predictions = [] for row in x_test: <strong>#label = random.choice(self.y_train)</strong> <strong> label = self.closest(row)</strong> predictions.append(label) return predictions <strong>def closest(self,row): best_dist = euc(row,self.x_train[0]) best_index = 0 for i in range(1,len(self.x_train)): dist = euc(row,self.x_train[i]) if dist < best_dist: best_dist = dist best_index = i return self.y_train[best_index]</strong> from sklearn import datasets iris = datasets.load_iris() x = iris.data y = iris.target from sklearn.model_selection import train_test_split x_train,x_test,y_train,y_test = train_test_split(x,y,test_size = .5) #from sklearn.neighbors import KNeighborsClassifier #my_classifier = KNeighborsClassifier() my_classifier = ScrappyKNN() my_classifier.fit(x_train,y_train) predictions = my_classifier.predict(x_test) from sklearn.metrics import accuracy_score print(accuracy_score(y_test,predictions)) |
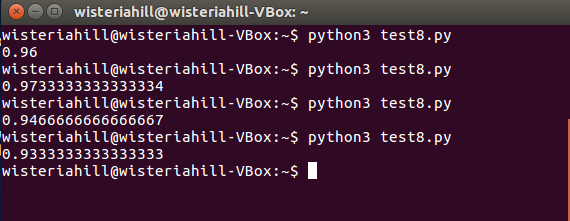
$python3 test8.py
結果
Leave a Reply