
Windowsへインストールしてみます。
Rのアーカイブサイトからダウンロードします。
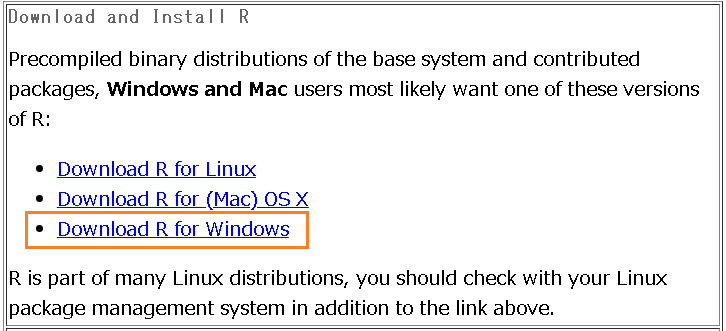

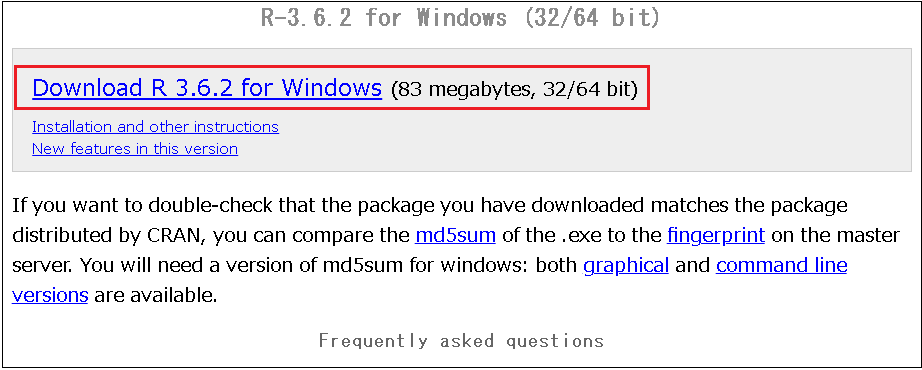
特にダウンロードに関しては問題ないですが、
64bit版Windowsでは以下のように選択しておきます。
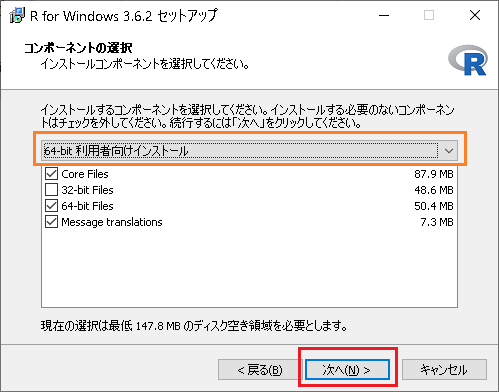
後は、ダウンロードを続行して終了後、インストール。
GIS教材ではiris(アヤメ)のデータはデフォルトで用意されていますが、ここでは外部ファイルとしてハンドリングします。
データはUC Irvine Machine Learning Repository から取得します。
取得したデータには列名がついていないので、ExcelやLibreOffice(Calc)などで読み込んで、カラム名を付けておきます。
Sepal.Length,Sepal.Width,Petal.Length,Petal.Width,Species
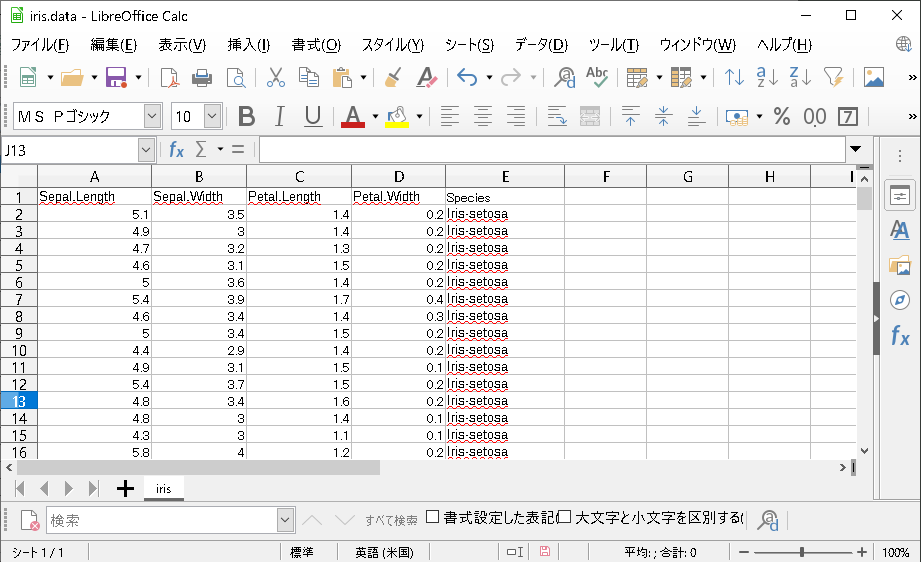
CSV形式で保存。
例:C:¥R¥iris.csv
Rを起動
CSVファイルをフルパスで指定して、読み込みます。
|
1 |
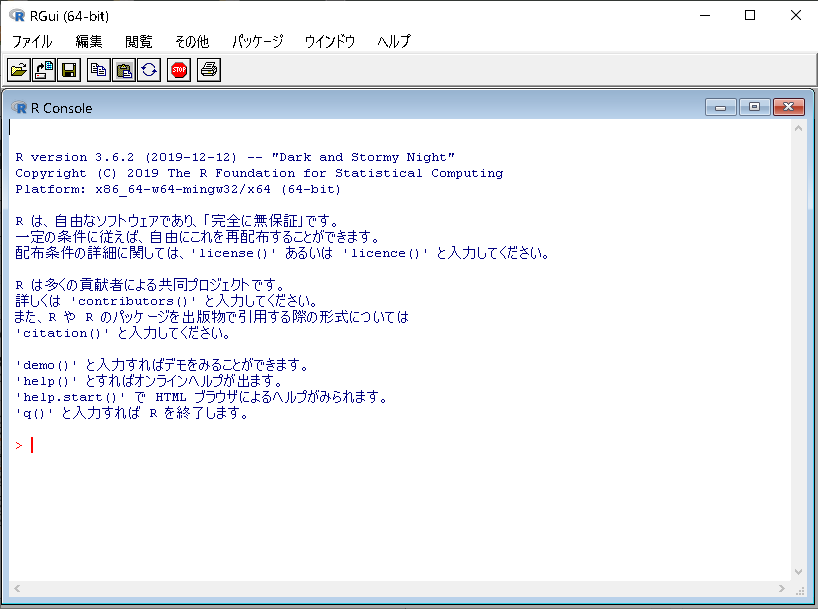
>iris<-read.csv('c://R/iris.csv') |
Rで計算
#irisのヘッダーを確認する。
>head(iris)
#irisのがくの長さの平均値
>mean(iris$Sepal.Length)
#全ての最小値、第一四分位数、中央値、平均値、第三四分位数、最大値
四分位数:データの値を大きさの順に並べたとき、4等分する位置の値
小さい方から順に第一(Q1)、第二(中央値と同じ値、Q2)、第三(Q3)、第四(Q4)となる
>summary(iris)
Rでグラフ作成
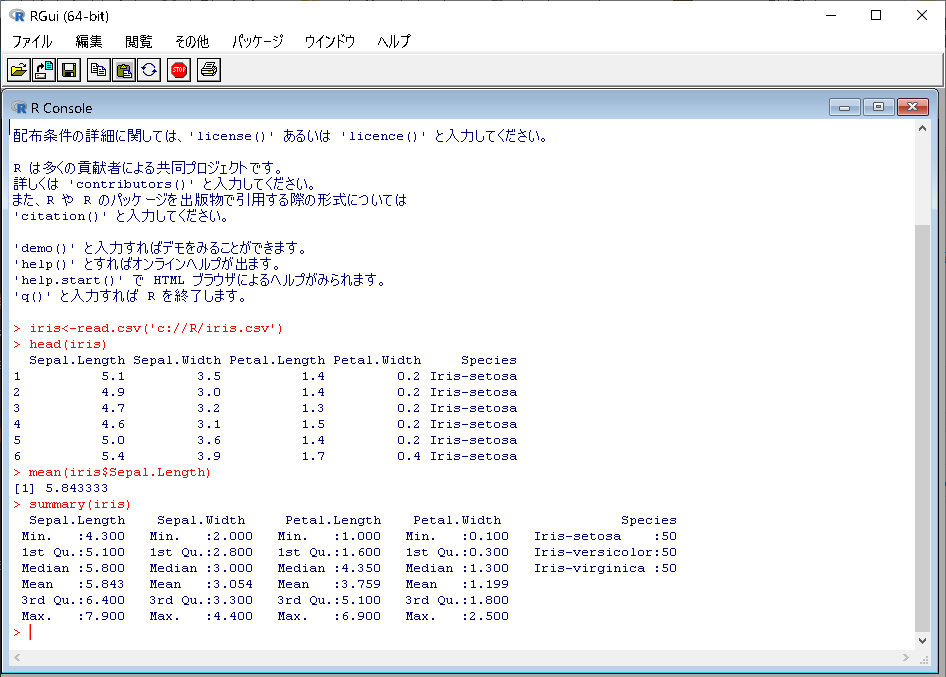
#ヒストグラムを作成
>hist(iris$Sepal.Length)
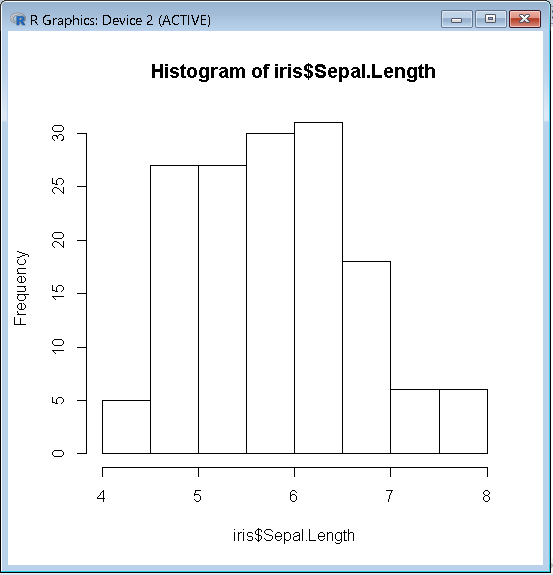
#一変数の散布図
>plot(iris$Sepal.Length)
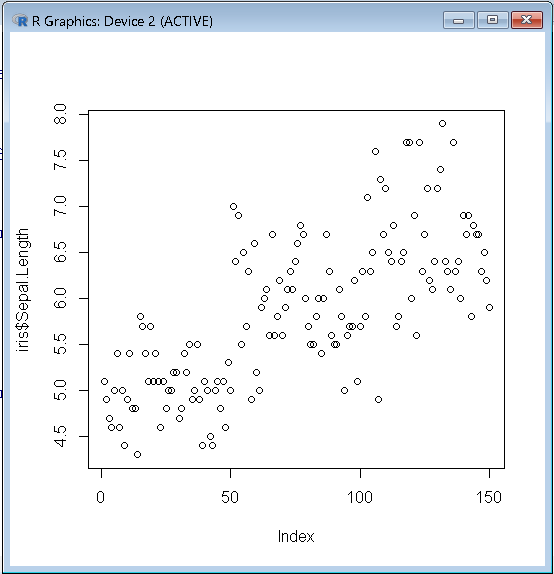
#二変数の散布図
>plot(iris$Sepal.Length,iris$Sepal.Width)
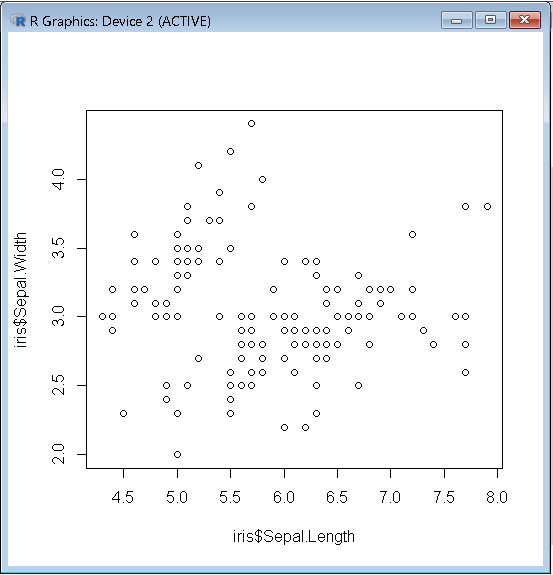
GIS教材でやってること
こういうデータを使っています。
データは14人の学生の英語と数学のテストの採点表です。
やってみます。
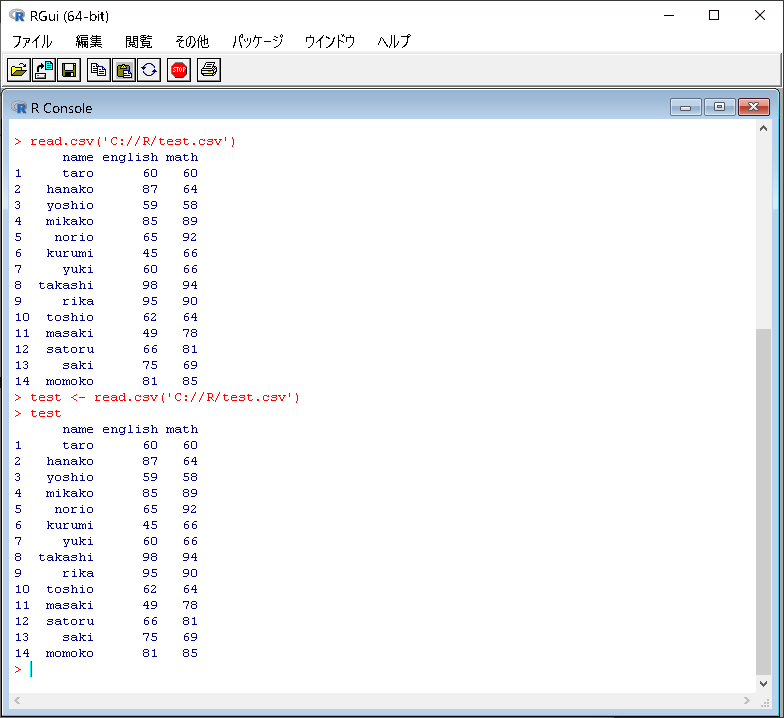
データを読み込んでみます。
|
1 |
>read.csv('C://R/test.csv') |
データセットに読み込んでみます。
|
1 2 |
>test <- read.csv('C://R/test.csv') >test |
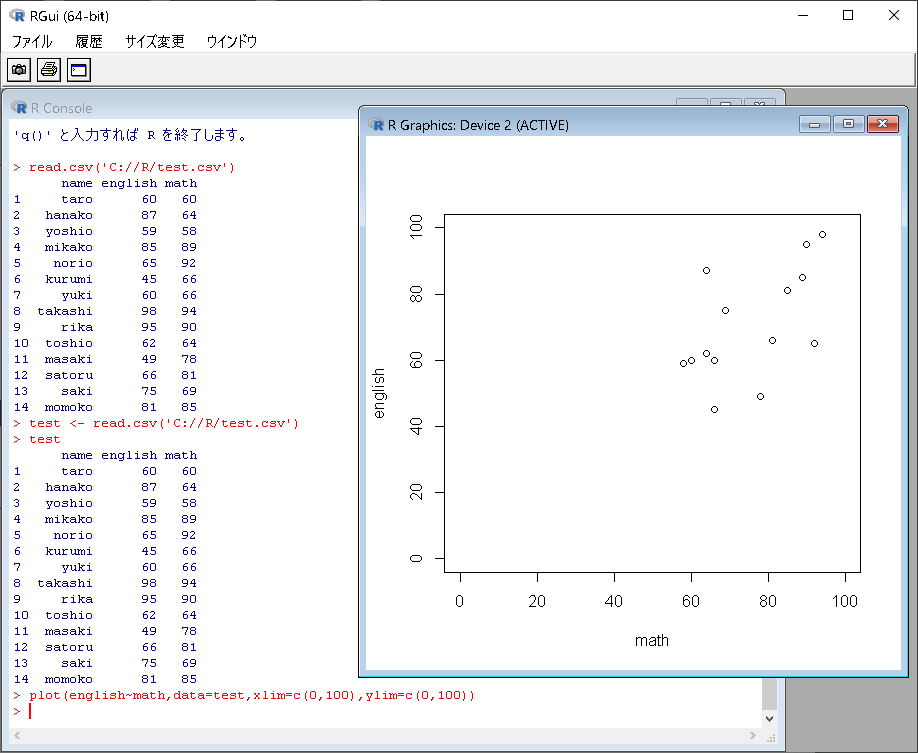
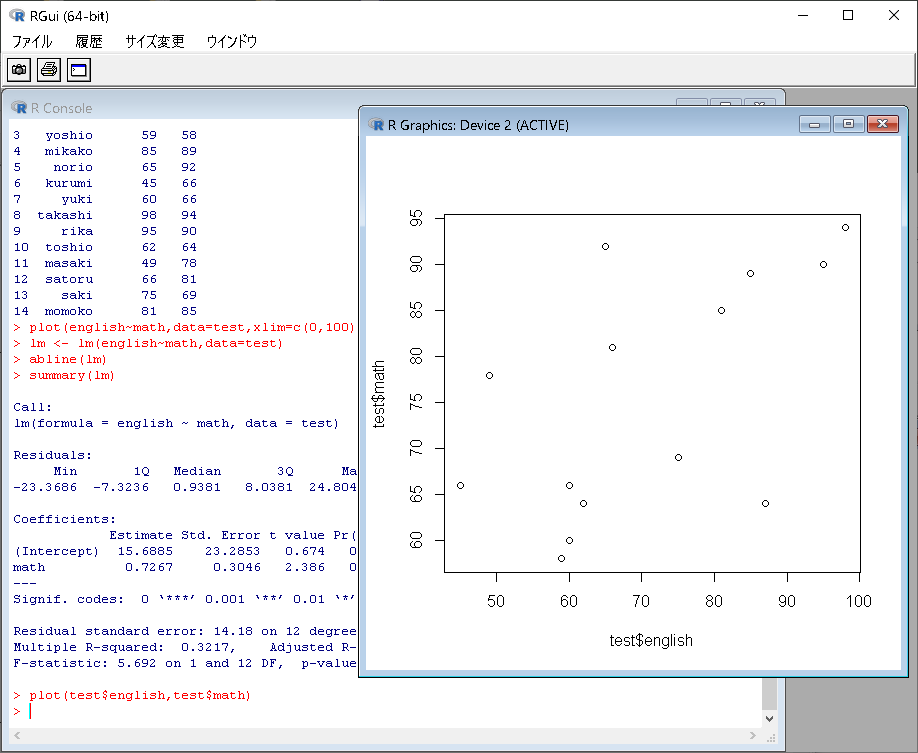
x軸とy軸を指定して、plotを実行
|
1 |
>plot(english~math,data=test,xlim=c(0,100),ylim=c(0,100)) |
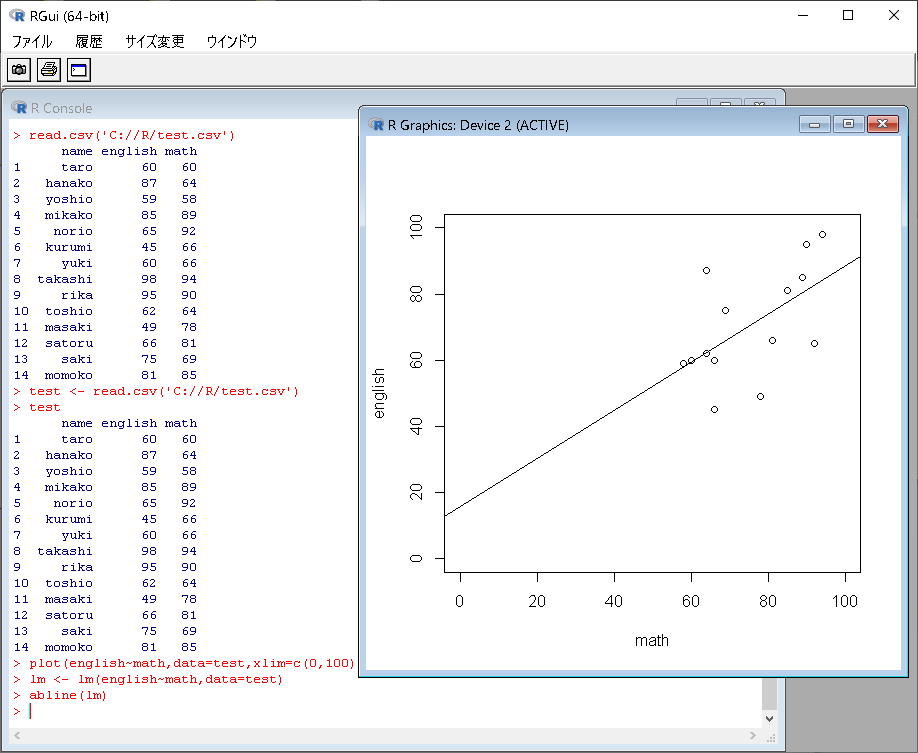
散布図を作成
|
1 2 |
>lm <- lm(english~math,data=test) >abline(lm) |
相関関係があるようには見えないんだけど…….。
サマリーです。
|
1 |
>summary(lm) |

各人の採点の分布をプロット
|
1 |
>plot(test$english,test$math) |
どっちの出来もいいのが4人
どっちかの成績のいいのが5人
どっちの出来も悪いのが5人
といったところ
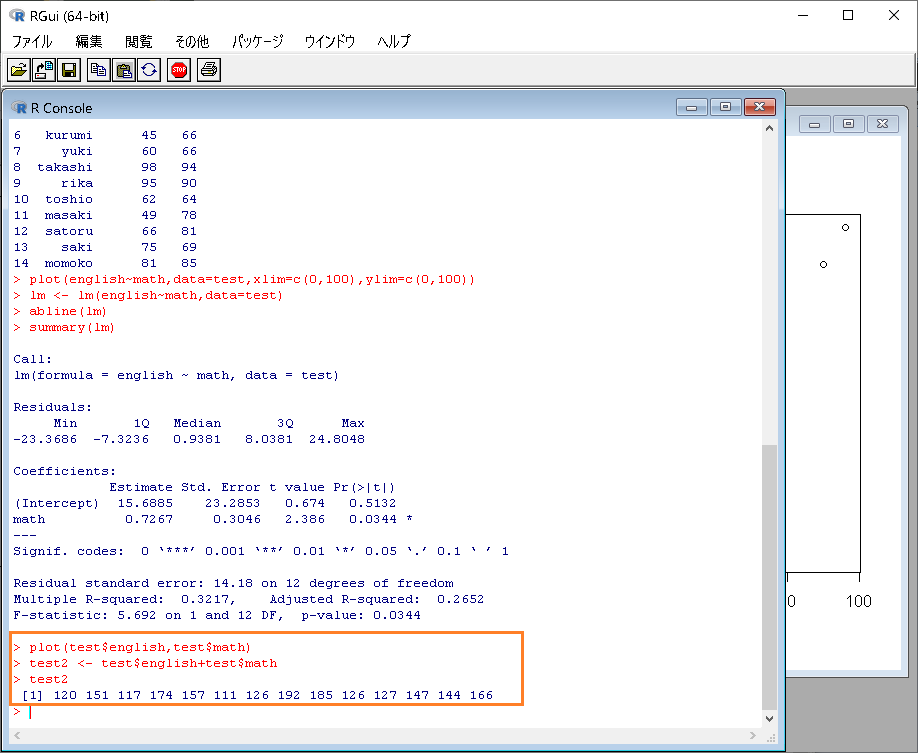
点数の合計を計算
|
1 2 |
>test2 <- test$english+test$math >test2 |
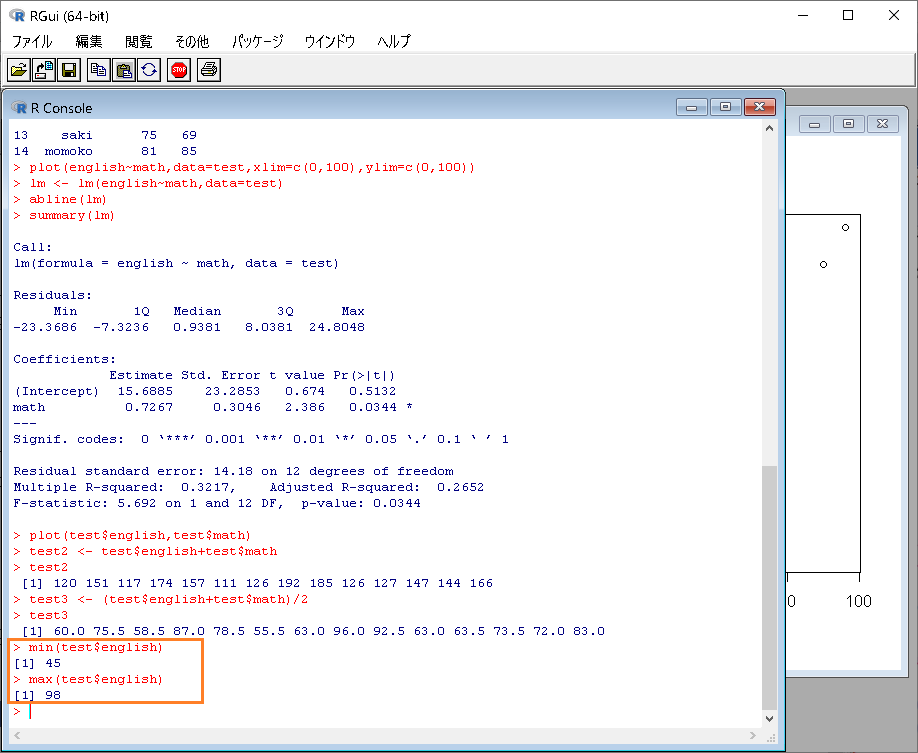
minやmaxで、英語の最低点数や最高点数を求めることができます。
|
1 2 |
>min(test$english) >max(test$english) |
Leave a Reply