
このページではラズパイ3B+で環境構築しています。ラズパイ5Bや4Bでの環境構築については以下を参照
OpenCVとdlib(様々な機能を持っていますが主に機械学習用ライブラリーとして使用)とface_recognitionを使って顔認識してみます。
dlibはバージョン19.0からDeep Learning APIが使えるようになってます。
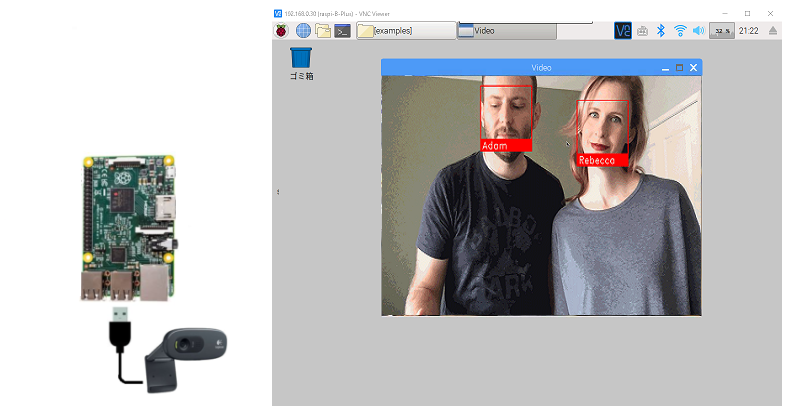
Webカメラを使ってこんなことをやってみます。
インストール
ラズパイ3 Model B+に環境を作ってみました。
OSはRaspbin Stretch、約2~3時間かかりました(^^)。
(現RaspbianはBusterです。Stretchのイメージ->Lite、Full)
【OpenCVをインストール】
|
1 |
sudo apt install python3-opencv |
3.4.0でよろしければこのページの最初の方参照
importには時間がかかります、30秒くらい。

【必須ライブラリをインストール】
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
sudo apt-get update sudo apt-get upgrade sudo apt-get install build-essential sudo apt-get install cmake sudo apt-get install gfortran sudo apt-get install git sudo apt-get install wget sudo apt-get install curl sudo apt-get install graphicsmagick sudo apt-get install libgraphicsmagick1-dev sudo apt-get install libavcodec-dev sudo apt-get install libavformat-dev sudo apt-get install libboost-all-dev sudo apt-get install libgtk2.0-dev sudo apt-get install libjpeg-dev sudo apt-get install liblapack-dev sudo apt-get install libswscale-dev sudo apt-get install pkg-config sudo apt-get install python3-dev sudo apt-get install python3-numpy sudo apt-get install python3-pip sudo apt-get install zip sudo apt-get clean |
【カメラ用ライブラリ(ラズパイ専用カメラモジュールを使う場合)】
|
1 2 |
sudo apt-get install python3-picamera sudo pip3 install --upgrade picamera[array] |
【dlibのコンパイル用にスワップ領域を拡張しておく 】
|
1 |
sudo nano /etc/dphys-swapfile |
CONF_SWAPSIZE=100 -> CONF_SWAPSIZE=1024
|
1 |
sudo /etc/init.d/dphys-swapfile restart |
【dlib v19.9をダウンロードしてインストール】
dlibのコンパイルには時間がかかります。気長に待ちましょう。
dlib の古いバージョンは19.19。
OSイメージBullseye 以降はV19.9を使います。
|
1 2 3 4 5 |
cd /home/pi mkdir -p dlib git clone -b 'v19.9' --single-branch https://github.com/davisking/dlib.git dlib/ cd /home/pi/dlib sudo python3 setup.py install --compiler-flags "-mfpu=neon" |
【face_recognitionをインストール】
このインストールも完了まで気長に待ちます。
|
1 |
sudo pip3 install face_recognition |
【Swapを戻しておく】
|
1 |
sudo nano /etc/dphys-swapfile |
CONF_SWAPSIZE=1024 -> CONF_SWAPSIZE=100
|
1 |
sudo /etc/init.d/dphys-swapfile restart |
【face recognitionコードの examplesをダウンロード】
|
1 2 |
git clone --single-branch https://github.com/ageitgey/face_recognition.git cd ./face_recognition/examples |
以上
やってみます
サンプルの場所
face_recognition/examples
フォルダーにはオバマ元大統領とバイデン元副大統領の画像があります。
ご自分の顔を認識するかテストする場合は自撮りして910×1137のjpeg画像をこのフォルダーに用意しておきます(画像サイズはあまり関係はないようです、鮮明でありさえすれば小さくても可)。
比較的軽いfacerec_from_webcam_faster.pyを使ってみます。
ファイルを開いて、xxxを適当に編集して顔画像を登録します。
xxx_image = face_recognition.load_image_file(“xxx.jpg”)
xxx_face_encoding = face_recognition.face_encodings(xxx_image)[0]
known_face_encodings = [
obama_face_encoding,
xxx_face_encoding
]
known_face_names = [
“Barack Obama”,
“xxx Face”
]
Webカメラを接続してデバイスの番号を確認。
$ls /dev/video*
USBに1台だけ接続している場合は多分こうなっています。
/dev/video0
実行
Videoウィンドウが開くのに少々時間がかかります(約40秒くらいかかりました)。
時間がかかる要因は、face_recognitionモジュールの読み込みと、顔画像のエンコーディングです。
事前にエンコーディングしたデータを用意しておいて、それをハードコードするなり読み込んで実行するなりすれば、face_recognitionモジュールの読み込みの時間だけかかることになるので高速化できます。
実行動作は比較的軽快です。
カメラに6~7%以上の大きさで映り込んだ明るい正面を向いた顔なら識別可能なようです。
|
1 |
python3 facerec_from_webcam_faster.py |
キーボードの「q」キーで終了。
所見
登録さえしておけば認識してくれるようです。
想定される使い方は、登録された複数の顔の内で映っているのは誰?というような使い方です。
登録されていない顔は「Unknown」か、より特徴量の近いものがマッピングされるようです。
肝になる関数がface_recognition.face_distance()
基準になる顔画像との距離が0に近いほど「似てる」ということになって、その顔が採用されるようです。この値は0~1の範囲をとっていて、0.5か0.6以上だと「似てない」となって破棄されるようです。
複数登録してグループ認識
登録数には制限は無いようですが、パフォーマンスはマシンパワーに依存します。
11名登録したら起動に1分50秒かかりました(ラズパイ3Model B+)。
ラズパイなら、2名(カップル)くらいがちょうどいいかも。
注:エンコーディングデータをハードコードして使えば問題なかったです。
なお、OpenCVは日本語フォントを持っていないので英語表記になります。
日本語化は可能のようですが、面倒なのでやめました(^^)。
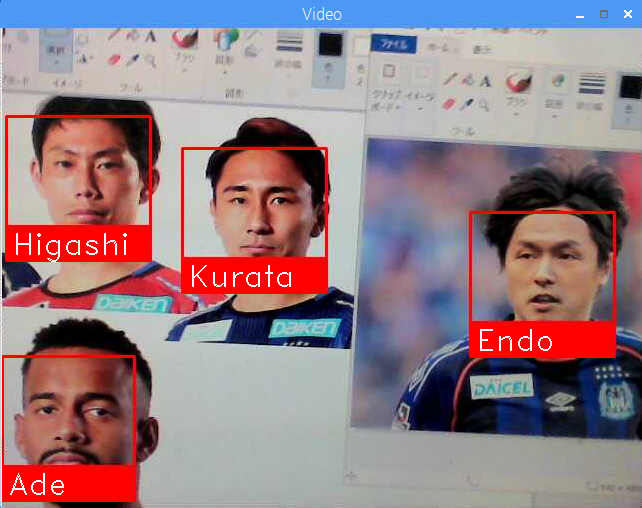
特徴量が類似した場合はUnknownではなく似た画像にマッピングされてしまいます。
つまり、これは個が一意に認識されているわけではなく、他との比較で「より確からしい」と認識されるものが選ばれる点に注意する必要があるかもしれません。登録数が増えれば誤認識の率も高くなります。
OpenCVを日本語化してみました。
こんな感じ。

フォントはこの方のを使用させていただきます。コミック古印体フォント
新規にfontというフォルダーを作ってここにフォント(ttf)ファイルを保存しておきます。
/home/pi/dlib/face_recognition/examples/font/g_comickoin_freeB.ttf
顔画像ファイルはphotoというフォルダーを作って保存しておきます。
このソースをカスタマイズします。
/home/pi/dlib/face_recognition/examples/facerec_from_webcam_faster.py
PILモジュールをインストしておきます(最新のRaspbianなら多分不要)
$sudo pip3 install pillow
カスタマイズします。
【facerec_from_webcam_faster.py】
・
・
・
・
from PIL import ImageFont, ImageDraw, Image
・
・
・
・
#顔画像読み込み
endo3_image = face_recognition.load_image_file(“./photo/endo3.png”)
endo3_face_encoding = face_recognition.face_encodings(endo3_image)[0]
higashi3_image = face_recognition.load_image_file(“./photo/higashi3.png”)
higashi3_face_encoding = face_recognition.face_encodings(higashi3_image)[0]
・
・
known_face_encodings = [
endo3_face_encoding,
higashi3_face_encoding
]
#日本語表記
known_face_names = [
“ヤットさん”,
“東口”
]
・
・
・
・
#クラスを定義しておきます
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
class cv2Ja: def __init__(self): pass @classmethod def putText(cls, cv_image, text, point, font_path, font_size, color=(0,0,0)): font = ImageFont.truetype(font_path, font_size) cv_rgb_image = cv2.cvtColor(cv_image, cv2.COLOR_BGR2RGB) pil_image = Image.fromarray(cv_rgb_image) draw = ImageDraw.Draw(pil_image) draw.text(point, text, fill=color, font=font) cv_rgb_image = np.asarray(pil_image) cv_bgr_image = cv2.cvtColor(cv_rgb_image, cv2.COLOR_RGB2BGR) return cv_bgr_image |
#font定義とputTextを以下のように変更
#font = cv2.FONT_HERSHEY_DUPLEX
#cv2.putText(frame, name, (left + 6, bottom – 6), font, 1.0, (255, 255, 255), 1)
Fontサイズの型はIntegerです(24ポイントのフォントを使ってみます)。
font = ‘./font/g_comickoin_freeB.ttf’
frame = cv2Ja.putText(frame, name, (left + 6, bottom – 24), font, 24, (255, 255, 255))
以上です
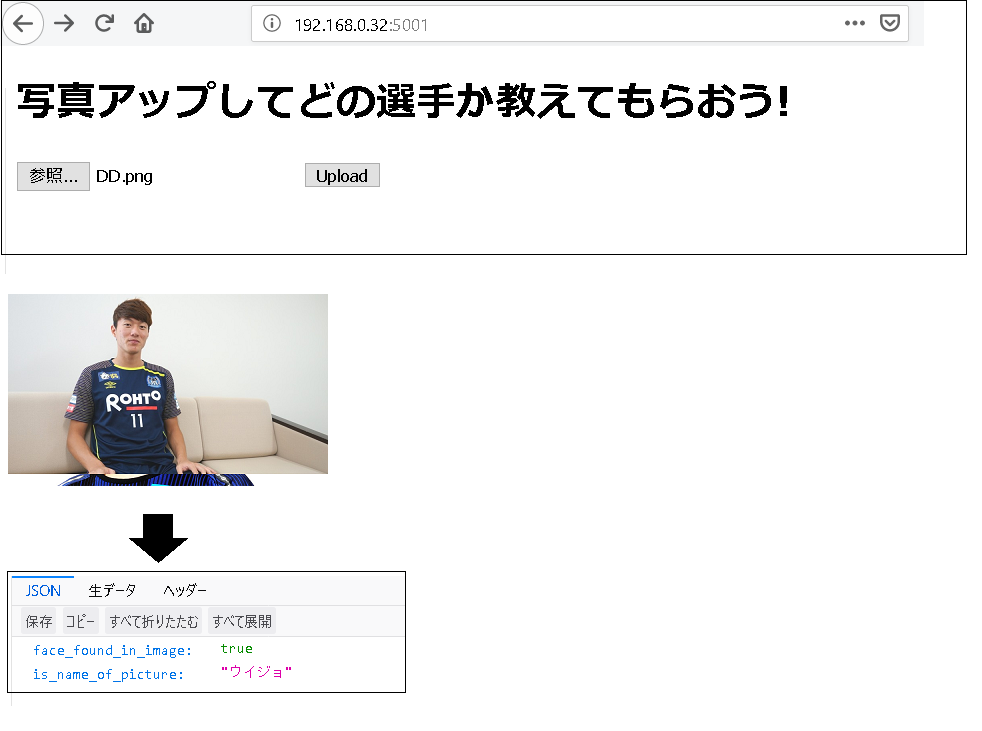
Webサービス版を作ってみました。
web_service_example.pyとfacerec_from_webcam_faster.pyのコードでいけます。
こんな感じ
Next2
グループ内での認識はデータを集めてこういうのでも学習させてみます。
おまけ
幼少時の写真で現在の顔を認識できるのか?
写真はバルサのカンテラ時代の久保建英くん(U-12くらい)

現在(FC-東京 18才)
できました(^^)

でも久保くんは童顔だし、6つしか離れてないし……という方、これでどうでしょう。
高校生の遠藤保仁さん

できました(^^)

人の顔のつくりなんかは18才くらいでもう完成している….とも言えます(^^)。
WisteriaHillはカマタマーレ讃岐のサポでもあります。
データをご用意しました。

Leave a Reply