
データーサイエンス界隈では「統計はR、機械学習はPython」という棲み分けがなされているようです。Rもやっときましょう。
Rのインストールなどはこのページを参照
RStudioを使用します。RStudioはRを快適に利用するための統合開発環境です。
RStudioには様々なバリエーションがありますが、ここではDesktopを使ってみます。
RStudio Desktop の現バージョン1.2.5033では、Rの3.0.1以上を前もってインストールしておきます。
Rstudioの公式サイトからRStudioのDesktop(Free)をダウンロードしてインストールします。
Windows版は64bitのみ対応、32bit版はOlder Versionをインストールすることになります。
RStudioをダウンロードしてインストールしておきます。
RStudioを起動して、空間データを扱うために必要なパッケージ(maptools)を読み込みます。
maptoolsパッケージはソース(tarball)からインストールします。ソースからパッケージをビルドするためRToolsが必要になります。
RToolsをインストールしておきます。
RToolsのインストール先はデフォルト("C:\Rtools")のままとします。これはpackratを使用する際にデフォルト以外のインストール先にRtoolsがインストールされているとRtoolsを起動できなくなってしまう現象を回避するためです……だそうです。
Rのlibraryフォルダーには書き込み許可を与えておきます。
RStudioを起動して以下を実行。
maptoolsとそれに関連したパッケージもインストールしておきます。
|
1 |
>install.packages("maptools" , dependencies =TRUE) |
#ライブラリから、maptoolsパッケージを読み込みます。
|
1 |
>library(maptools) |
データはtokyoを使います。行政区域や人口のポリゴンデータ(tokyo_23_data)、河川のラインデータ(river_9kei)、コンビニの店舗位置のポイントデータ(”cvs_jgd2011_9)です。
ファイルの設置場所は、例えば”C://R/tokyo/”とします。
シェープファイルの情報を確認してみます。
|
1 |
>getinfo.shape("C://R/tokyo/tokyo_23_data.shp") |
#setwd()で作業ディレクトリを設定します。
|
1 |
>setwd("C://R/tokyo") |
ちなみに、作業ディレクトリの確認する場合は
>getwd()
ポイント・ライン・ポリゴンのShapeファイルを読み込む場合
GIS教材では以下のような関数を使います。
|
1 2 3 4 5 |
>conveni <- readShapePoints('cvs_jgd2011_9.shp') >river <- readShapeLines("river_9kei.shp") >area <- readShapePoly("tokyo_23_data.shp") |
実行はできますが「非推奨」の警告が出て、sfパッケージなどを使ってね、と言ってきます。
sf パッケージとは、sp + rgdal + rgeosを置き換えていくものです。
sf パッケージをインストールしておきます。
|
1 |
>install.packages("sf") |
読み込みます。
|
1 |
>library(sf) |
ポイント・ライン・ポリゴンを読み込みます。
|
1 2 3 4 5 |
>conveni <- st_read("cvs_jgd2011_9.shp") >river <- st_read("river_9kei.shp") >area <- st_read("tokyo_23_data.shp") |
プロットして表示してみます。
>plot(conveni)
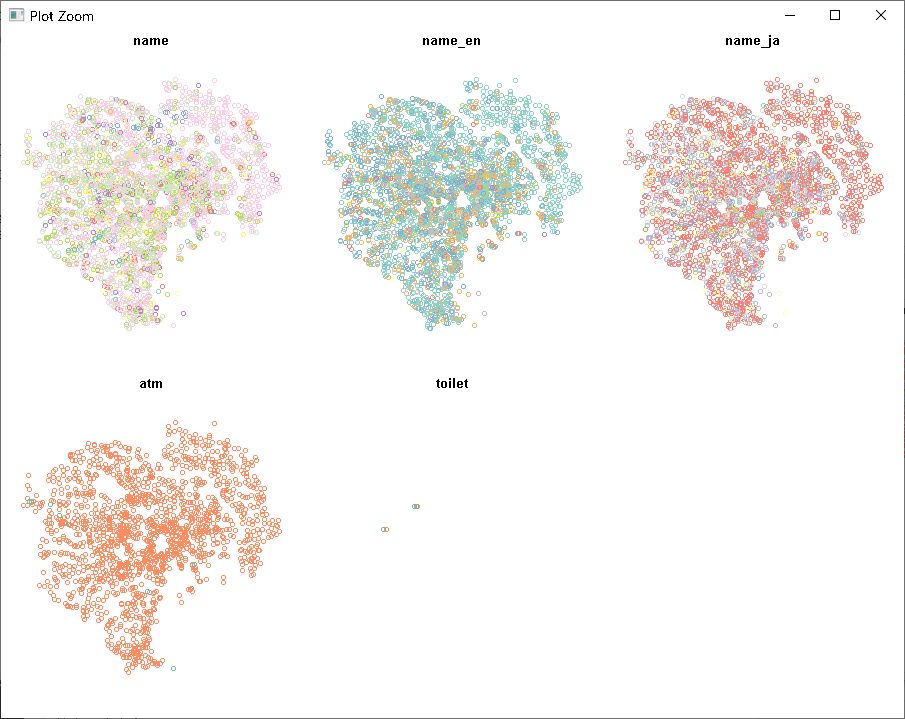
>plot(river)

>plot(area)
人口密度の計算
結果を画像で出力するので、「ggplot2」をインストールしておきます。
|
1 |
>install.packages("ggplot2") |
RStudioを起動して作業ディレクトリを設定し、ライブラリを読み込んでおきます
|
1 2 3 4 |
>setwd("C://R/tokyo") >library(maptools) >library(sf) >library(ggplot2) |
データtokyoのシェープファイルを読み込みます。
|
1 |
>shp <- st_read("tokyo_23_data.shp") |
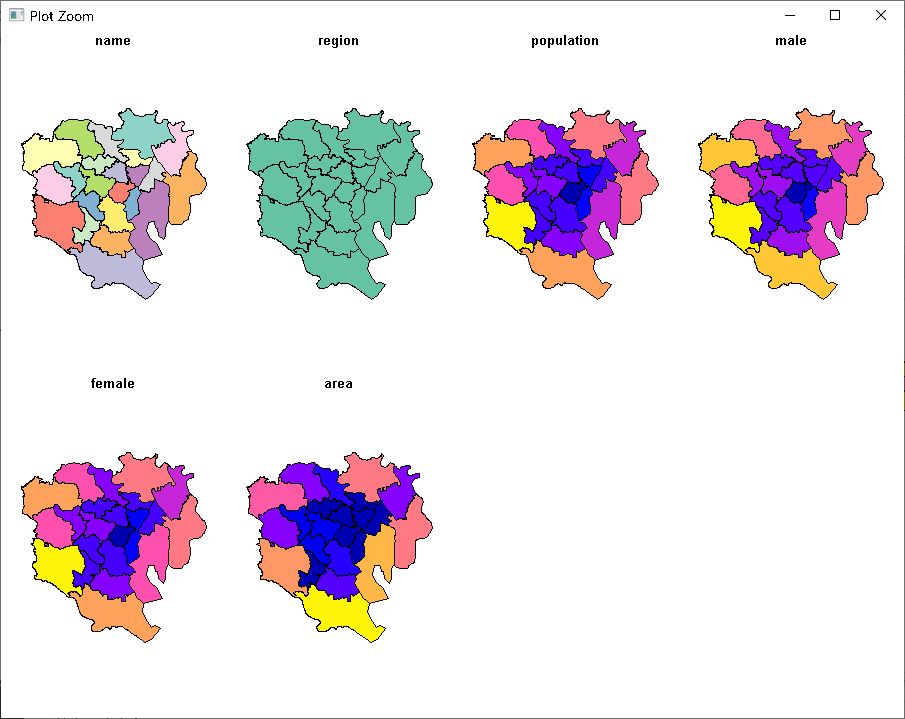
シェープファイルはこんなデータ

必要な項目を取り出しデータフレームにします。
|
1 |
>df <- data.frame(name=shp$name, area=shp$area, population=shp$population) |
人口密度の列を追加、 1平方キロあたりの人口です
|
1 |
>df$populationdensity <- df$population / (df$area / 1000^2) |
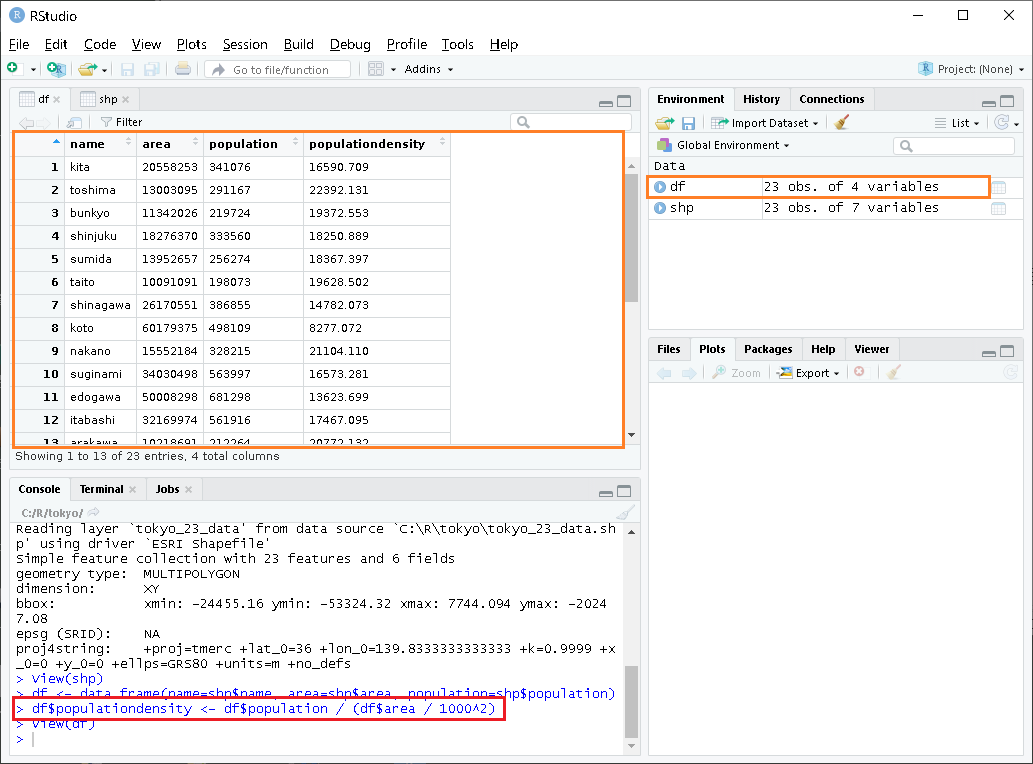
画像ファイル(tokyo-23-population-density.png)に出力してみます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
png("tokyo-23-population-density.png", width=640, height=1280) ggplot(df, aes(x=reorder(name, populationdensity), y=populationdensity)) + geom_bar(stat="identity") + ggtitle("東京23区の人口密度") + ylab("populationdensity (人/㎢)") + theme( plot.title=element_text(size=20), axis.title.x=element_blank(), axis.title.y=element_blank(), axis.text.x=element_text(size=20), axis.text.y=element_text(size=20) ) + geom_text(aes(label=paste(round(populationdensity), "人/㎢"), y=populationdensity-5000), size=5, colour="white") + coord_flip() dev.off() |
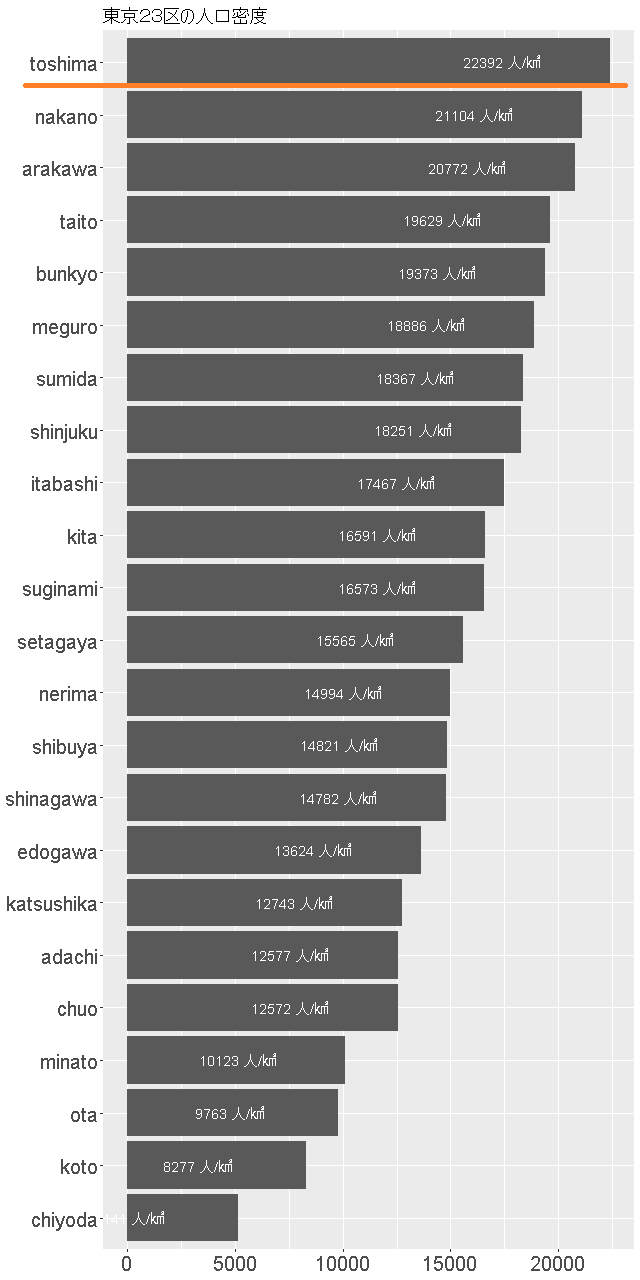
ファイルは作業ディレクトリ(C:\\R\tokyo\tokyo-23-population-density.png)に出力されています。
QGISで見てみます。
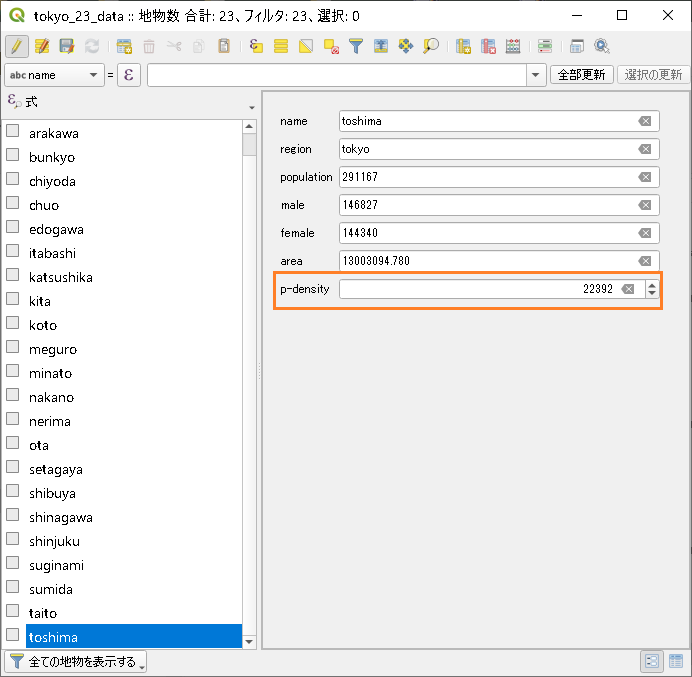
データtokyoのtokyo_23_data.shpを読み込みます。データテーブルには人口(population)と面積(area)のデータフィールドがあります。
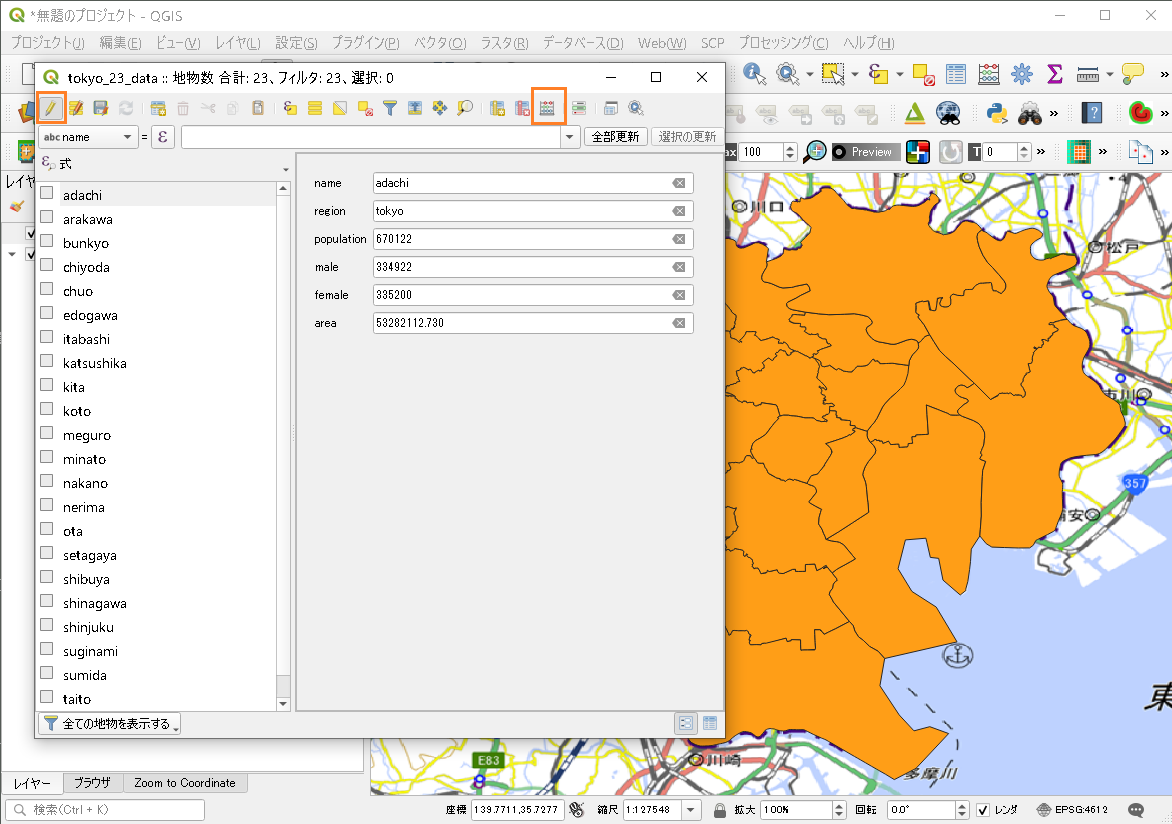
人口密度を「フィールド計算機」で演算して、人口密度フィールド(p-density)を新しく作ります。
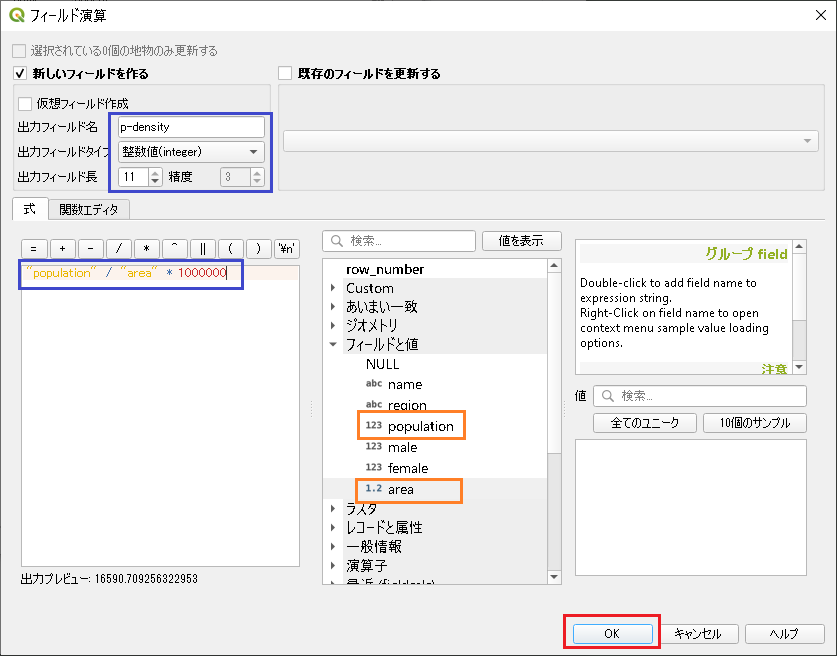
フィールドが追加されます。
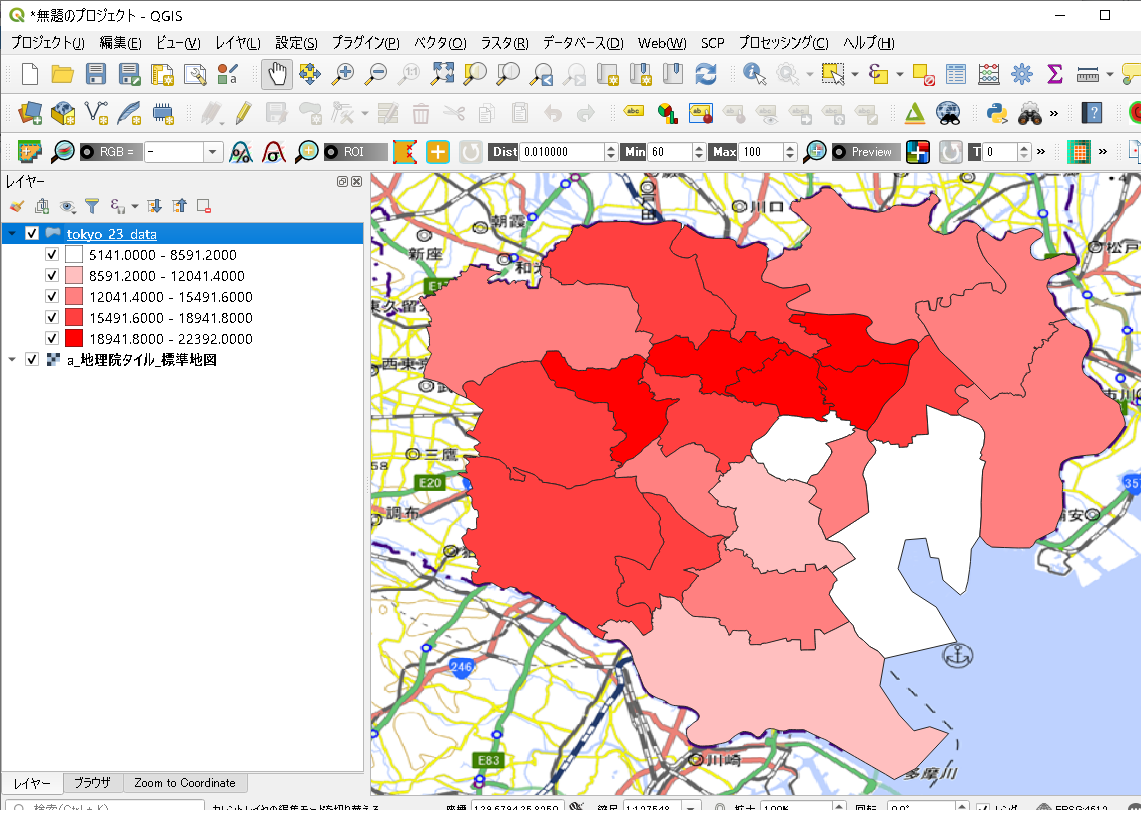
単純に5段階くらいで分類して、人口密度の高いところと低いところをみてみます。
こんな感じ。
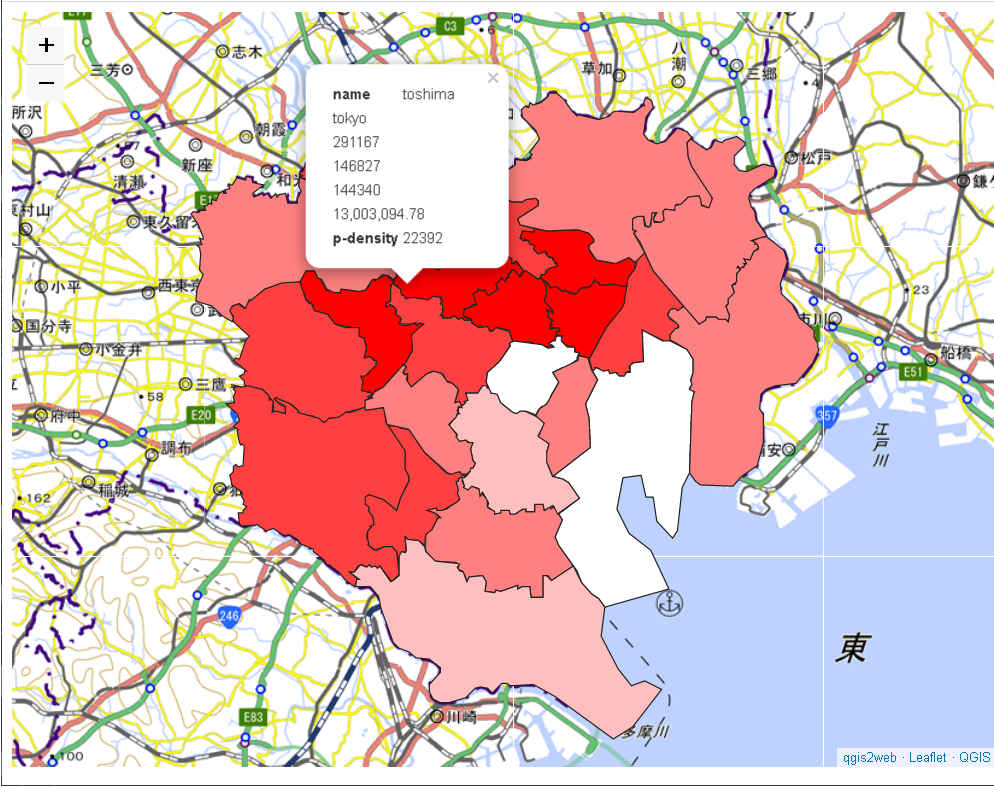
qgis2webプラグインを使ってWebアプリ(Leaflet)で出力すればクリックしてデータを参照できます。
Leave a Reply