
経路探索でしばしば「いらん経路」が混在している場合があります。
例えば「歩道のみ通りたいのに、車道が途中にある」とか…..。
回避してみます。
pgRoutingのデータベース構成ファイルは4つあります。
/usr/share/osm2pgrouting/mapconfig_for_bicycles.xml(自転車)
/usr/share/osm2pgrouting/mapconfig_for_cars.xml(自動車)
/usr/share/osm2pgrouting/mapconfig_for_pedestrian.xml(歩行者)
これら3つがコンプレックスしたもの(完全に含んでいるわけではないようです)
/usr/share/osm2pgrouting/mapconfig.xml
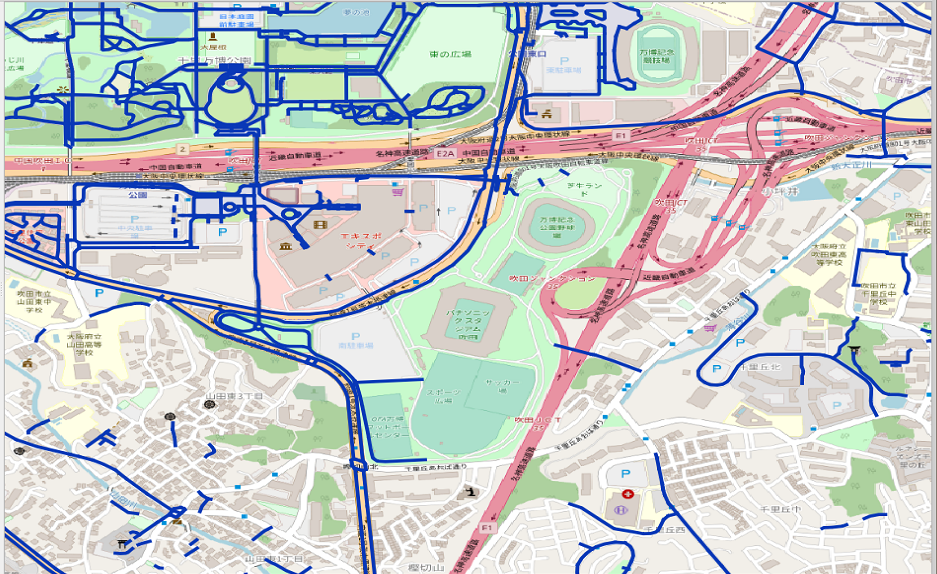
それぞれの道路ネットワークを見てみます(大阪の万博記念公園付近)
mapconfig_for_bicycles.xml(自転車)
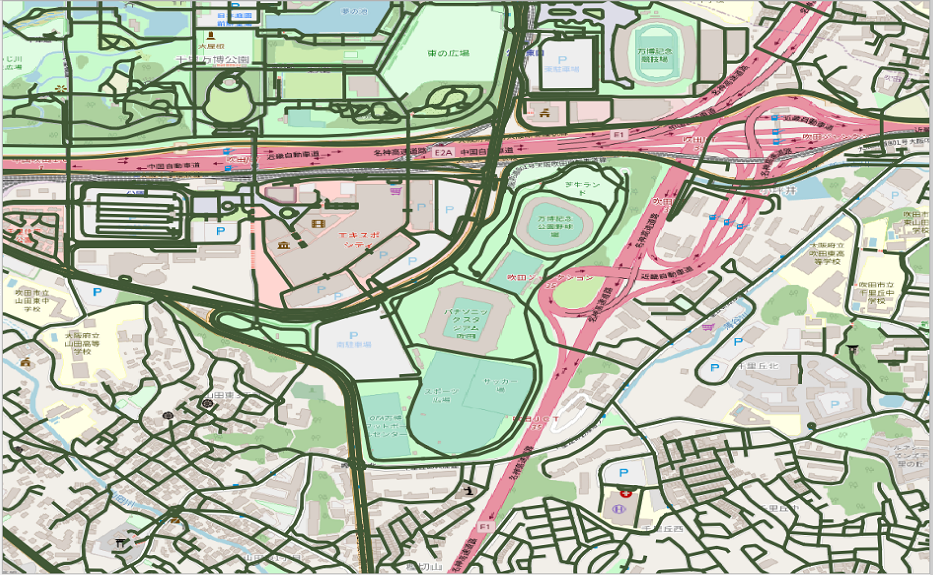
mapconfig_for_cars.xml(自動車)
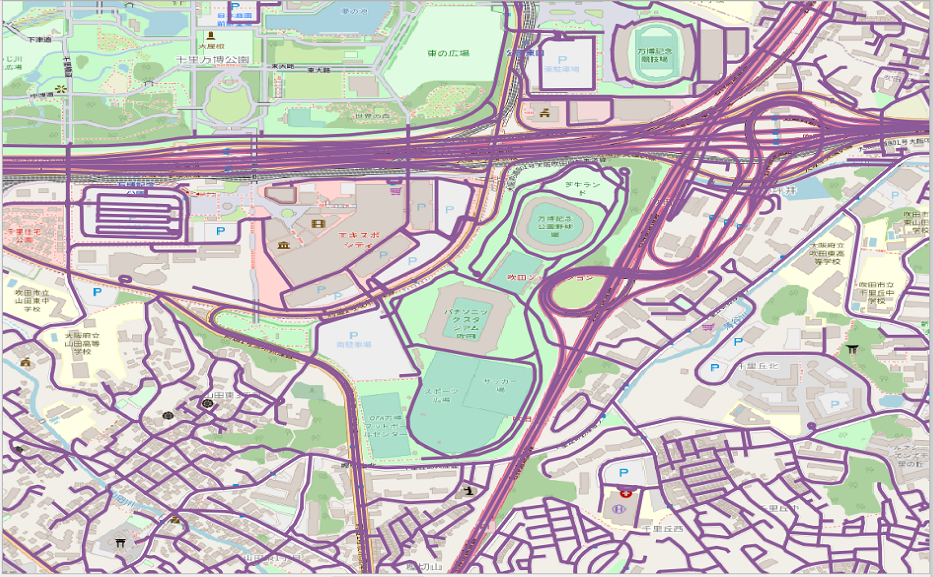
mapconfig_for_pedestrian.xml(歩行者)
mapconfig
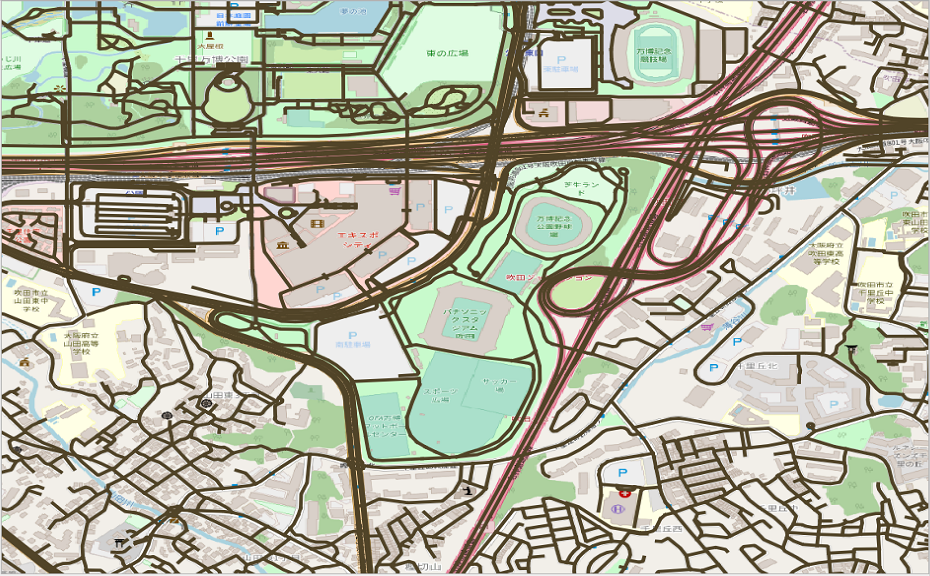
mapconfig.xmlで経路探索した場合、いろいろな道路が複合しているので、普通に「歩道ー>車道ー>歩道」という経路が選ばれることがあります。
「歩いていきたい!」という場合どうしましょう?
歩行者用道路ネットワークを使ってみる?
ところが歩行者用道路ネットワークは結構未整備です。
このネットワークを使って、以下のように赤丸の2点間の最短経路をとってみます。
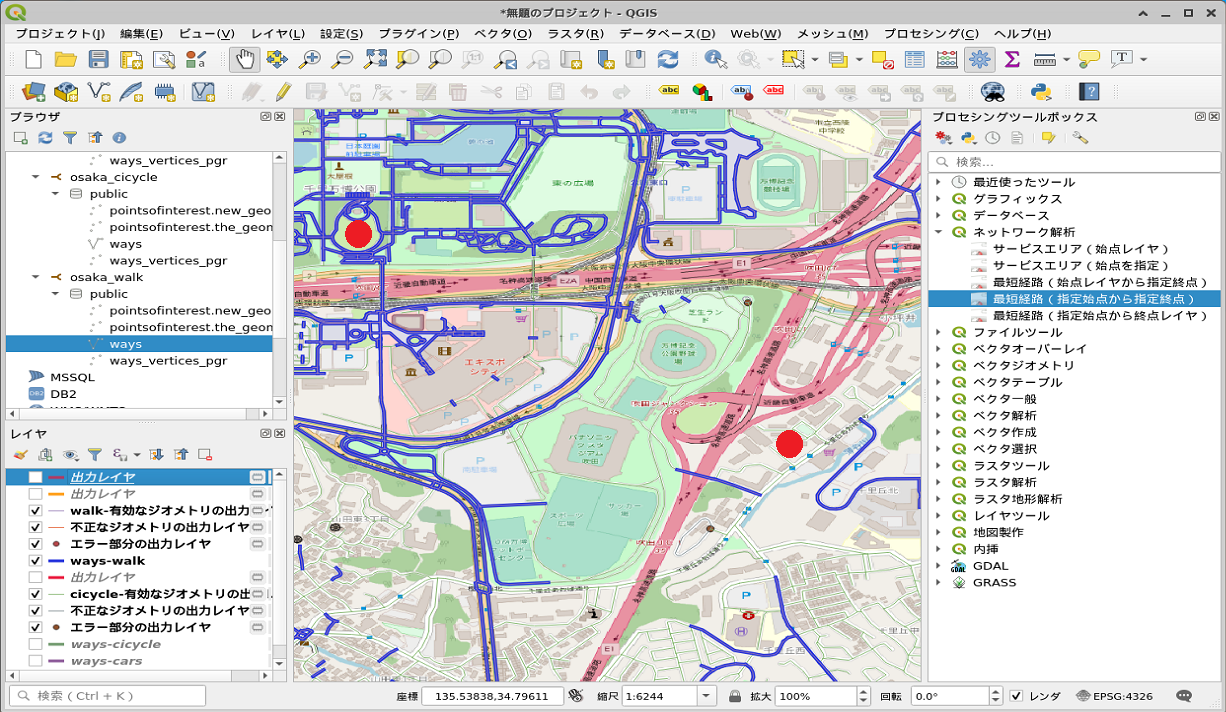
こんな風にネットワークが不連続な場合は経路が探索できませんでした。
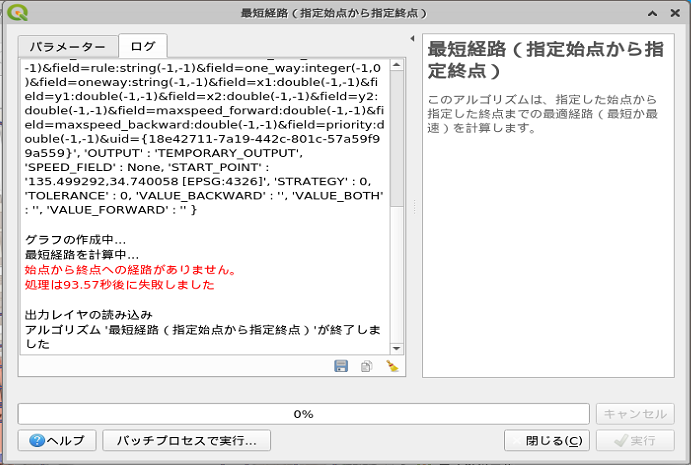
QGISのようにGUIなら「つながっているかどうかは見たら分かる」となりますが、CUIのみの場合のようにデータベースの中身が視認できないと「なんでやねん!」ということになります(~~)。
そこでmapconfig_for_bicycles.xml(自転車)を使ってみます。自転車道なら歩いてもいけるだろう!
経路は探索できました。
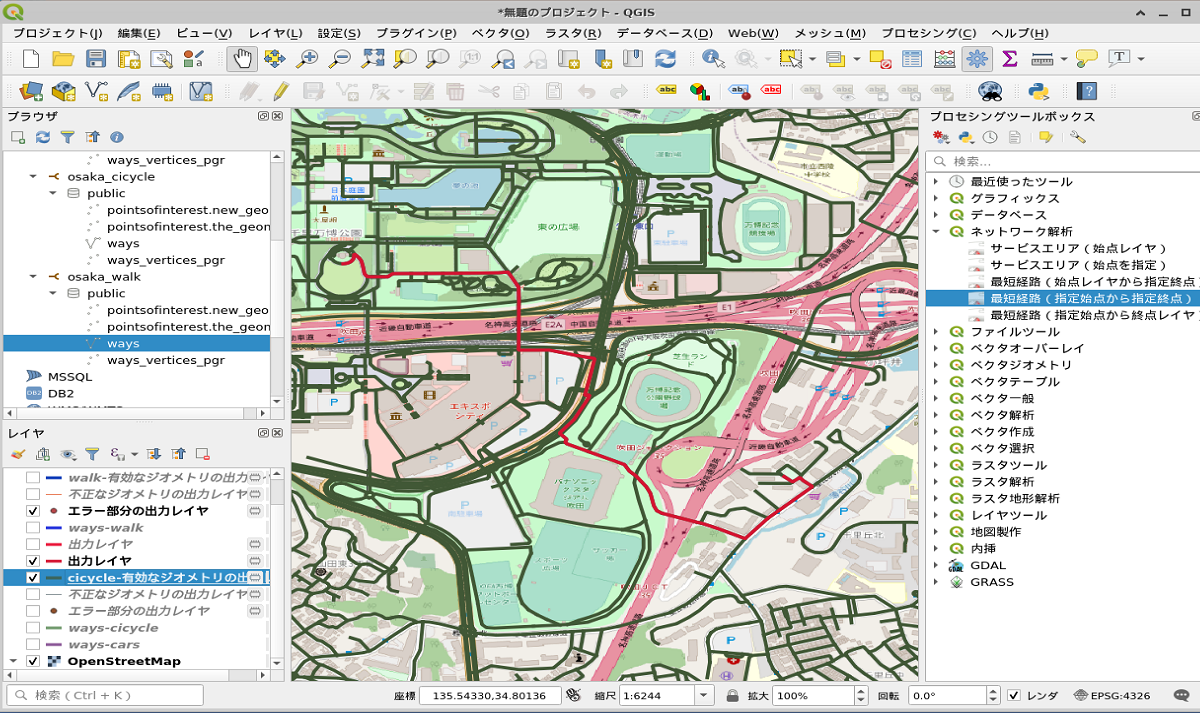
でも、そうは問屋がおろしてくれません。
経路の真ん中あたりを見てみますと車道を通っています。
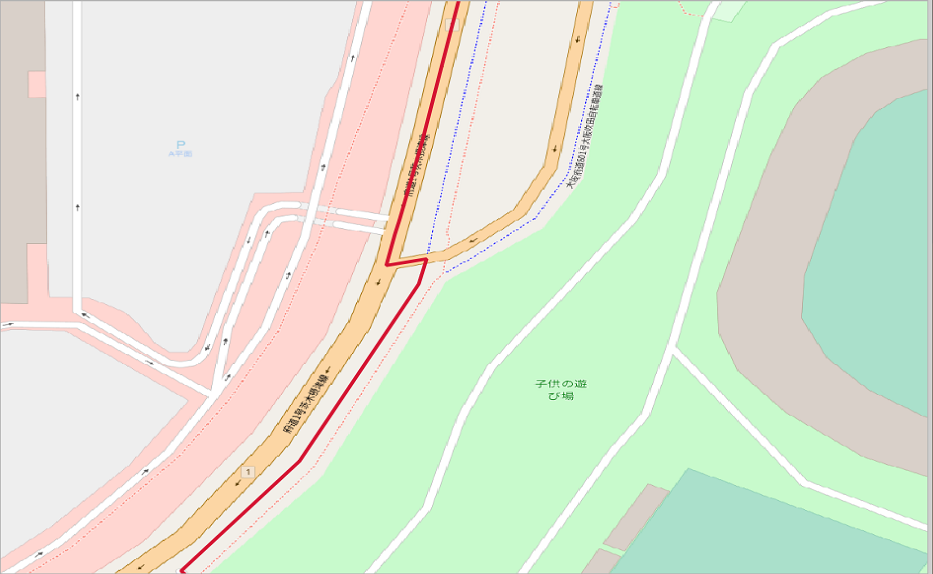
mapconfig_for_bicycles.xml(自転車)って一部車道も含んでいるんですね。知らなかった!
左(車道)、右(自転車道)
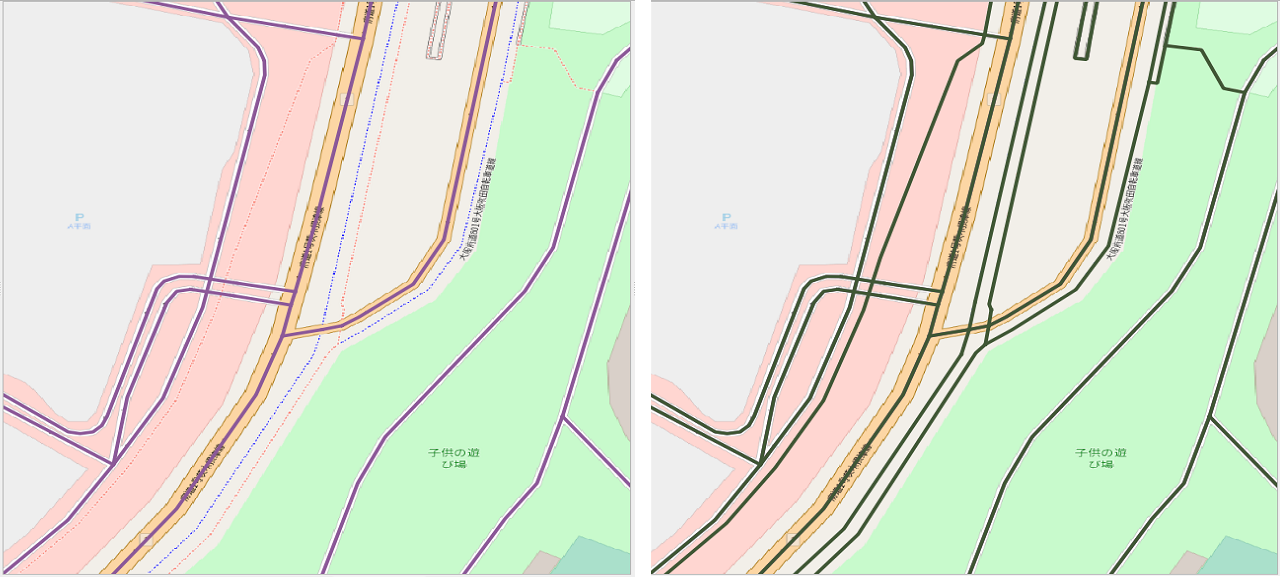
というわけで、徒歩の経路探索する場合はSQLで不要なタグを回避する工夫が必要になりそうです。
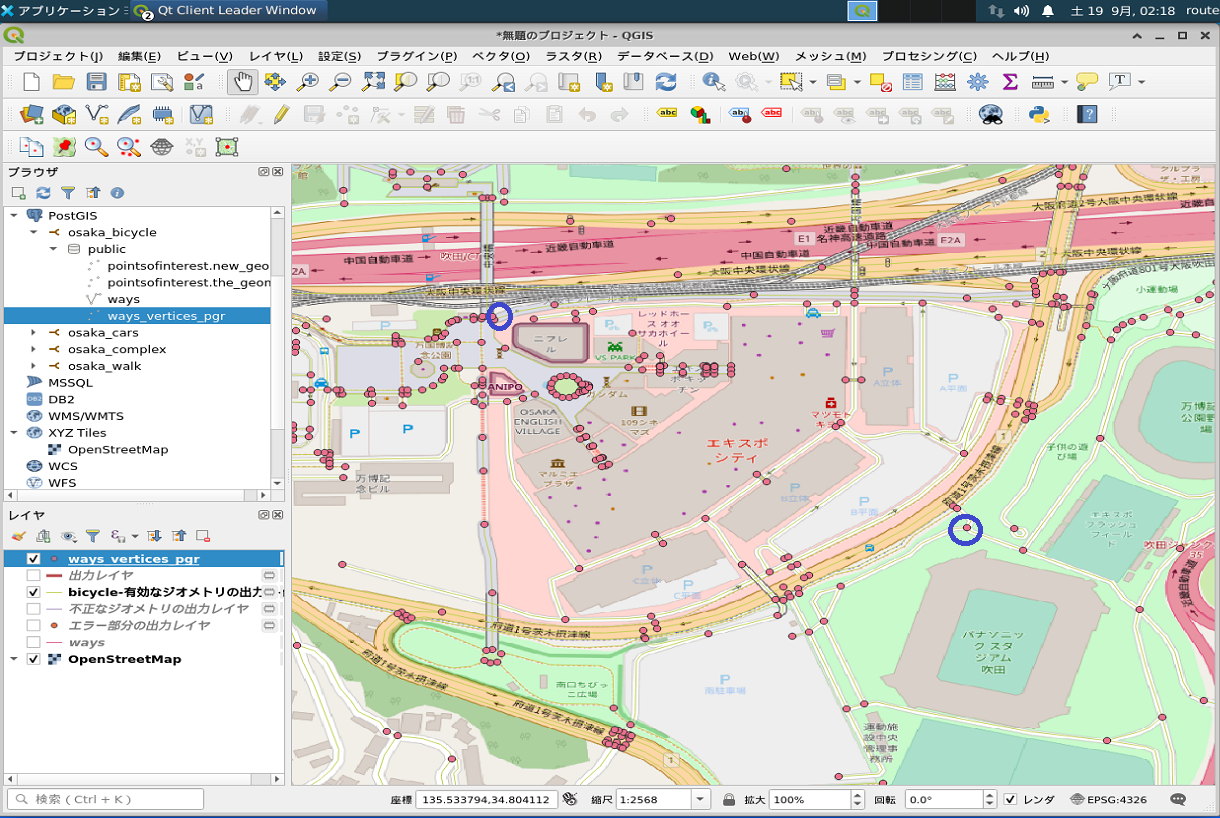
この回避すべき道路のidを調べてみます。
使うデータベースはmapconfig_for_bicycles.xml(自転車)で構成したものです。
QGISで属性テーブルを開きます。
どうもこの517というのが「いらん経路」のタグのidのようです。ご注意

経路の始点・終点のidも同様に属性テーブルで調べてSQLを作ってみます。
これはなんの経路かと言いますと「万博記念公園駅からパナソニックスタジアム吹田に向かう経路」です(^^)。
通常こんなSQL(使っているのはフツーのダイクストラアルゴリズム)
|
1 2 3 4 5 6 7 |
SELECT seq, edge, ST_AsText(b.the_geom) AS "Coordinates" FROM pgr_dijkstra(' SELECT gid as id, source, target, length as cost FROM ways ', 278798, 293210, false ) a INNER JOIN ways b ON (a.edge = b.gid) ORDER BY seq; |
この出力結果から作ったKMLでEarthに描画して見てみます。
車道も通っています。
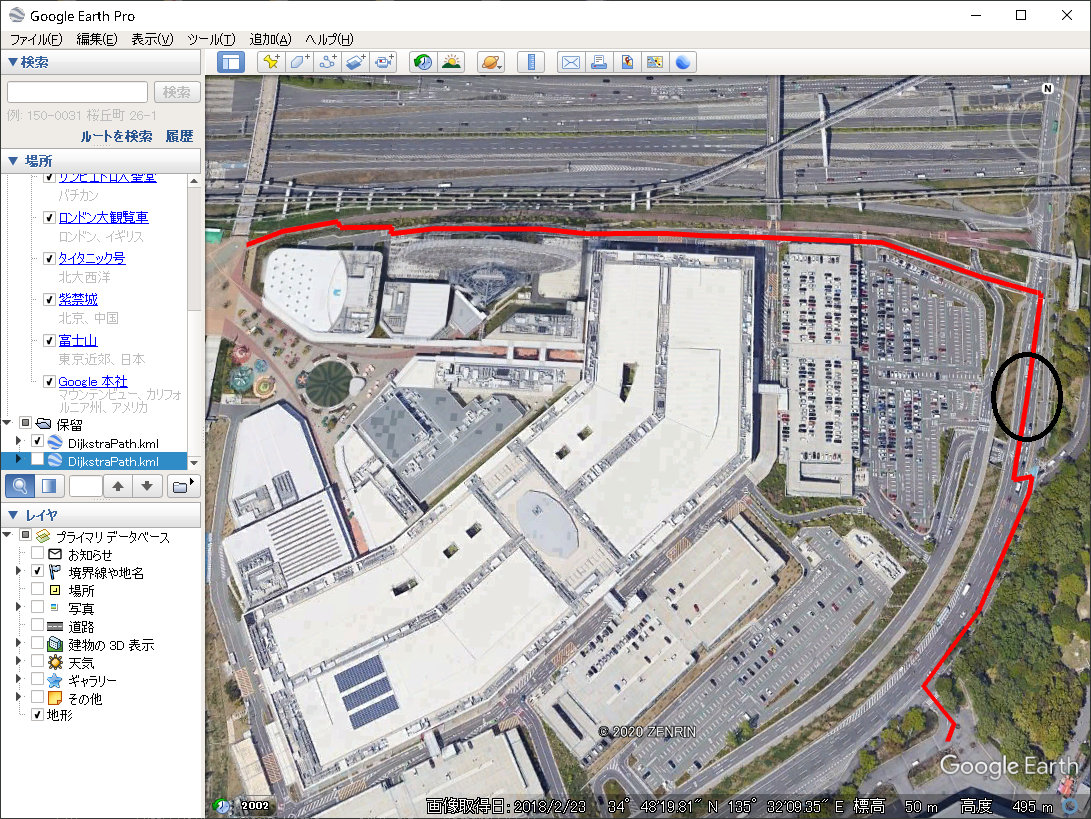
では、「いらん経路」を回避してみます。
|
1 2 3 4 5 6 7 8 |
SELECT seq, edge, ST_AsText(b.the_geom) AS "Coordinates" FROM pgr_dijkstra(' SELECT gid as id, source, target, length as cost FROM ways WHERE tag_id != 517 ', 278798, 293210, false ) a INNER JOIN ways b ON (a.edge = b.gid) ORDER BY seq; |
こんな感じです。右上隅でクチャとなっているのは歩道橋ですね。
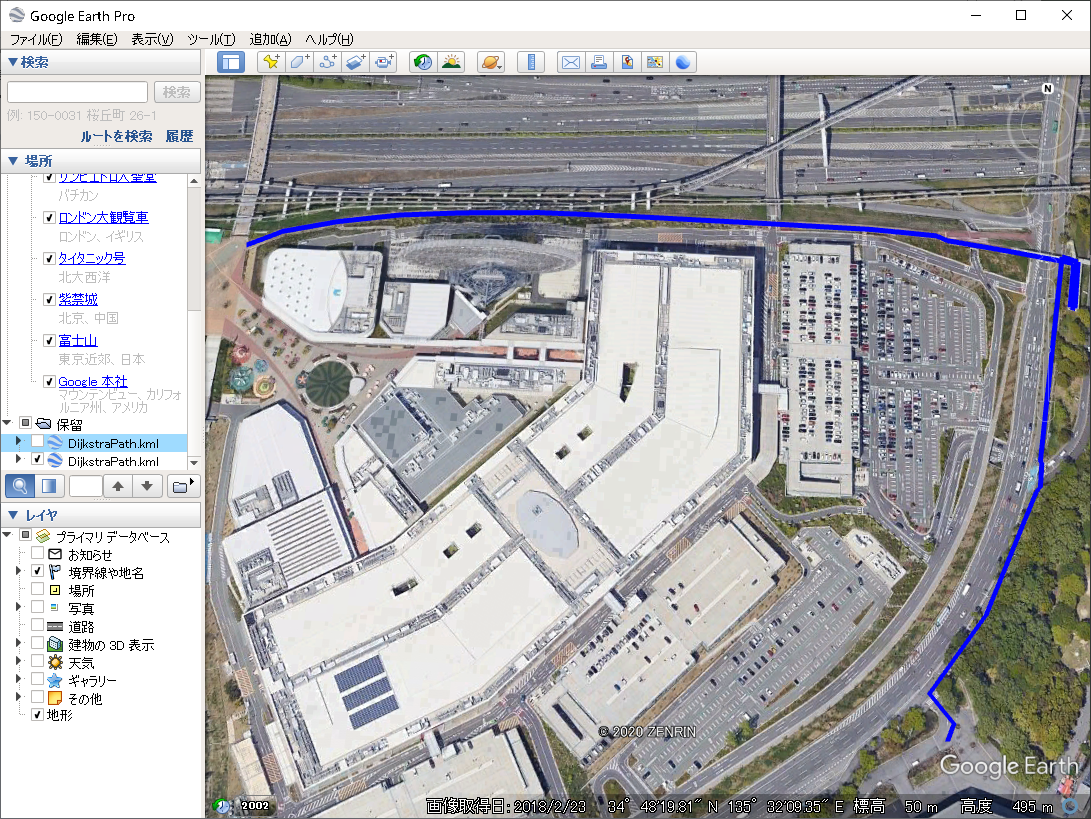
重ねてみた図。
車道を使うより遠回りですが、全部歩いていける経路です。
多くのサポにも、車椅子使用のサポにもお勧めできる最短経路です(ガンバさんはお勧めしてないようですけど…..)。
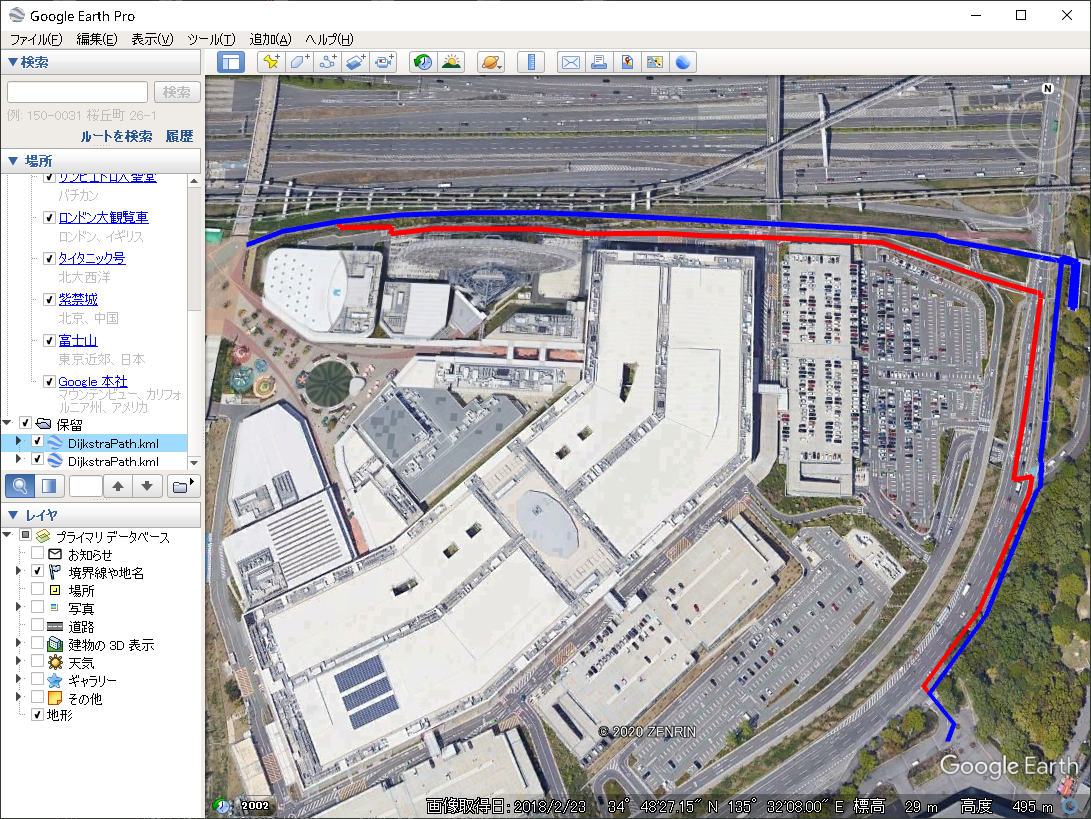
ここでは、mapconfig_for_bicycles.xml(自転車)のみのデータベースでやってみましたが、本来はmapconfig_for_pedestrian.xml(歩行者)も必要なはず。
両方をコンプレックスしたデータベースを再作成して(いつか)やってみる予定。
あるいは、自動車道を使わないXML構成ファイルでデータべースを作ったほうがいいのかな?
より細かく条件付けされた最適経路探索の場合はどうなるでしょう?
SQLも再考してみます。
Appendix1
タグの意味は以下のクエリーで調べることができます。
|
1 |
SELECT tag_id, tag_key, tag_value FROM configuration ORDER BY tag_id; |
ちょっと分かりづらいです。

OpenStreetMapというプロジェクトはどうも「地球上にあるすべての地物にタグ付けしよう」ともくろんでいるようですが、日本では使わんだろうというものも含まれているようです。
OpenStreetMapに歩行者道路をマッピングする時の資料
SQLやKMLの作成とか、pgRoutingとかその他いろいろ
ラズパイ(Ubuntu 20.04.1 LTS Server)でpgRoutingを使って経路探索
ご注意
517というtag_idはmapconfig_for_bicycles.xmlで使われているものです。
tag_valueがhighway=primaryという分類のもので、これがmapconfig.xmlの場合は106になります。
Appendix1の出力もmapconfig_for_bicycles.xmlのもので、mapconfig.xmlの場合は異なっています。
tag_idはxml内で定義されていますが、IDに関してはユーザーが再定義してもいいようです。
従って、xmlを結合する場合は、タグをコンバインした後にIDを振り直せばよろしいということになります。
おまけ
このページで使ったSQLの始点(278798)・終点(293210)はways_vertices_pgrテーブルのidを使っています。
|
1 2 3 4 5 6 7 8 |
SELECT seq, edge, ST_AsText(b.the_geom) AS "Coordinates" FROM pgr_dijkstra(' SELECT gid as id, source, target, length as cost FROM ways WHERE tag_id != 517 ', 278798, 293210, false ) a INNER JOIN ways b ON (a.edge = b.gid) ORDER BY seq; |
このidの代わりにosm_idを使ってみます。
自動生成された id の代わりに osm_id を使用する利点は、異なるデータベース間でも、 それらが共通の osm_id を共有している場合は結果に一貫性が得られることです……だそうです。
ただし、pgRouting の全ての関数は、 bigint 型を使用できるよう変更されていませんので、 osm_id を全ての関数で使用できるとは限りません。
idに対応するosm_idを調べてみます。
SELECT id, osm_id FROM ways_vertices_pgr where id IN(278798, 293210);

osm_idを使ったSQLは以下のようになります。
|
1 2 3 4 5 6 7 8 |
SELECT seq, edge, ST_AsText(b.the_geom) AS "Coordinates" FROM pgr_dijkstra(' SELECT gid as id, source_osm AS source, target_osm AS target, length as cost FROM ways WHERE tag_id != 517 ', 6267537650, 4559428771, false ) a INNER JOIN ways b ON (a.edge = b.gid) ORDER BY seq; |
Memo
cost = w1a1 + w2a2 + ・・・・ + wnan + b
AIと協働するならこういうところですか?SNSなどのビッグデータから得られる渋滞情報などの説明変数が都度データベース内の道路情報のコストに反映され経路が再設定される感じ?
あるいは条件付けは別テーブルにしたほうがいいのか?
e.g. 6.1. Routing for Vehicles (pgRouting Workshop)
Leave a Reply