
Kaggle のコンペで使われているGoogle Research Football Environment(GRF) って、何?
こういうことだそうです。
Google football environment — installation and Training RL agent using A3C
の抄訳です(ほぼほぼ全部ですけど)。
Google football environment — A3Cを使用したRLエージェントのインストールとトレーニング

Frame from google football environment
Google brain team released an open source football environment for the purpose of reinforcement learning research some days back. They have provided the code base(GitHub) and also their research paper on it.
Google Brainチームは、数日前に強化学習研究を目的としたオープンソースのサッカー環境をリリースしました。 彼らはコードベース(GitHub)とそれに関する研究論文を提供しました。
Understanding the environment(Google football environmentを理解する)
Let’s break down this complex environment and understand its state space representation, action space and other configurations required for successful RL model training-
この複雑な環境を分解して、RLモデルのトレーニングを成功させるために必要な状態空間表現、アクションスペース、およびその他の構成を理解しましょう
State space(状態空間)
This environment supports three types of state representation.
この環境は、3種類の状態表現をサポートしています。
1. Pixels: The representation consists of a 1280×720 RGB image corresponding to the rendered screen.
Note this includes both the scoreboard and a small map(mini map) in the bottom middle part of the frame from which the position of all players can, in principle, be inferred.
1. Pixels: 表現は、レンダリングされた画面に対応する1280×720のRGB画像で構成されます。
これには、スコアボードと、原則としてすべてのプレーヤーの位置を推測できるフレームの中央下部分にある小さなマップ(ミニマップ)の両方が含まれることに注意してください。
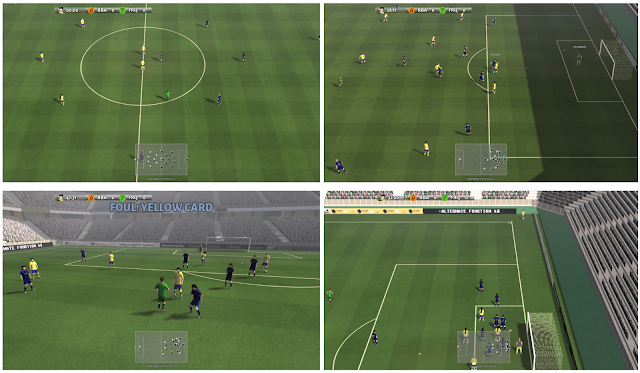
4 frames of dimension 1280 x 720
2. Super Mini Map (SMM): SMM is basically a stack of binary matrices defining the mini map rendered at centre-bottom of the screen. The SMM representation consists of four 96 × 72 matrices encoding information about the home team, the away team, the ball, and the active player respectively.The encoding is binary, representing whether there is a player, ball, or active player in the corresponding coordinate, or not.
2. Super Mini Map (SMM): SMMは基本的に、画面の中央下部にレンダリングされるミニマップを定義するバイナリ行列のスタックです。SMM表現は、ホームチーム、アウェイチーム、ボール、アクティブプレーヤーに関する情報をそれぞれエンコードする4つの96×72マトリックスで構成されます。エンコーディングはバイナリであり、対応する座標にプレーヤー、ボール、またはアクティブなプレーヤーがいるかどうかを表します。
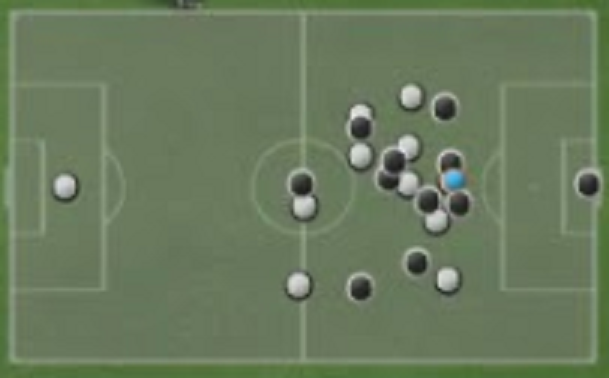
Super Mini Map
3. Floats: The floats representation provides a more compact encoding. It consists of a 115-dimensional vector summarizing many aspects of the game, such as players coordinates, ball possession, and direction, active player, or game mode.
3. Floats: float表現は、よりコンパクトなエンコーディングを提供します。これは、プレーヤーの座標、ボールの所持、方向、アクティブプレーヤー、ゲームモードなど、ゲームの多くの側面を要約した115次元のベクトルで構成されています。
Note — Only pixels and SMM representation can be stacked across multiple consecutive time-steps (for instance, to determine the ball direction).
注 — ピクセルとSMM表現のみが、複数の連続するタイムステップにわたってスタックできます(たとえば、ボールの方向を決定するため)。
Action space(アクションスペース)
The action space of gfootball is quite interesting and quite co-related with the actual football game.
The action is given to the currently active player i.e the player with a blue bar on his head. The environment supports 20 actions.
gfootballのアクションスペースは非常に興味深く、実際のサッカーゲームと非常に関連しています。
アクションは、現在のアクティブなプレーヤー、つまり頭に青いバーがあるプレーヤーに与えられます。 環境は20のアクションをサポートします。
5x4=20
They have already implemented built-in rule-based bot for inactive players that follows actions corresponding to reasonable football actions and strategies, such as running towards the ball when we are not in possession or move forward together with our active player.
彼らはすでに、私たちがポゼションしていないときにボールに向かって走ったり、アクティブなプレーヤーと一緒に前進したりするなど、合理的なサッカーのアクションと戦略に対応するアクションに従う非アクティブなプレーヤー用の組み込みのルールベースのボットを実装しています。
Scenarios(シナリオ)
Google Brain team has provided different scenarios of varying difficulty. Its main goal is to allow researchers to get started on new research ideas quickly, and iterate on them. The easiest scenario for the agent to learn is “empty goal close” in which only one player is standing in front of goal without a goalkeeper.
Google Brainチームは、さまざまな難易度のさまざまなシナリオを提供しています。 その主な目標は、研究者が新しい研究アイデアにすばやく着手し、それらを反復できるようにすることです。 エージェントが学ぶ最も簡単なシナリオは、ゴールキーパーなしで1人のプレーヤーだけがゴールの前に立っている「至近距離にある無人のゴール」です(キーパー無しでPKの練習しているようなもん?)。
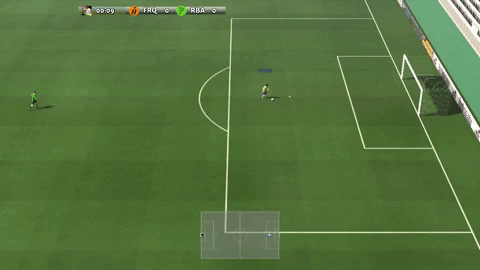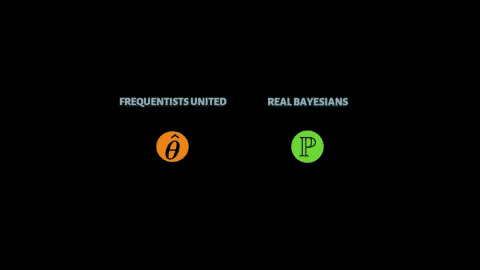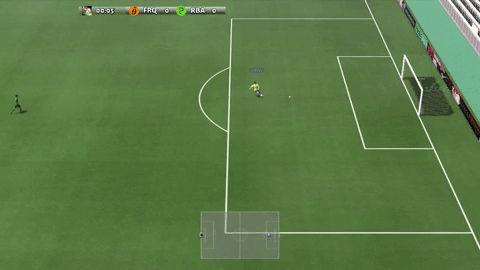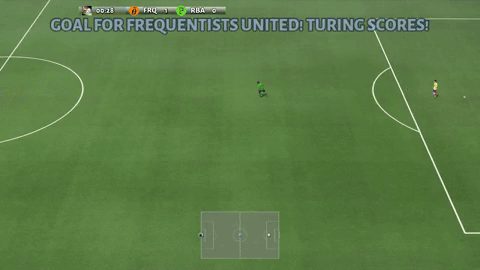
Empty goal close scenario
Installation(インストール)
Let’s start setting this cool environment into our system. We are using system having ubuntu 18.04 operating system and python 3.6. The best and easiest way to install the game engine and the library is by cloning the git repository.
このクールな環境をシステムに設定してみましょう。 私たちはubuntu18.04オペレーティングシステムとpython3.6を備えたシステムを使用しています。 ゲームエンジンとライブラリをインストールする最も簡単な方法は、gitリポジトリのクローンを作成することです。
Note — It is preferable to create a anaconda environment or python virtual environment first and then install dependencies in that environment.
注 — 最初にanaconda環境またはpython仮想環境を作成してから、その環境に依存関係をインストールすることをお勧めします。
|
1 2 3 4 5 6 |
- git clone https://github.com/google-research/football.git - cd football - pip3 install .[tf_cpu] --process-dependency-links Or for gpu version - pip3 install .[tf_gpu] --process-dependency-links - This command can run for a couple of minutes, as it compiles the C++ environment in the background. |
After installation, you can test your installation by running this file environment_test.py from our GitHub repository.
インストール後、GitHubリポジトリからこのファイルenvironment_test.pyを実行して、インストールをテストできます。
|
1 2 3 4 |
- git clone https://github.com/Ujwal2910/Deep-RL-on-Gfootabll-Google-football-OpenAI-style-environment.git - cd Deep-RL-on-Gfootabll-Google-football-OpenAI-style-environment/ - cd enviornment_render/ - python3 environment_test.py |
It will continuously render the frames:
フレームを継続的にレンダリングします。
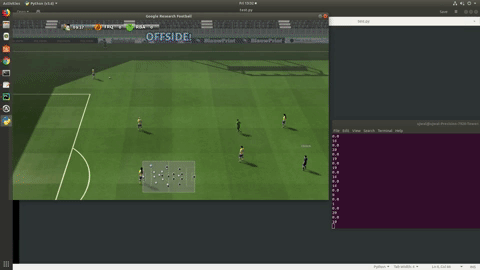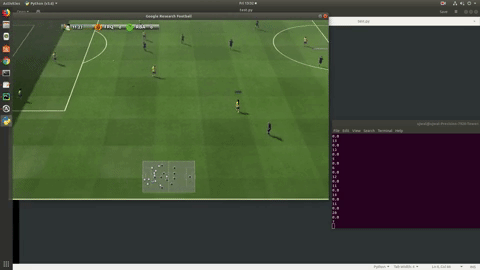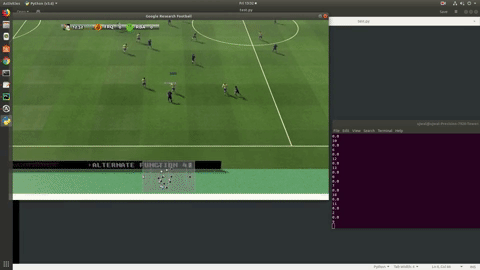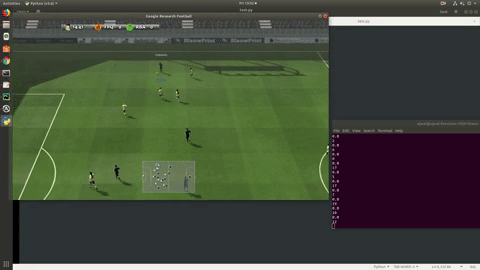
Output of running environment_test.py
If you encounter numpy version error the root cause may be the overlapping numpy version. Just try uninstalling numpy and try running the script again.
numpyバージョンエラーが発生した場合、根本的な原因はnumpyバージョンの重複である可能性があります。 numpyをアンインストールして、スクリプトを再実行してみてください。
Things to remember(覚えておくべきこと)
We have currently reported two issues to google football Github repository and they have acknowledged it and gave a temporary solution until they fix it.
現在、Google Football Githubリポジトリには2つの問題が報告されており、彼らはそれを認識し、修正するまで一時的な解決策を提供しています。
1.In float representation that is 115–dimension vector, the 115 dimensions is only specified for the 11v11 scenario, for all other, this number varies. So you can first check with state.shape[0] and then build your model accordingly. ( link to issue )
115次元のベクトルであるfloat表現では、115次元は11v11シナリオに対してのみ指定され、他のすべてのシナリオでは、この数は異なります。 したがって、最初にstate.shape [0]で確認してから、それに応じてモデルを構築します。 (問題へのリンク)
2.Currently, their program changes the present working directory of the running code so while saving the models use absolute paths. ( link to issue )
現在、彼らのプログラムは実行中のコードの現在の作業ディレクトリを変更するため、モデルを保存するときに絶対パスを使用します。 (問題へのリンク)
Training RL agent(RLエージェントのトレーニング)
Reinforcement Learning is basically divided into algorithms running on Value-based functions and Policy-based functions. Among such algorithms, Actor-Critic algorithms which are a combination of both of them have come out as state of the art with lesser variance and higher convergence rate.For a more detailed and mathematical explanation of various RL algorithms, you may refer to this blog post
強化学習は基本的に、価値ベースの関数とポリシーベースの関数で実行されるアルゴリズムに分けられます。このようなアルゴリズムの中で、両方を組み合わせたActor-Criticアルゴリズムは、分散が少なく収束率が高い最先端のアルゴリズムとして登場しています。さまざまなRLアルゴリズムのより詳細で数学的な説明については、このブログ投稿を参照してください(Cheat Sheetは参考になります)。
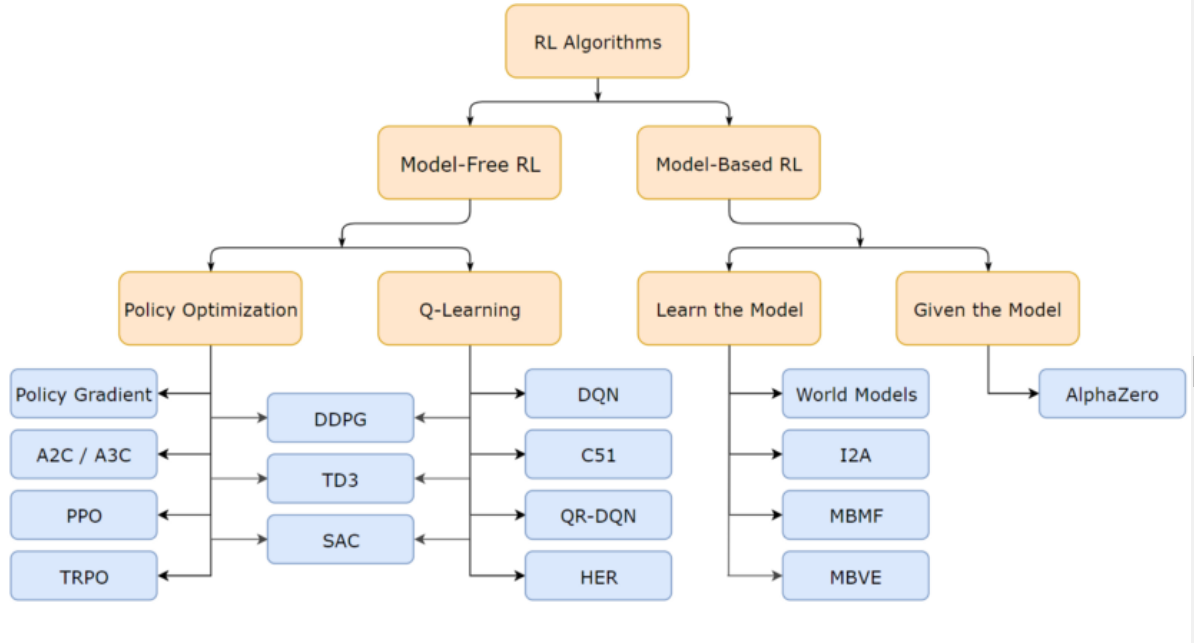
Classification of reinforcement algorithms: Source
Among such Actor-Critic algorithms is the Asynchronous Advantage Actor-Critic or commonly known as A3C.
このようなActor-Criticアルゴリズムの中には、Asynchronous AdvantageActor-Criticまたは一般にA3Cとして知られているものがあります。
Asynchronous Advantage Actor-Critic-
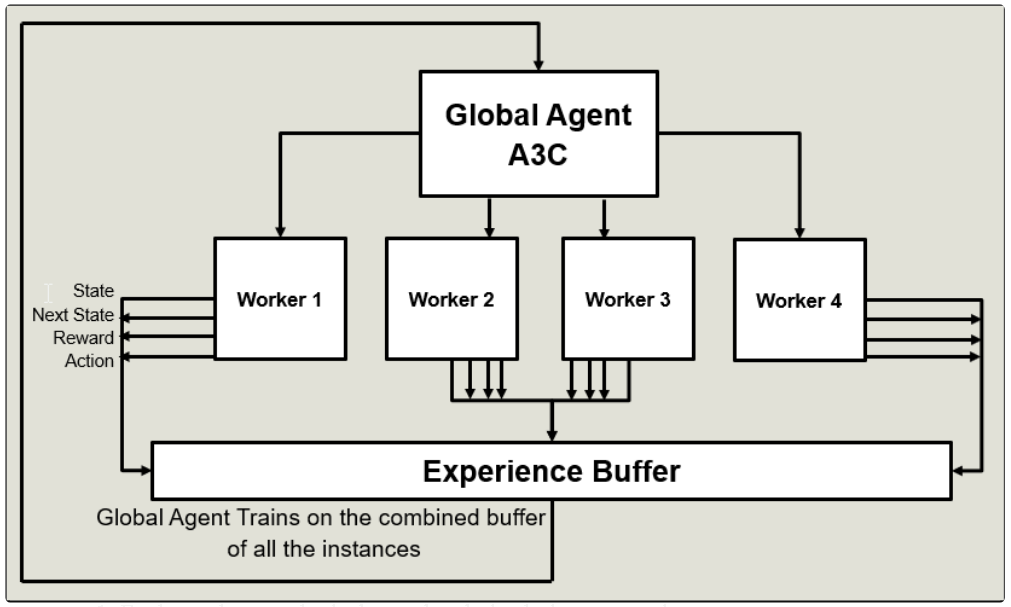
Let us break down this complex algorithm and understand the three A’s of A3C-
この複雑なアルゴリズムを分解して、A3Cの3つのAを理解しましょう-
Asynchronous-(非同期-)
A3C has the advantage of multiple workers with each separately working on its own environment and taking actions which are completely independent of each other. The following steps shall summarize its working in easy and laymen terms and bring out its advantages over other RL algorithms-
A3Cには、複数のワーカーがそれぞれ独自の環境で個別に作業し、互いに完全に独立したアクションを実行するという利点があります。 次の手順では、簡単で素人の言葉でその動作を要約し、他のRLアルゴリズムに対する利点を引き出します-
1.Each worker works independently in their own environment.
1.各ワーカーは、それぞれの環境で独立して働いています。
2.More exploration takes place with each worker running in parallel space.
2.各ワーカーが並列スペースで実行されると、より多くの探索が行われます。
3.Each worker at the end of each episode gives out tuple of information containing- [current state, next state, the action is taken, reward obtained, Done( Boolean value telling whether the episode ended or not].
3.各エピソードの終わりに各ワーカーは、[現在の状態、次の状態、アクションが実行され、報酬が取得され、完了(エピソードが終了したかどうかを示すブール値]を含む情報のタプルを提供します。
4.These tuples from each worker are couples together in a global buffer
4.各ワーカーからのこれらのタプルは、グローバルバッファー内で結合されます。
5.The global agent then trains on this global buffer and saves its weights.
5.次に、グローバルエージェントはこのグローバルバッファでトレーニングを行い、その重みを保存します。
6.The workers then load on the saved weights of the global agent.
6.次に、ワーカーは、グローバルエージェントの保存された重みをロードします。
7.The workers then take actions based on the trained weights of the Global Agent.
7.次に、ワーカーは、グローバルエージェントのトレーニングされた重みに基づいてアクションを実行します。
8.The same steps repeat till the global agent converges.
8.グローバルエージェントが収束するまで、同じ手順が繰り返されます。
9.Faster training since workers running in parallel.
9.ワーカーは並列で走っているので、訓練はより高速です。
Advantage function-(アドバンテージ関数-)
Q values can be broken down into two segments –
Q値は2つのセグメントに分けることができます-
1.The State Value function V(s)
1.状態値関数 V(s)
2.The Advantage value A(s, a)
2.アドバンテージ値 A(s, a)
Advantage functions can be derived as follows-
アドバンテージ関数は次のように導き出すことができます-
Q(s, a)= V(s)+ A(s,a)
A(s,a) =Q(s,a) -V(s)
A(s,a)= r+ γV(s_cap) -V(s)
Advantage function actually helps us better depict how an action is compared to the others at a given state while the value function captures how good it is to be at this state.
アドバンテージ関数は、実際には、特定の状態でアクションが他のアクションとどのように比較されるかをより適切に表すのに役立ちますが、値関数は、この状態でのアクションの良さをキャプチャします。
Code Implementation(コードの実装)
For the implementation of RL algorithms, we have used ChainerRL library given it contains an optimized version of A3C. We have used one file namely a3c.py which contains the code for training the agent.
RLアルゴリズムの実装には、最適化されたバージョンのA3Cが含まれているChainerRLライブラリを使用しています。 エージェントをトレーニングするためのコードを含む1つのファイルa3c.pyを使用しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
def main(): misc.set_random_seed(0) env1 = env.create_environment(env_name=global_enviornment_name, render=True, representation='simple115') env1 = chainerrl.wrappers.CastObservationToFloat32(env1) timestep_limit = 180 obs_space = env1.observation_space print(obs_space) action_space = env1.action_space print(action_space) #21 is the action space for the environment. model = A3CFFMellowmax(state_space_size,21) opt = rmsprop_async.RMSpropAsync( lr=7e-4, eps=1e-1, alpha=0.99) opt.setup(model) opt.add_hook(chainer.optimizer.GradientClipping(40)) agent = a3c.A3C(model, opt, t_max=5, gamma=0.99, beta=1e-2) outdir = "" #path of the output directory to store the model. Give absolute path . if not os.path.isdir(outdir): os.makedirs(outdir) steps=20000*5000 eval_n_steps= 500 eval_n_episodes=None eval_interval=150 train_max_episode_len= 250 eval_max_episode_len = 250 chainerrl.experiments.train_agent_with_evaluation(agent, env1, steps, eval_n_steps,eval_n_episodes, eval_interval, outdir, train_max_episode_len, step_offset=0,eval_max_episode_len=eval_max_episode_len, eval_env=env1, successful_score=100, step_hooks=[], save_best_so_far_agent=True,logger=None ) if __name__ == '__main__': main() |
The code snippet above includes only the heart of the algorithm. You can review the whole file here. We have used the academy close goal scenario for training and the scenario names can be defined in the variable global_environment_name and similarly its state space in the variable state_space_size.
上記のコードスニペットには、アルゴリズムの中心部のみが含まれています。 ここでファイル全体を確認できます。 トレーニングにはacademyの至近距離ゴールシナリオを使用しました。シナリオ名は変数global_environment_nameで定義でき、同様に変数state_space_sizeでその状態空間を定義できます。
Following videos show the training results
次のビデオはトレーニング結果を示しています
Repository link(リポジトリへのリンク)
https://github.com/Ujwal2910/Deep-RL-on-Gfootabll-Google-football-OpenAI-style-environment
A3C
DQNに続く「次の」強化学習アルゴリズム。
もうDQNは使わないかもしれないというぐらいの優れもの….らしいです。
工事中
Next
M1 Mac で動かしてみたいです。多分Rosetta上で動くことになるのでしょうか?
Reference
Scenarios(シナリオ)やエージェントのトレーニングに関しては以下のページもご参照ください
Google Research Football のトレーニングを Google の Colaboratory でやってみる
Google Research Football の環境でゲームをしてみる
Interest
Training RL agent(RLエージェントのトレーニング)で紹介されている強化アルゴリズムの分類の Sourceは興味深いです。Holly GrimmさんのページのBlogタグの中の2週目(Week 2)がリンクされていますが、その他のタグも機械学習がArtシーンでどう使われるのかが紹介されています。
美術(and/or芸術)と機械学習に興味のある方は参考になります。
Solid State な人工知能や機械学習ばかりじゃない世界もあります^^。
参考までに
AI Portraits Ars について
Leave a Reply