
Jetson NanoのようなGPUを積んだシングルボードコンピュータで画像を識別する機械学習のトレーニングをやってみます。
元ネタはTellusの「学習済みモデルを利用して手軽にゴルフ場が写っているかを判定できる機械学習モデルを作成する」です。
同様のチュートリアルはSIGNATE Questにもあるようです。
転移学習の実習という位置付け。GoogleのColabを使うことが想定されているようですがJetson Nano でも実行できます。
Githubにコードとデータが準備されています。ローカル環境でのトレーニングの項をやってみます。
Jetson Nano(4GB)の環境はJetson Nano + NVIDIA Docker で Pytorch の環境構築をしてみるで作成したコンテナ(my_env)です。
データは256 x 256のpositive画像(3695枚)+ negative画像(566枚)。

Githubに公開されているので、ダウンロードして以下のような作業フォルダー(work)を作って格納しておきます。
ディレクトリ構造
0->negative(ゴルフ場が写っていない画像)
1->positive(ゴルフ場が写っている画像)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
work train_positive.png train_negative.png golf 0 14_14302_6516.png 14_14302_6518.png ・ ・ ・ 14_14311_6478.png 1 14_14301_6525.png 14_14302_6525.png ・ ・ ・ 14_14338_6496.png |
container側にもworkフォルダーを作っておきます。
|
1 |
mkdir /work |
Dockerコマンドでhostからcontainerへデータをコピーします。
まず、CONTAINER_IDを調べておきます。
|
1 |
sudo docker container ps -a |
host側で作業ディレクトリへ移動して一気にコピー(4000枚くらいの数ですが、たいして時間はかかりません)。
|
1 2 |
cd work sudo docker cp ./ CONTAINER_ID:/work |
これ以降、モデルの作成はコンテナーでの作業になります。
コンテナでのみ実行する場合は、wgetでファイルを取得後、unzipで解凍
ファイルの場所は、https://github.com/sorabatake/article_15199_golf/archive/master.zip
my_envという名前のコンテナを起動
|
1 |
sudo docker start -i my_env |
以下のライブラリをインストールしておきます。
|
1 2 3 |
pip3 install tqdm pip3 install widgetsnbextension pip3 install ipywidgets |
jupyterlabを起動
|
1 2 |
cd /work jupyter lab --ip=0.0.0.0 --allow-root |
アドレスをコピーして、ブラウザーでjupyterにアクセスしてNotebookを開きます。
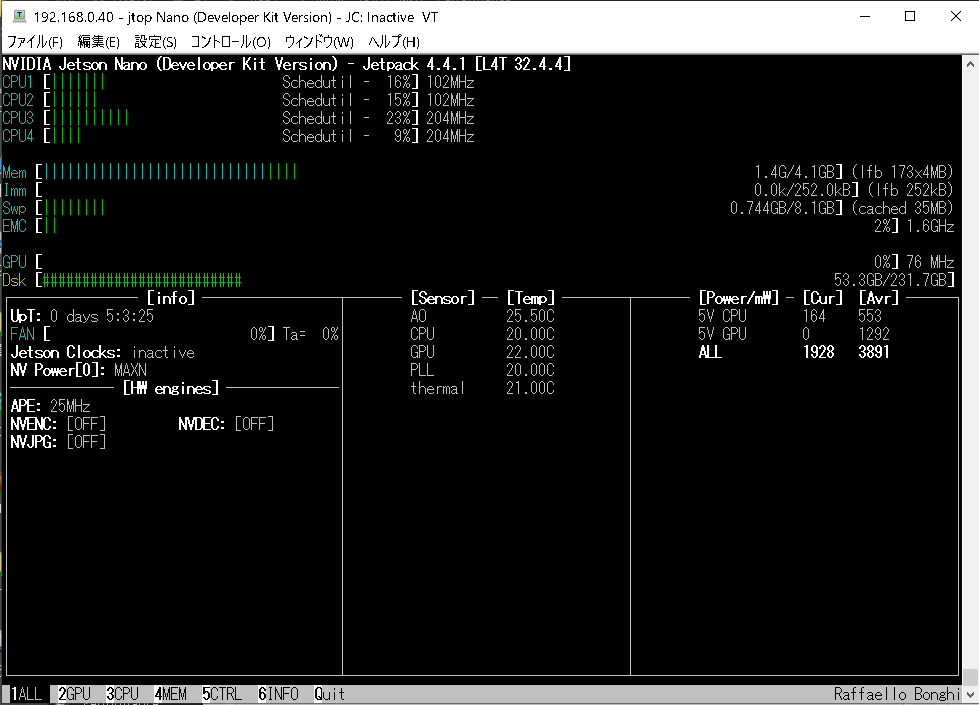
また、実行をモニターしたいので、SSHでJetson-stats(jtop)も開いておきます。
以降はTellusの内容に沿って実行するだけです。
モデル構築と学習(GPU環境)
ライブラリーをインポート
|
1 2 3 4 5 6 7 8 9 10 11 |
import numpy as np from tqdm import tqdm from PIL import Image import torch.nn as nn from torch.autograd import Variable import torch import torchvision.transforms as transforms import torchvision.models as models import torchvision |
画像を読み込む
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
transform = transforms.Compose( [ # 画像サイズが異る場合は利用して画像サイズを揃える # transforms.Resize((256,256)), # 左右対称の画像を生成してデータ量を増やす(Augmentation) transforms.RandomHorizontalFlip(), # PyTorchで利用するTensorの形式にデータを変換 transforms.ToTensor() ]) # google colab等で実行する際にフォルダ内に .ipynb_checkpoints があると、ラベルの対象になるので削除 !rm -rf golf/.ipynb_checkpoints # ImageFolder を利用して読み込む data = torchvision.datasets.ImageFolder(root='./golf', transform=transform) |
正しくラベル付けがされているか確認
|
1 |
data.class_to_idx |
{‘0’: 0, ‘1’: 1}
学習用と評価用のデータに分割する
|
1 2 3 4 5 6 7 8 9 10 |
train_size = int(0.8 * len(data)) validation_size = len(data) - train_size data_size = {"train":train_size, "validation":validation_size} data_train, data_validation = torch.utils.data.random_split(data, [train_size, validation_size]) train_loader = torch.utils.data.DataLoader(data_train, batch_size=16, shuffle=True) validation_loader = torch.utils.data.DataLoader(data_validation, batch_size=16, shuffle=False) dataloaders = {"train":train_loader, "validation":validation_loader} |
モデル作成
resnet18という学習済みモデル(Pre-trained Model)が使われています。
|
1 2 |
model = models.resnet18(pretrained=True) model |
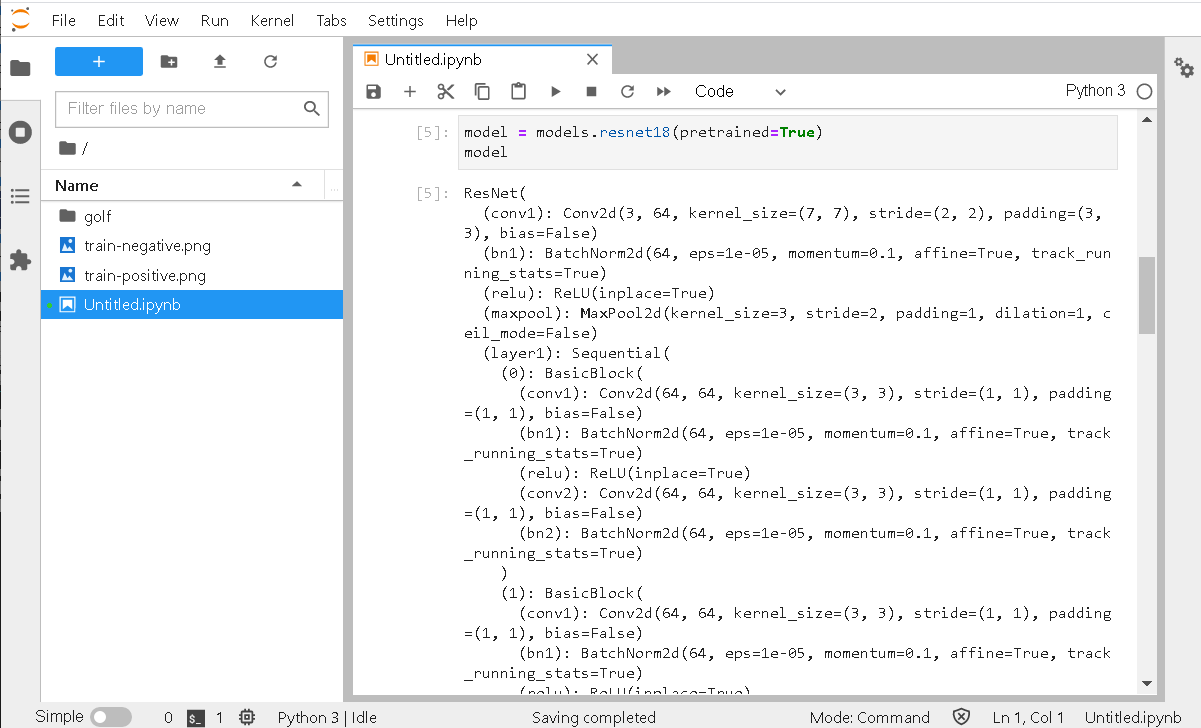
|
1 2 3 4 5 6 7 8 9 10 |
# 現在のモデルすべてのパラメータの requires_grad を False にすることで # ネットワークの重みを固定することができる for parameter in model.parameters(): parameter.requires_grad = False # 今回は0,1の予測のため、最終的な出力を2個に設定 model.fc = nn.Linear(512, 2) # CPU環境の場合は不要 model = model.cuda() |
モデルを学習
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
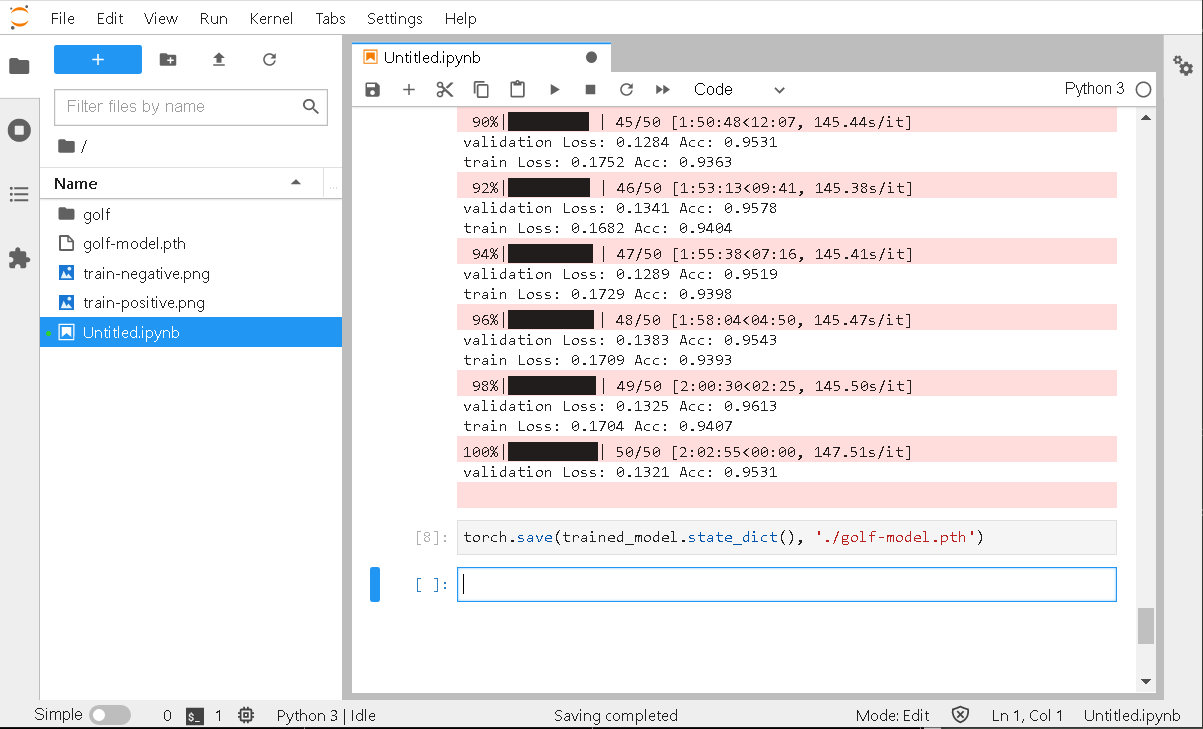
lr = 1e-4 epoch = 50 optim = torch.optim.Adam(model.parameters(), lr=lr, weight_decay=1e-4) # CPU環境の場合は cuda() は不要 criterion = nn.CrossEntropyLoss().cuda() def train_model(model, criterion, optimizer, num_epochs): for epoch in tqdm(range(num_epochs)): epoch_loss = 0 epoch_acc = 0 for phase in ['train', 'validation']: if phase == 'train': model.train() else: model.eval() current_loss = 0.0 current_corrects = 0 for data in dataloaders[phase]: inputs, labels = data # CPU環境では不要 inputs = inputs.cuda() labels = labels.cuda() outputs = model(inputs) _, preds = torch.max(outputs.data, 1) loss = criterion(outputs, labels) if phase == 'train': optimizer.zero_grad() loss.backward() optimizer.step() # CPU環境では item() 不要 current_loss += loss.item() * inputs.size(0) current_corrects += torch.sum(preds == labels) epoch_loss = current_loss / data_size[phase] # CPU環境では item() 不要 epoch_acc = current_corrects.item() / data_size[phase] print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc)) return model trained_model = train_model(model, criterion, optim, epoch) |
こんな感じで進捗します。
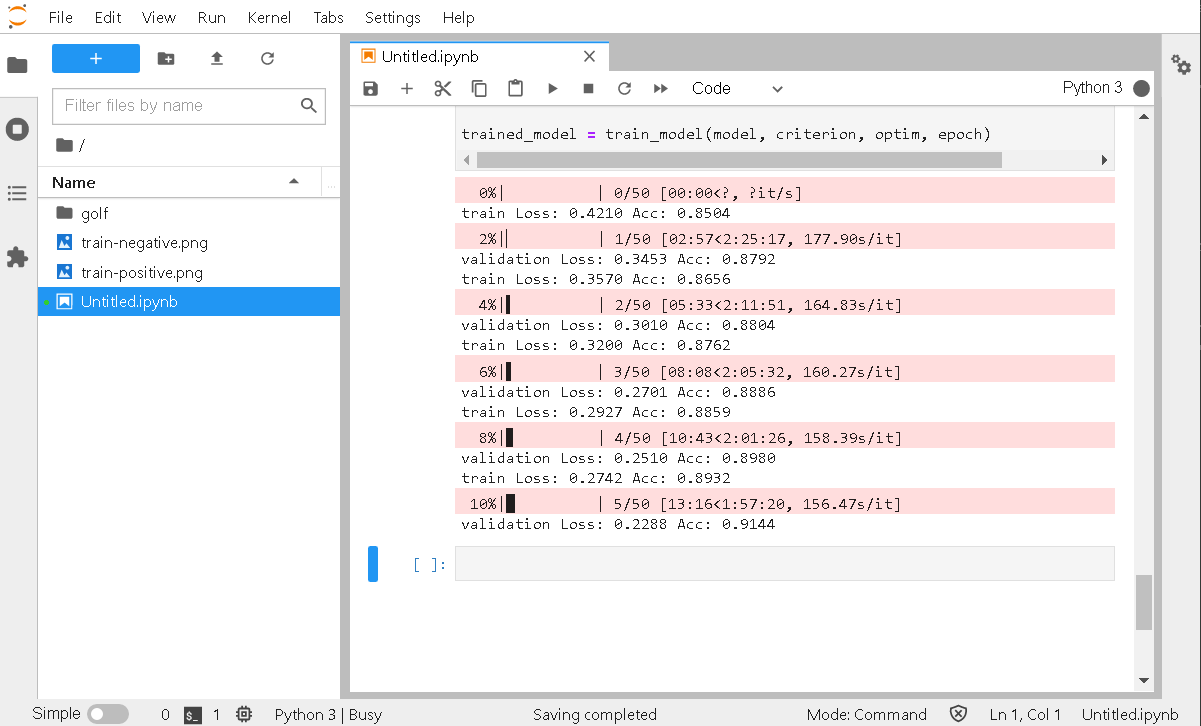
jetson-statsを見てみると、GPUとCPUが交互にフル稼働しているのが分かります。
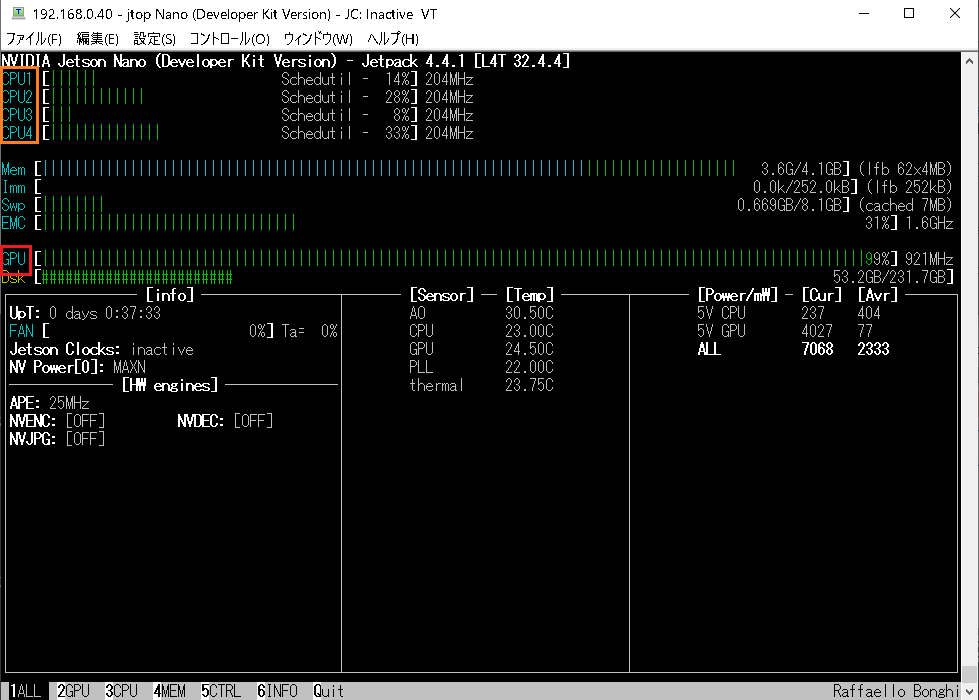
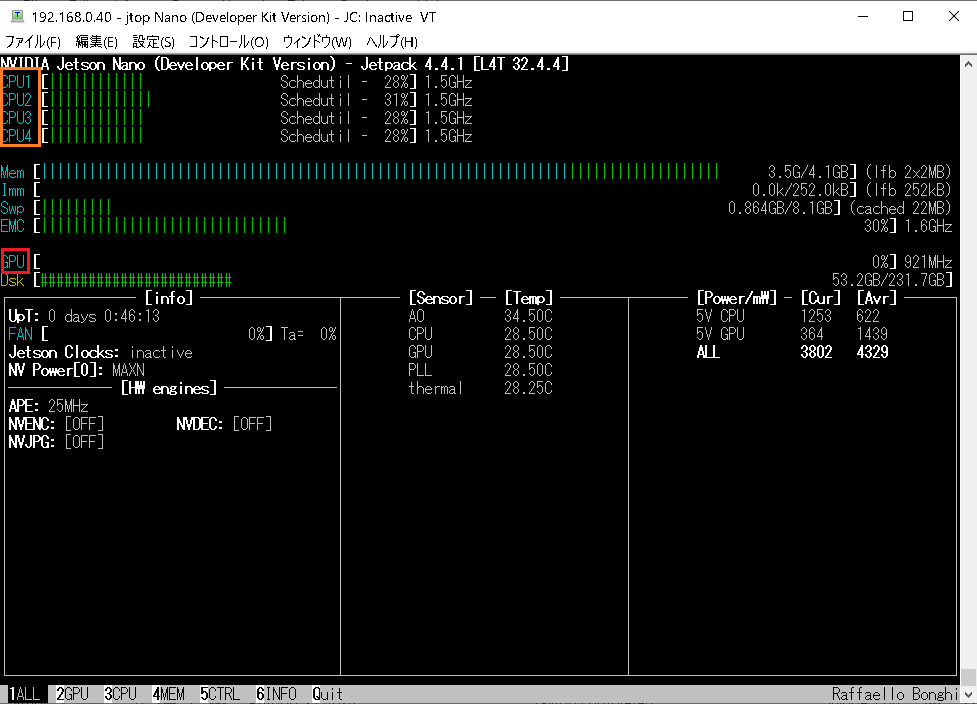
Jetson Nano(4GB)の場合、トレーニングは2時間ちょっとで終了します。
最後にモデルのファイルを出力しておきます(モデルを再利用する際に使います)。
|
1 |
torch.save(trained_model.state_dict(), './golf-model.pth') |
予測
モデルを評価モードに変更して、テスト用の画像読み込みをして、モデルに渡せる形式にします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
#Regression trained_model.eval() imsize = 256 loader = transforms.Compose([transforms.Scale(imsize), transforms.ToTensor()]) def image_loader(image_name): image = Image.open(image_name).convert("RGB") image = loader(image) image = Variable(image, requires_grad=True) image = image.unsqueeze(0) # CPU環境の場合は cuda() は不要 return image.cuda() m = nn.Softmax(dim=1) |
train-positive.png を予測してみて、ネットワークから出力される結果を見てみます。
|
1 2 |
image = image_loader('./train-positive.png') print(m(model(image))) |
train-negative.png を予測してみて、ネットワークから出力される結果を見てみます。
|
1 2 |
image = image_loader('./train-negative.png') print(m(model(image))) |
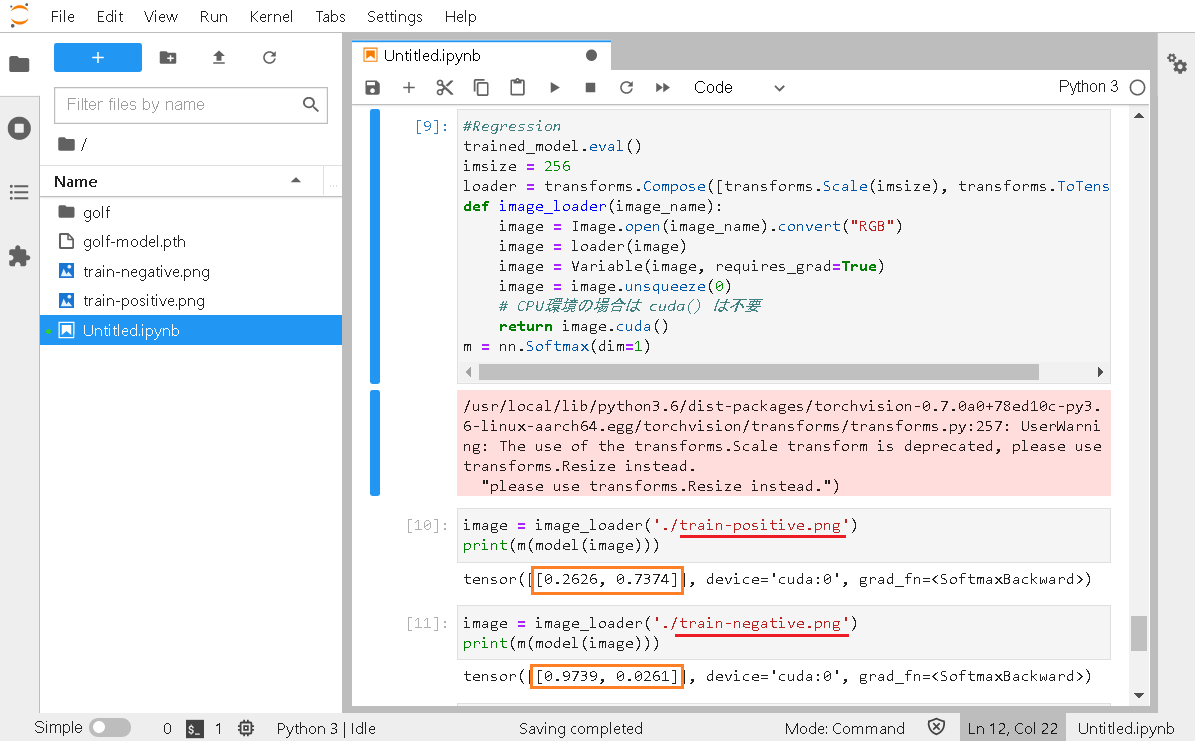
0~1の範囲で [negativeの可能性, positiveの可能性] という形式で出力されるので、このような形でtrain-positive.pngが右側、train-negative.pngが左側の数値が大きくなっているのでちゃんと予測できているっぽいです……だそうです。
注
ピンクの部分でWarningが出ています。Torchvisionでtransforms.Scaleは非推奨になったようです。問題は無いのですが、気になる場合はtransforms.Resizeに変更してください。引数などはそのままです。
保存済みのモデルファイル(./golf-model.pth)を読み込んで再利用してみる
ipynbファイルは削除するか移動しておきます。
jupyterlabを再起動
|
1 2 |
cd /work jupyter lab --ip=0.0.0.0 --allow-root |
ブラウザでNotebookを開いておきます。
以下を実行
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
from PIL import Image import torch.nn as nn from torch.autograd import Variable import torch import torchvision.transforms as transforms import torchvision.models as models import torchvision model = models.resnet18(pretrained=True) model.fc = nn.Linear(512, 2) model_path = './golf-model.pth' model.load_state_dict(torch.load(model_path)) model.eval() imsize = 256 loader = transforms.Compose([transforms.Scale(imsize), transforms.ToTensor()]) def image_loader(image_name): image = Image.open(image_name).convert("RGB") image = loader(image) image = Variable(image, requires_grad=True) image = image.unsqueeze(0) return image m = nn.Softmax(dim=1) |
画像(./new_image.png)を読み込んで予測実行
|
1 2 |
image = image_loader('./new_image.png') print(m(model(image))) |
Next1
Tellusの内容の後半はTellusOSを使った画像の取得と予測になっています。
衛星画像の取得はこのぺージでやったように産総研のLandbrowserを使ってもダウンロードできます。この画像が使えるかどうかテストしてみます。
TellusOSは使わずにローカル環境でまかなってみます。
Jetson Nano + Pytorch で衛星画像識別モデルを検証してみる
Next2
もう一個、Jetson Nanoレベルのシングルボードコンピュータで使えるニューラルネットワークでトレーニングしてみます。画像分類です。こういうのをいくつかやると、Pytorchで画像を扱う場合の調理法の理解が進むんじゃないでしょうか。
Next3
モデルファイルを再利用するコードを使ってアプリ化してみます。
FlaskやらTkinterやらを使ってみます。
Appendix
フルコード
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 |
import numpy as np from tqdm import tqdm from PIL import Image import torch.nn as nn from torch.autograd import Variable import torch import torchvision.transforms as transforms import torchvision.models as models import torchvision transform = transforms.Compose( [ # 画像サイズが異る場合は利用して画像サイズを揃える # transforms.Resize((256,256)), # 左右対称の画像を生成してデータ量を増やす(Augmentation) transforms.RandomHorizontalFlip(), # PyTorchで利用するTensorの形式にデータを変換 transforms.ToTensor() ]) # google colab等で実行する際にフォルダ内に .ipynb_checkpoints があると、ラベルの対象になるので削除 !rm -rf golf/.ipynb_checkpoints # ImageFolder を利用して読み込む data = torchvision.datasets.ImageFolder(root='./golf', transform=transform) data.class_to_idx train_size = int(0.8 * len(data)) validation_size = len(data) - train_size data_size = {"train":train_size, "validation":validation_size} data_train, data_validation = torch.utils.data.random_split(data, [train_size, validation_size]) train_loader = torch.utils.data.DataLoader(data_train, batch_size=16, shuffle=True) validation_loader = torch.utils.data.DataLoader(data_validation, batch_size=16, shuffle=False) dataloaders = {"train":train_loader, "validation":validation_loader} model = models.resnet18(pretrained=True) model # 現在のモデルすべてのパラメータの requires_grad を False にすることで # ネットワークの重みを固定することができる for parameter in model.parameters(): parameter.requires_grad = False # 今回は0,1の予測のため、最終的な出力を2個に設定 model.fc = nn.Linear(512, 2) # CPU環境の場合は不要 model = model.cuda() lr = 1e-4 epoch = 50 optim = torch.optim.Adam(model.parameters(), lr=lr, weight_decay=1e-4) # CPU環境の場合は cuda() は不要 criterion = nn.CrossEntropyLoss().cuda() def train_model(model, criterion, optimizer, num_epochs): for epoch in tqdm(range(num_epochs)): epoch_loss = 0 epoch_acc = 0 for phase in ['train', 'validation']: if phase == 'train': model.train() else: model.eval() current_loss = 0.0 current_corrects = 0 for data in dataloaders[phase]: inputs, labels = data # CPU環境では不要 inputs = inputs.cuda() labels = labels.cuda() outputs = model(inputs) _, preds = torch.max(outputs.data, 1) loss = criterion(outputs, labels) if phase == 'train': optimizer.zero_grad() loss.backward() optimizer.step() # CPU環境では item() 不要 current_loss += loss.item() * inputs.size(0) current_corrects += torch.sum(preds == labels) epoch_loss = current_loss / data_size[phase] # CPU環境では item() 不要 epoch_acc = current_corrects.item() / data_size[phase] print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc)) return model trained_model = train_model(model, criterion, optim, epoch) torch.save(trained_model.state_dict(), './golf-model.pth') #Regression trained_model.eval() imsize = 256 loader = transforms.Compose([transforms.Scale(imsize), transforms.ToTensor()]) def image_loader(image_name): image = Image.open(image_name).convert("RGB") image = loader(image) image = Variable(image, requires_grad=True) image = image.unsqueeze(0) # CPU環境の場合は cuda() は不要 return image.cuda() m = nn.Softmax(dim=1) image = image_loader('./train-positive.png') print(m(model(image))) image = image_loader('./train-negative.png') print(m(model(image))) |
Leave a Reply