
New(2021/03/19)
Nano(2GB)の実行環境を変更してみました
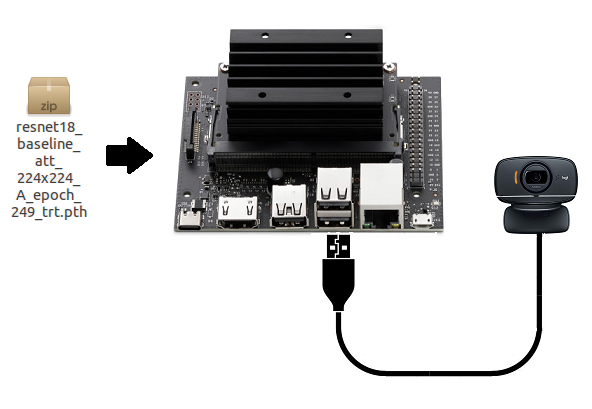
Jetson Nanoで学習済みモデルを使って、いろいろやってみる(4-1)姿勢推定(ResNet-18)で作成した、TensorRTで最適化した重みデータを使ってみます。
上記ページで「resnet18_baseline_att_224x224_A_epoch_249_trt.pth」というファイル名で保存されます。
Please note that TensorRT has device specific optimizations, so you can only use an optimized model on similar platforms.
TensorRTにはデバイス固有の最適化があるため、同様のプラットフォームでのみ最適化されたモデルを使用できることに注意してください。
とのこと。
Xavier NX で作成したものとNano(4GB)で作成したものがJetson Nano(2GB)で再利用できるか試してみました。
NXの場合はどうでしょう?
結論から言うと不可です。
ファイルをロードする段階でエラーになります。
|
1 2 3 4 |
model_trt = TRTModule() model_trt.load_state_dict(torch.load(OPTIMIZED_MODEL)) AttributeError: 'NoneType' object has no attribute 'create_execution_context' |
NVIDIAによれば、このメッセージが出た場合は以下をチェックする必要があるそうです。
1.Linux distro and version
2.GPU type
3.Nvidia driver version
4.CUDA version
5.CUDNN version
6.Python version [if using python]
7.Tensorflow and PyTorch version
8.TensorRT version
今回は同じバージョンのJetpack(4.5.1)とコンテナイメージを使ったので、2以外は同じものです。
NXのGPUはVoltaアーキテクチャですが、NanoはMaxwellです。
従って

同じアーキテクチャのNano(4GB)はどうだったかというと

では、Nano(2GB)で実際に読み込んでパフォ-マンスを見てみます。
以下の記述で/home/jetsonのユーザー名は適宜ご自分の環境のユーザー名で置き換えてください。
Jetson Nano (2GB)に環境構築
まず、JetpackはNano(2GB)用にデスクトップが軽量化されて最適化されたJetpack(4.5.1)を使用。
コンテナイメージは4.5.1用に「nvcr.io/nvidia/l4t-ml:r32.5.0-py3」です。
OSをセットアップしてコンテナを起動するまでは、Jetson Nanoで学習済みモデルを使って、いろいろやってみる(4-1)姿勢推定(ResNet-18)と同じです。
Notebookを使う前に最適化されたファイル「resnet18_baseline_att_224x224_A_epoch_249_trt.pth」をNano(2GB)に移しておきます。
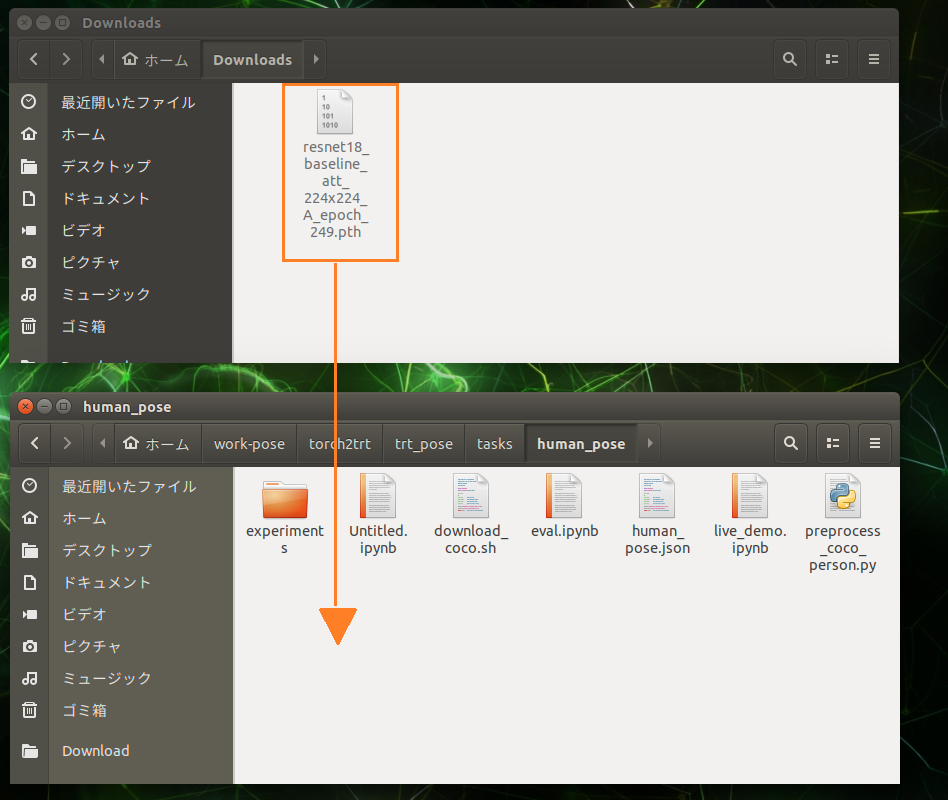
例えばこんなコマンドです。ディレクトリ名は適宜、置き換えてください。
sudo cp /home/jetson/Public/resnet18_baseline_att_224x224_A_epoch_249_trt.pth /home/jetson/work-pose/torch2trt/trt_pose/tasks/human_pose
Swapが4GBくらいアサインされているのを確認してください。Swap領域が少ないと実行途中でほぼフリーズ状態になります。
|
1 |
free -h |
コンテナ起動後、
ブラウザーでNotebook を開きます。
127.0.0.1:8888
パスワードを聞かれたら「nvidia」です。
Notebook でPython3を使いましょう。
ディレクトリは/work/torch2trt/trt_pose/tasks/human_poseです。
以下のコードを実行します。pthは作成せずに読み込むだけですので、Jetson Nanoで学習済みモデルを使って、いろいろやってみる(4-1)姿勢推定(ResNet-18)の場合とは少し異なります。
トポロジーテンソルを作成
|
1 2 3 4 5 6 7 |
import json import trt_pose.coco with open('human_pose.json', 'r') as f: human_pose = json.load(f) topology = trt_pose.coco.coco_category_to_topology(human_pose) |
モデルをロード
|
1 2 3 4 5 6 |
import trt_pose.models num_parts = len(human_pose['keypoints']) num_links = len(human_pose['skeleton']) model = trt_pose.models.resnet18_baseline_att(num_parts, 2 * num_links).cuda().eval() |
サンプルデータ作成
|
1 2 3 4 5 |
import torch WIDTH = 224 HEIGHT = 224 data = torch.zeros((1, 3, HEIGHT, WIDTH)).cuda() |
最適化された重みを読み込みます。
|
1 2 3 4 5 |
from torch2trt import TRTModule OPTIMIZED_MODEL = 'resnet18_baseline_att_224x224_A_epoch_249_trt.pth' model_trt = TRTModule() model_trt.load_state_dict(torch.load(OPTIMIZED_MODEL)) |
FPSでモデルをベンチマーク、やってもやらなくてもいいと思います。
|
1 2 3 4 5 6 7 8 9 10 |
import time t0 = time.time() torch.cuda.current_stream().synchronize() for i in range(50): y = model_trt(data) torch.cuda.current_stream().synchronize() t1 = time.time() print(50.0 / (t1 - t0)) |
元々BGR8 / HWC形式の画像を前処理する関数を定義
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
import cv2 import torchvision.transforms as transforms import PIL.Image mean = torch.Tensor([0.485, 0.456, 0.406]).cuda() std = torch.Tensor([0.229, 0.224, 0.225]).cuda() device = torch.device('cuda') def preprocess(image): global device device = torch.device('cuda') image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) image = PIL.Image.fromarray(image) image = transforms.functional.to_tensor(image).to(device) image.sub_(mean[:, None, None]).div_(std[:, None, None]) return image[None, ...] |
ニューラルネットワークからオブジェクトを解析するために使用される2つの呼び出し可能なクラスを定義し、解析されたオブジェクトを画像上に描画します。
|
1 2 3 4 5 |
from trt_pose.draw_objects import DrawObjects from trt_pose.parse_objects import ParseObjects parse_objects = ParseObjects(topology) draw_objects = DrawObjects(topology) |
jetcamパッケージを使用して、BGR8 / HWC形式で画像を生成する使いやすいカメラを作成
|
1 2 3 4 5 6 7 8 |
from jetcam.usb_camera import USBCamera # from jetcam.csi_camera import CSICamera from jetcam.utils import bgr8_to_jpeg camera = USBCamera(width=WIDTH, height=HEIGHT, capture_fps=30,capture_device=0) # camera = CSICamera(width=WIDTH, height=HEIGHT, capture_fps=30) camera.running = True |
視覚化されたカメラフィードを表示するために使用されるウィジェットを作成
|
1 2 3 4 5 6 |
import ipywidgets from IPython.display import display image_w = ipywidgets.Image(format='jpeg') display(image_w) |
メインの実行ループを定義
|
1 2 3 4 5 6 7 8 |
def execute(change): image = change['new'] data = preprocess(image) cmap, paf = model_trt(data) cmap, paf = cmap.detach().cpu(), paf.detach().cpu() counts, objects, peaks = parse_objects(cmap, paf)#, cmap_threshold=0.15, link_threshold=0.15) draw_objects(image, counts, objects, peaks) image_w.value = bgr8_to_jpeg(image[:, ::-1, :]) |
カメラフレームで関数を1回実行、シングルショットで姿勢推定画像を取得
|
1 |
execute({'new': camera.value}) |
実行関数をカメラの内部値にアタッチします。 これにより、新しいカメラフレームが受信されるたびにexecute関数が呼び出されます。ムービーで姿勢推定動画像を取得
|
1 |
camera.observe(execute, names='value') |
カメラフレームコールバックのアタッチを解除
|
1 |
camera.unobserve_all() |
Nano(2GB)
1フレームの解析自体は4GBと遜色ない速度で実行されます。
ただ、動画の場合はRAMが2GBしかないので、読み込みがカクカクしていて、ちとしんどいかな。
シングルショットでの姿勢推定の解析は問題ないです。
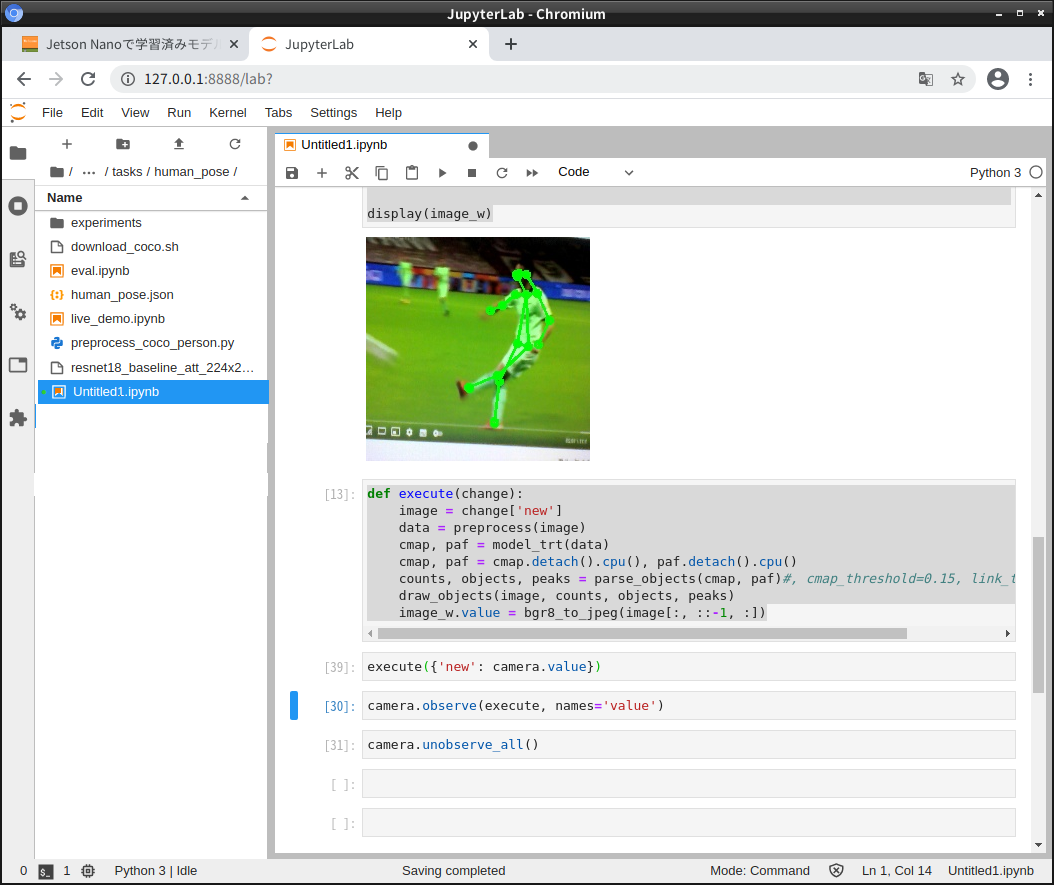
解析速度には問題ないのだからこういう構成でなんかできないかな?
Next
では、Nano(2GB)しか持っていない場合はどうするか?
Colabは使えないのは分かったので、無料で使える(らしい)学習環境のNVIDIA DIGITS を試してみる予定。
Appendix
Nano(4GB)で作成した重みファイルです(111MB)。
上記と同じ環境なら実行可能なはずです。
resnet18_baseline_att_224x224_A_epoch_249_trt.pth
実行環境の変更
このページに倣って、trt_poseの実行環境を以下のようにしてみました。
●Jupyter Notebookは使わずに、Pythonファイルで実行できるようにする
●PythonのカメラインターフェースはJetCam ではなくOpenCVのVideoCaptureクラスを使う
●ビデオ表示にはtkinter + canvas を使う
これでNotebookより軽快に動作します。
で、コンテナ環境にも変更点があります。
1.JetCamやJupyterの拡張機能のインストールは不要です。
2.scikit-learnをダウングレードしておく
|
1 2 |
pip3 uninstall scikit-learn pip3 install scikit-learn==0.23.2 |
3.tkinterをインストール
|
1 |
apt -y install python3-tk |
Pythonファイルを作っておきます。
USBカメラが1台だけ接続されている前提です。

改めてコンテナを起動
|
1 |
sudo docker start -i my_pose |
ディレクトリを移動
|
1 |
cd /work/torch2trt/trt_pose/tasks/human_pose |
以下のようなPythonファイルを作成
上記のNano(4GB)で作成した最適化済み重みファイル(resnet18_baseline_att_224x224_A_epoch_249_trt.pth)をロードするだけです。
【pose_view.py】
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 |
# -*- coding: utf-8 -*- print("preparing...") import tkinter as tk import cv2 from PIL import Image,ImageTk import numpy as np root=tk.Tk() root.title("camera") root.geometry("224x224") root.resizable(width=False, height=False) canvas=tk.Canvas(root, width=224, height=224, bg="white") canvas.pack() #------------------------------------- import json import trt_pose.coco with open('human_pose.json', 'r') as f: human_pose = json.load(f) topology = trt_pose.coco.coco_category_to_topology(human_pose) WIDTH = 224 HEIGHT = 224 OPTIMIZED_MODEL = 'resnet18_baseline_att_224x224_A_epoch_249_trt.pth' from torch2trt import TRTModule import torch model_trt = TRTModule() model_trt.load_state_dict(torch.load(OPTIMIZED_MODEL)) import cv2 import torchvision.transforms as transforms import PIL.Image mean = torch.Tensor([0.485, 0.456, 0.406]).cuda() std = torch.Tensor([0.229, 0.224, 0.225]).cuda() device = torch.device('cuda') def preprocess(image): global device device = torch.device('cuda') image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) image = PIL.Image.fromarray(image) image = transforms.functional.to_tensor(image).to(device) image.sub_(mean[:, None, None]).div_(std[:, None, None]) return image[None, ...] from trt_pose.draw_objects import DrawObjects from trt_pose.parse_objects import ParseObjects parse_objects = ParseObjects(topology) draw_objects = DrawObjects(topology) def execute(change): image = change['new'] data = preprocess(image) cmap, paf = model_trt(data) cmap, paf = cmap.detach().cpu(), paf.detach().cpu() counts, objects, peaks = parse_objects(cmap, paf) draw_objects(image, counts, objects, peaks) return image #------------------------------------- def capStart(): print('camera-start') try: global c, w, h, img c=cv2.VideoCapture(0) w, h= c.get(cv2.CAP_PROP_FRAME_WIDTH), c.get(cv2.CAP_PROP_FRAME_HEIGHT) print('width:'+str(w)+'px/height:'+str(h)+'px') except: import sys print("error") print(sys.exec_info()[0]) print(sys.exec_info()[1]) c.release() cv2.destroyAllWindows() def up():#change update global img ret, frame = c.read() if ret: frame = frame[0:720, 0:720] size = (224,224) frame = cv2.resize(frame,size) frame = execute({'new': frame}) img = ImageTk.PhotoImage(Image.fromarray(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))) canvas.create_image(0,0,image=img,anchor="nw") else: print("up failed") root.after(1,up) capStart() up() root.mainloop()と |
とりあえずファイルを閉じて、コンテナも終了しておきます。
改めて、実行
ホスト側で以下を実行しておきます。
|
1 |
sudo xhost si:localuser:root |
コンテナを起動
|
1 |
sudo docker start -i my_pose |
ディレクトリを移動してPythonファイル実行
trtファイルのロードに2分くらいかかりますが、起動すればtkinterで作ったウィンドウに画像が表示されます。
|
1 2 3 |
cd /work/torch2trt/trt_pose/tasks/human_pose python3 pose_view.py |
ラジオ体操やってます
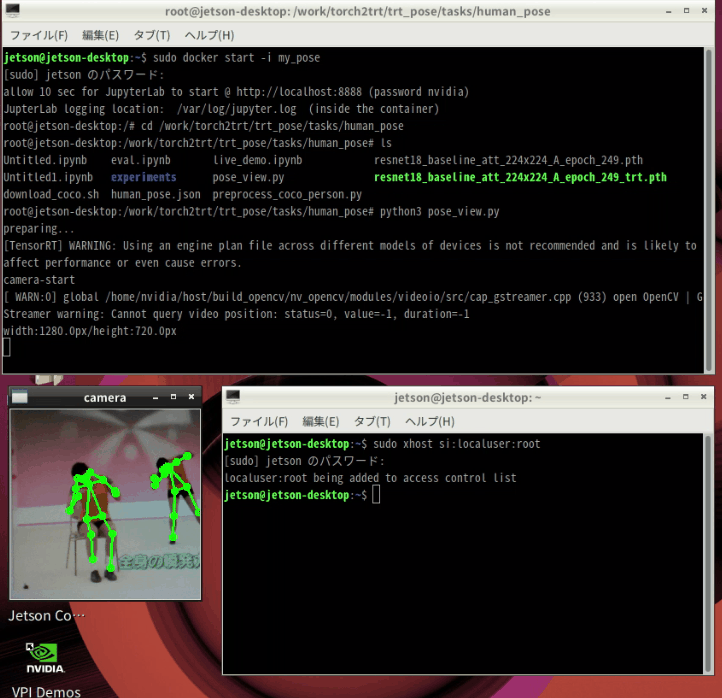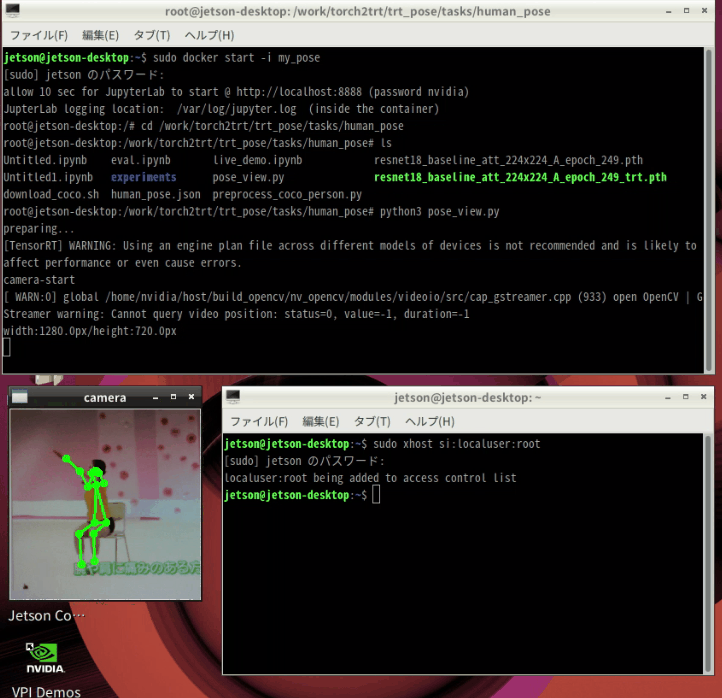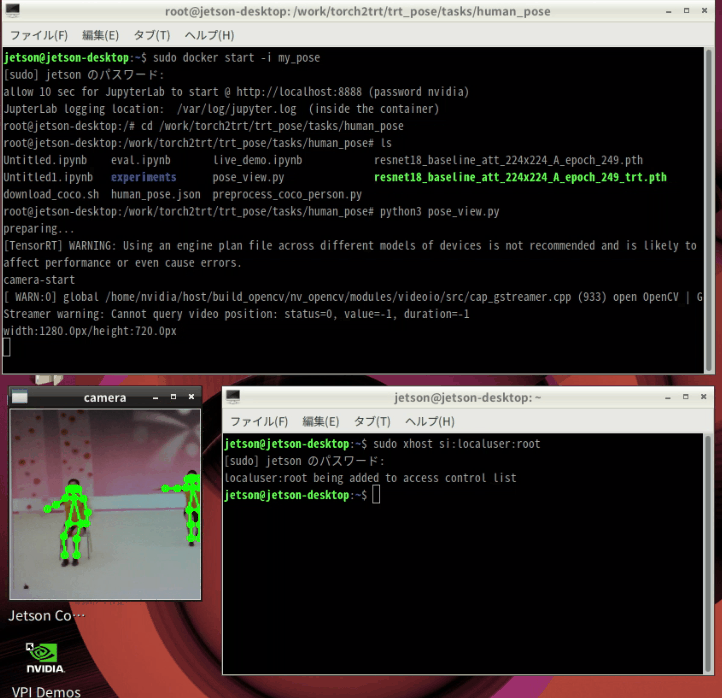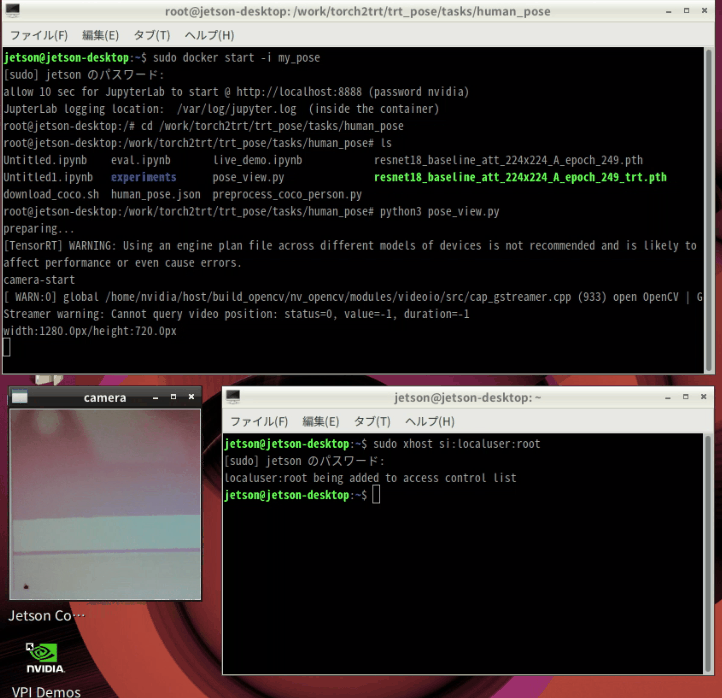
終了する場合は、ウィンドウを閉じてCtrl + Z
再起動は、コンテナの再起動から行います。
Leave a Reply