
rinnaさんご提供の事前学習モデルがアップデートされました。rinnakk/japanese-pretrained-models
ここではJetson Nano + Docker の環境で、BERTの改良版 RoBERTa(Robustly optimized BERT approach)の例をやってみます。
Jetson Nanoは4GB版を使ってみました。OSイメージは、Jetpack 4.6。

DockerイメージはNVIDIAご提供のnvcr.io/nvidia/l4t-pytorch:r32.5.0-pth1.7-py3、pytorch1.7.0が実装されています。
|
1 |
sudo docker pull nvcr.io/nvidia/l4t-pytorch:r32.5.0-pth1.7-py3 |
コンテナ作成
sudo docker create -it --name my_bert --gpus all --network host nvcr.io/nvidia/l4t-pytorch:r32.5.0-pth1.7-py3
コンテナを起動
|
1 |
sudo docker start -i my_bert |
アップデート&アップグレード、パッケージなどをインストール
|
1 2 3 4 |
apt update apt upgrade -y apt install python3-pip -y python3 -m pip install --upgrade pip setuptools |
HuggingFaceのPytorch版 transformerをインストールします。バージョンは4.9.2になります。
|
1 |
pip3 install transformers |
ここでエラーが発生した場合
・
error: can’t find Rust compiler
・
・
ERROR: Could not build wheels for tokenizers which use PEP 517 and cannot be installed directly
ここを参照
SentencePieceをインストール
|
1 |
pip3 install sentencepiece |
日本語を扱うのでコンテナを日本語化しておきます。
|
1 2 3 4 |
apt install language-pack-ja-base language-pack-ja locale-gen ja_JP.UTF-8 //永続化 echo "export LANG=ja_JP.UTF-8" >> ~/.bashrc |
Pythonコンソールを開いてモデルを使ってみます。
|
1 2 3 4 5 6 7 8 |
import torch from transformers import T5Tokenizer, RobertaForMaskedLM tokenizer = T5Tokenizer.from_pretrained("rinna/japanese-roberta-base") tokenizer.do_lower_case = True # due to some bug of tokenizer config loading model = RobertaForMaskedLM.from_pretrained("rinna/japanese-roberta-base") |
初回はデータがダウンロードされます。
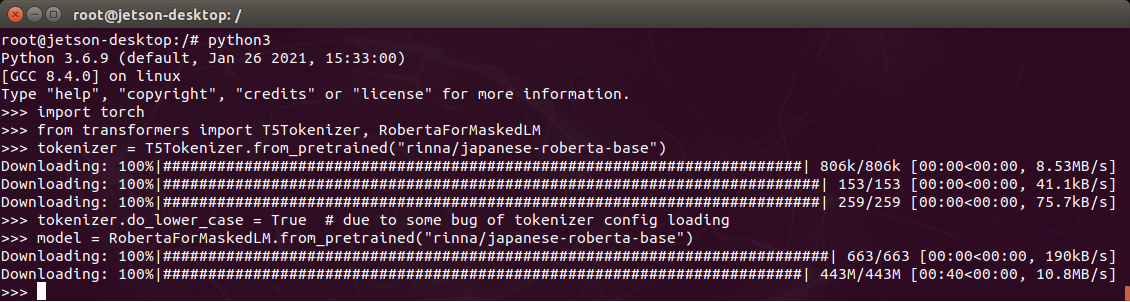
モデルを使って例を実行してみます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
model = model.eval() # original text text = "4年に1度オリンピックは開かれる。" # prepend [CLS] text = "[CLS]" + text # tokenize tokens = tokenizer.tokenize(text) print(tokens) # output: ['[CLS]', '▁4', '年に', '1', '度', 'オリンピック', 'は', '開かれる', '。']'] # mask a token masked_idx = 5 tokens[masked_idx] = tokenizer.mask_token print(tokens) # output: ['[CLS]', '▁4', '年に', '1', '度', '[MASK]', 'は', '開かれる', '。'] # convert to ids token_ids = tokenizer.convert_tokens_to_ids(tokens) print(token_ids) # output: [4, 1602, 44, 24, 368, 6, 11, 21583, 8] # convert to tensor token_tensor = torch.tensor([token_ids]) # get the top 10 predictions of the masked token with torch.no_grad(): outputs = model(token_tensor) predictions = outputs[0][0, masked_idx].topk(10) for i, index_t in enumerate(predictions.indices): index = index_t.item() token = tokenizer.convert_ids_to_tokens([index])[0] print(i, token) |
こんな感じ。
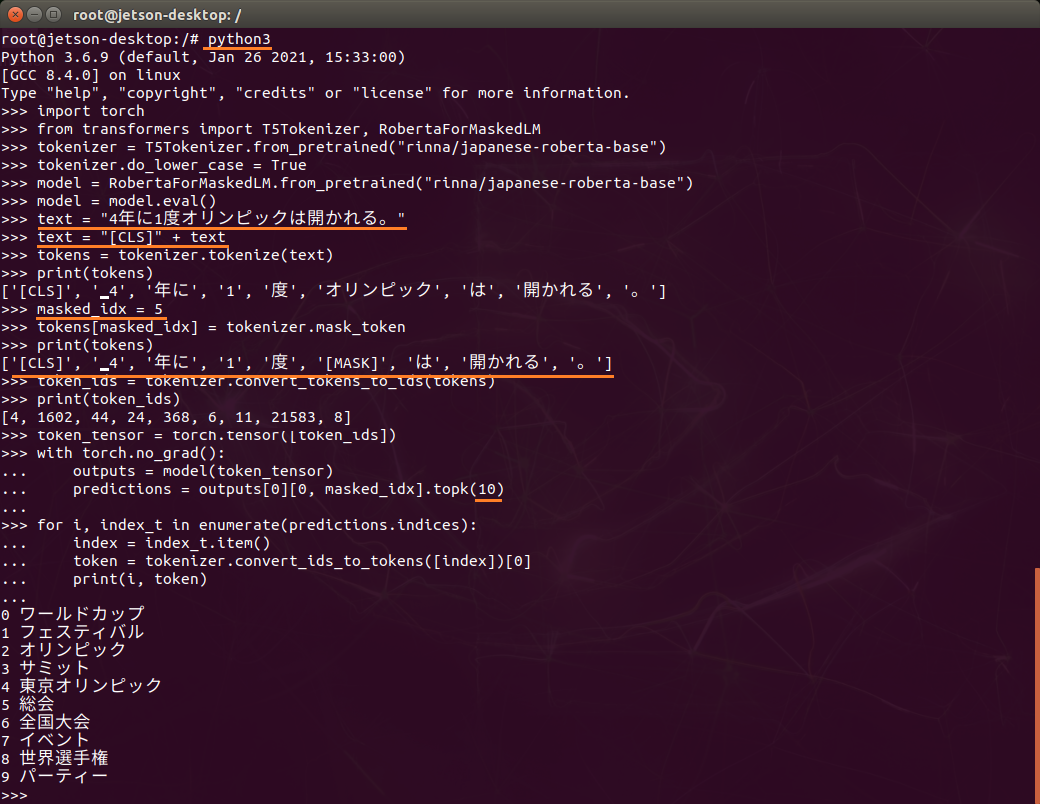
いったい何をしているのかというと、
元文「4年に1度オリンピックは開かれる。」の先頭に[CLS]を付加し、tokenに分割した後、5番目のtokenを[MASK]に置き換えます。
「4年に1度、[MASK]は開催される。」の[MASK]部分を予測した結果の上位10ワードを提示してくれているそうです。
エラーが発生した場合の対処
・
・
error: can’t find Rust compiler
・
・
・
ERROR: Could not build wheels for tokenizers which use PEP 517 and cannot be installed directly
|
1 2 3 4 5 6 |
apt install curl -y curl https://sh.rustup.rs -sSf | bash -s -- -y PATH="/root/.cargo/bin:${PATH}" pip3 install setuptools_rust |
再実行
|
1 |
pip3 install transformers |
Appendix
Jetson Nanoで学習済みモデルを使って、いろいろやってみる(7)自然言語処理(GPT-2)
Appendix 2
BERT日本語Pretrainedモデルはこいうとこでも公開されています。
気が向いたら使ってみましょう。
|
1 2 3 4 |
import torch from pytorch_pretrained_bert import BertTokenizer, BertModel bert_model = BertModel.from_pretrained("/path/to/Japanese_L-24_H-1024_A-16_E-30_BPE_WWM/") bert_tokenizer = BertTokenizer("/path/to/Japanese_L-24_H-1024_A-16_E-30_BPE_WWM/vocab.txt", do_lower_case=False, do_basic_tokenize=False) |
Appendix 3
GPT-3 はMicrosoftの制約(?)もあってかクラウドサービスとして申請者のみが利用できる状況です。
ただOSSでEleutherAIが、Pileでトレーニングされた60億のパラメーターモデルであるGPT-J-6Bを公開しています。ほぼほぼGPT-3に匹敵する性能だそうです。
興味のある方、デモ版もあるので試してみましょう。
Leave a Reply