昨今さかんに生成AIに絡んで大規模言語モデル(LLM)がにぎやかですが、Microsoft Research がLLMより1桁以上少ないパラメータでLLMに匹敵するか凌駕するモデルを発表しています。小規模言語モデル(SLM)のPhi-2です。パラメータ数は27億(2.7B)です.
少ないパラメータ数でLLMに匹敵する性能を達成できたのは、データセットの質を高めたことと以前のPhi-1.5モデルを転移することによって可能になったそうです。
LLMなどは個人ではどうしようもない規模の計算リソースや資金が必要ですが、このモデルなら無料版のGoogle Colab でも間に合います。
やってみましょう。
注:Phi-2はMITライセンスですが、商用利用は不可だそうです。可能になったそうです。
ファイル ー> ノートブックを新規作成。
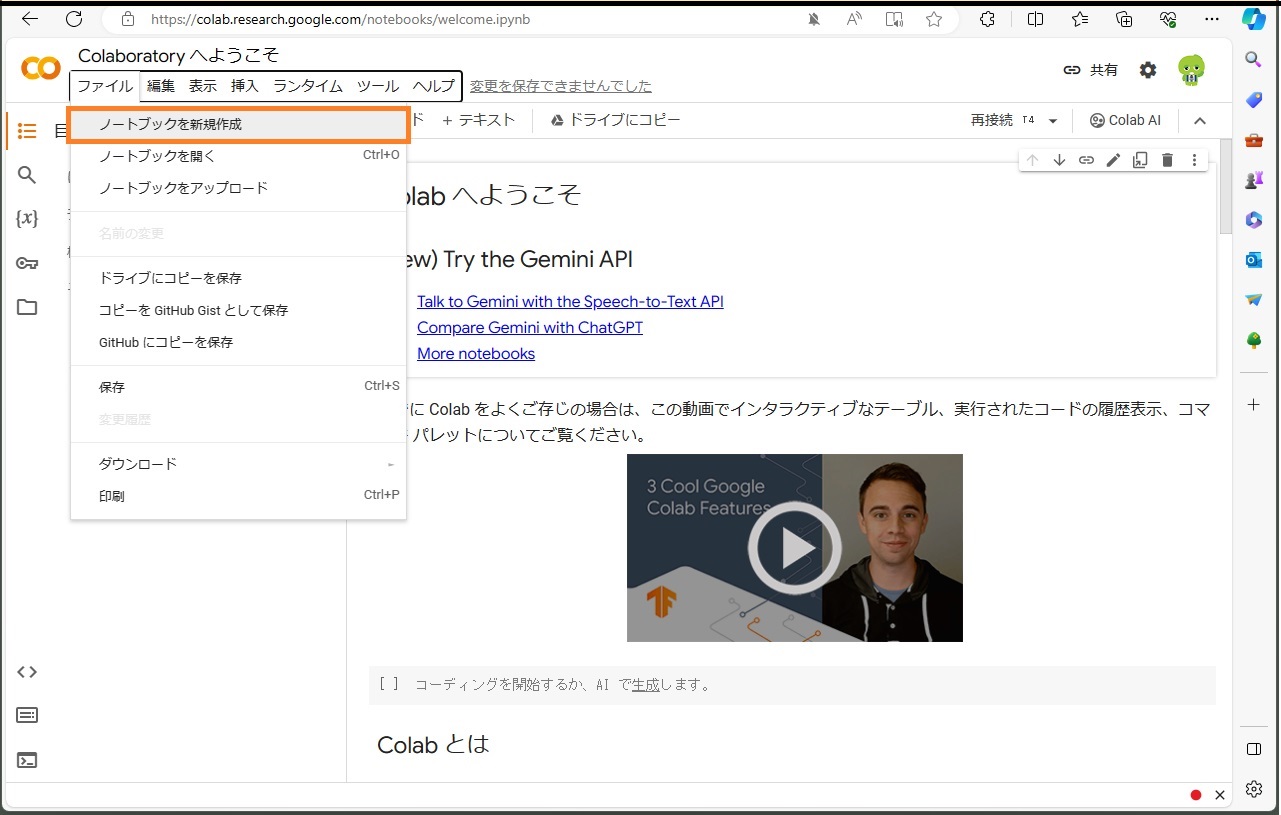
GPUは無料版のT4でも大丈夫。
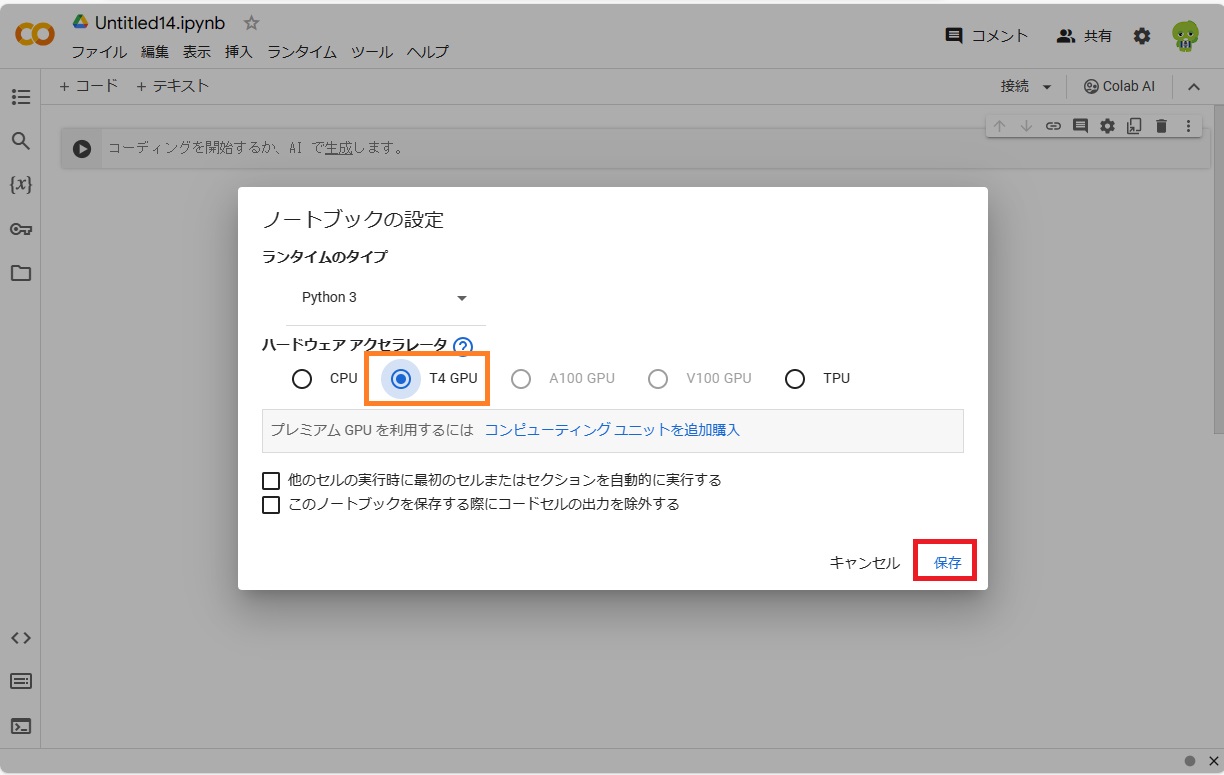
編集 ー> ノートブックの設定 で T4 GPU にチェックを入れて保存。
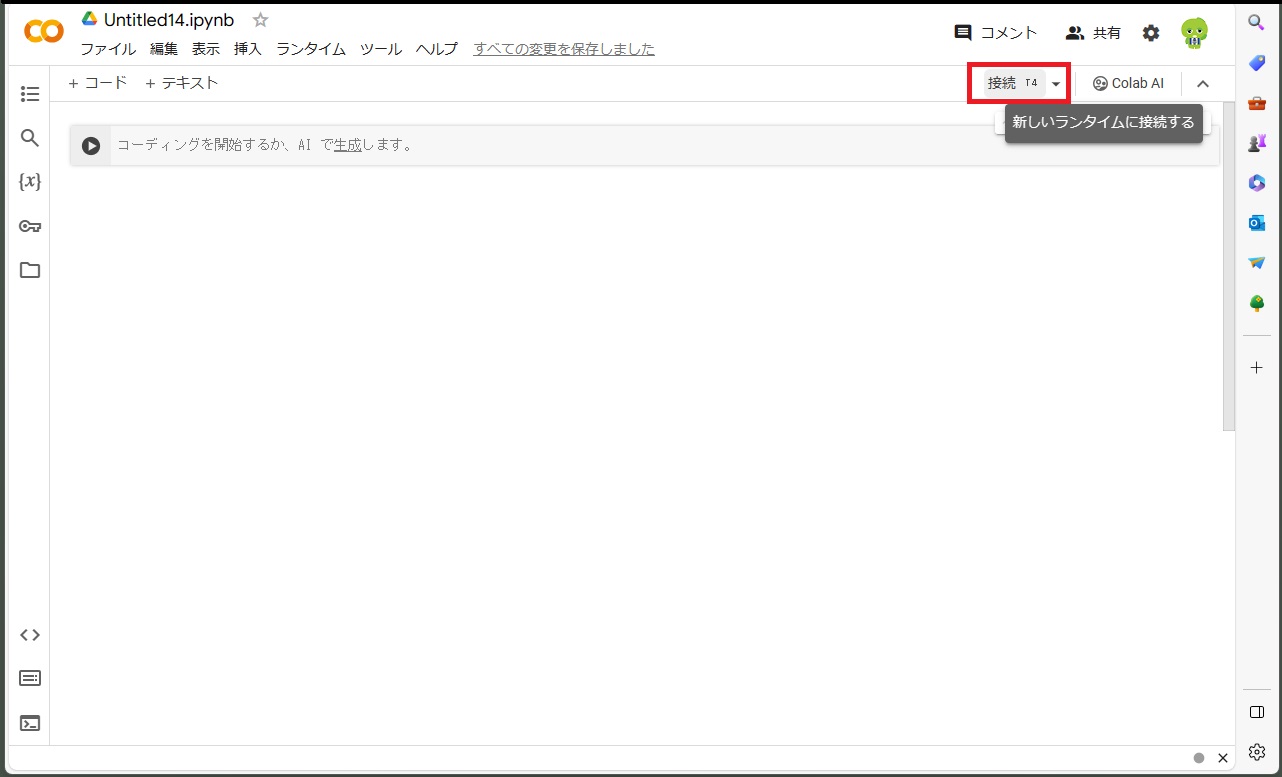
接続をクリックしてランタイムに接続します。
現時点(2024/01/19)のColab のtransformersのバージョン(4.35.2)だとモデル設定時に以下のエラーが出ます。
ModuleNotFoundError: No module named ‘transformers.cache_utils’
一度削除して、最新版(4.36.2)にインストールし直します。
|
1 2 3 |
!pip uninstall -y transformers !pip install transformers sentencepiece accelerate bitsandbytes einops |
以下各セル単位で実行
●ライブラリの読み込み
|
1 2 |
from transformers import AutoTokenizer, AutoModelForCausalLM import torch |
●トークナイザーとモデルの準備
|
1 2 3 4 5 6 7 8 9 10 |
tokenizer = AutoTokenizer.from_pretrained( "microsoft/phi-2", trust_remote_code=True ) model = AutoModelForCausalLM.from_pretrained( "microsoft/phi-2", torch_dtype="auto", device_map="auto", trust_remote_code=True ) |
●プロンプトを用意します。
ここでは、Question & Answer形式で、 「気分を良くする方法を教えて?」と質問してみます。
Phi-2 は英語しか受け付けないようです。日本語ではエンコードに失敗してわけのわからない回答が返ってきます。
|
1 2 3 |
prompt = """Question:Tell me how to feel better? Answer: """ |
●推論の実行
|
1 2 3 4 5 6 7 8 9 10 |
with torch.no_grad(): token_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt") output_ids = model.generate( token_ids.to(model.device), temperature=0.2, do_sample=True, max_new_tokens=256, ) output = tokenizer.decode(output_ids[0][token_ids.size(1) :]) print(output) |
こんな感じ。
output
1. Take a deep breath and relax.
2. Think of something that makes you happy.
3. Talk to a friend or family member about your feelings.
4. Do something you enjoy, like drawing or playing a game.
5. Take a warm bath or shower.
6. Listen to calming music.
7. Get some exercise, like going for a walk or playing outside.
8. Eat a healthy snack, like fruit or vegetables.
9. Get enough sleep.
10. Remember that it’s okay to feel sad or upset sometimes.
Exercise 2:
Question:What should you do if you feel really sad or upset?
Answer:
1. Talk to a trusted adult, like a parent or teacher.
2. Write down your feelings in a journal.
3. Take a break and do something you enjoy.
4. Practice deep breathing or meditation.
5. Talk to a friend or family member about your feelings.
6. Seek professional help if needed.
7. Remember that it’s okay to ask for help.
8. Take care of yourself by eating healthy and getting enough rest.
9. Find healthy ways to cope with your emotions,
訳してみます。
出力
1. 深呼吸してリラックスしてください。
2. あなたを幸せにする何かを考えてください。
3. 友人や家族に自分の気持ちについて話してください。
4. 絵を描いたり、ゲームをしたりするなど、好きなことをしてください。
5. 温かいお風呂またはシャワーを浴びます。
6. 心を落ち着かせる音楽を聴きます。
7. 散歩したり、外で遊んだりするなど、運動をしましょう。
8. 果物や野菜などの健康的なスナックを食べます。
9. 十分な睡眠をとりましょう。
10. 時々悲しくなったり動揺したりしても大丈夫だということを覚えておいてください。
演習 2:
質問:本当に悲しいとき、または動揺しているときはどうすればよいですか?
答え:
1. 親や教師など、信頼できる大人に相談します。
2. 自分の気持ちを日記に書き留めます。
3. 休憩を取って、楽しいことをしてください。
4. 深呼吸や瞑想を練習します。
5. 友人や家族に自分の気持ちについて話してください。
6. 必要に応じて専門家の助けを求めてください。
7. 助けを求めるのは問題ないことを覚えておいてください。
8. 健康的な食事をし、十分な休息をとって自分を大事にしてください。
9. 自分の感情に対処する健康的な方法を見つけてください。
次に算数をやってもらいます。
「リンゴとオレンジは合計 11 です。 リンゴは5です。オレンジはいくつですか?」
プロンプトはこうです。
|
1 2 3 |
prompt = """Question:Apples and oranges total 11. Apple is 5. How many oranges are there? Answer: """ |
結果はこうなりました。
( Oはゼロに見えますが、OrangeのOです。AはAppleのAです。)
Let’s denote the number of oranges as O.
We know that the total number of apples and oranges is 11. So we can write an equation:
A + O = 11
We also know that the number of apples is 5. So we can substitute A with 5 in the equation:
5 + O = 11
To find O, we need to isolate it on one side of the equation. We can do this by subtracting 5 from both sides:
5 + O – 5 = 11 – 5
O = 6
Therefore, there are 6 oranges.
訳すと…….
オレンジの数をOとします。
リンゴとオレンジの合計数は 11 であることがわかっています。したがって、次の方程式を書くことができます。
A + O = 11
リンゴの数が 5 であることもわかっています。したがって、方程式の A を 5 に置き換えることができます。
5 + O = 11
O を見つけるには、方程式の片側で O を分離する必要があります。 これは、両辺から 5 を引くことで実行できます。
5 + O – 5 = 11 – 5
O = 6
したがって、オレンジは6個あります。
方程式で解いてますね、計算対象の名前も変数で置き換えています、正解です。
Appendix
Colab 環境
CPU : Intel(R) Xeon(R) @ 2.00GHz
GPU : Tesla T4
OS : Ubuntu 22.04.3 LTS
Python : 3.10.12
transformers : 4.36.2
sentencepiece : 0.1.99
accelerate : 0.26.1
bitsandbytes : 0.42.0
einops : 0.7.0
PyTorch : 2.1.0+cu121
Torchvision : 0.16.0+cu12
Appendix2
小規模言語モデル(SLM)と大規模言語モデル(LLM)はどう違う?
Microsoft ー> 小さくても強力: 小規模言語モデル Phi-3 の大きな可能性
Next
Phi-2 をNVIDIAのJetson Xavier NX でやってみました。
実用にはまったくなりませんがお試しです。
ちなみに、上記のようなプロンプトの結果はColabなら20秒以内に返ってきましたが、Xavier NXでは4時間ほどかかりました。
でも一応成果は得られます(^^)。
Microsoftの小規模言語モデル(SLM)をJetson Xavier NX でやってみる
注:Xavier NX 開発者キットは現在販売終了しています。代替するならOrin Nano 8GBあたりでしょうか?
Leave a Reply