
これまでLLM(大規模言語モデル)を量子化して圧縮したりプロンプトを使って類推したりするのにllama.cpp というツールを使ってきました。
このツールはHTTPサーバーを立てる機能も持っていたりします。つまり、今までcurlを使ってローカルで使っていましたが、Webブラウザーでプロンプトを発行して応答をもらうこともできます。
ここでの環境はPCにUbuntu をインストールしたものです。
またllama.cpp はこのページやこのページのようにソースからビルドして使います。
このページを参考にするなら、「日本で一番高い山はどこですか ?」という問いを、calm2-7b-chat-q4_0.ggufというモデルにローカルでする場合は以下のようなコマンドになります。
|
1 2 3 4 |
cd ~/llama.cpp ./main -m ~/models/gguf/calm2-7b-chat-q4_0.gguf -n 500 -p "USER:日本で一番高い山はどこですか ? ASSISTANT: " |
llama.cppにはHTTPのサーバー機能があります。今回は同じLLMモデルを使ってBotサーバーを立ち上げてみます。
外部からアクセスできるように、–host 0.0.0.0 で公開します。
ポート番号は8000。
使用したPCのCPU は2コア4スレッドだったので、-t 4 を指定しています。ここは読み替えてください。
|
1 2 3 |
cd ~/llama.cpp ./server -m ~/models/gguf/calm2-7b-chat-q4_0.gguf --host 0.0.0.0 -t 4 --port 8000 |
外部ブラウザーからアクセスします。
アクセス例:http://192.168.0.31:8000
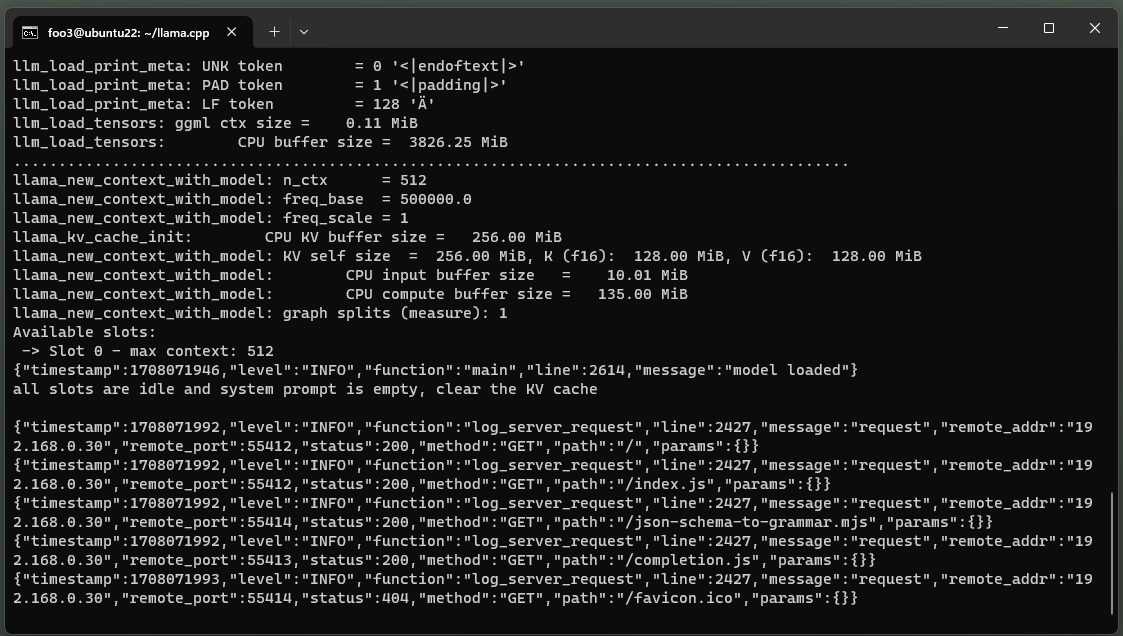
以下のようなページが開きます。
Chatがデフォルト。
User name とBot name はQuestion & Answer の名前になります(なんでもいいです)。
青で囲ったフィールドにプロンプトを記述して、Sendボタンをクリック。
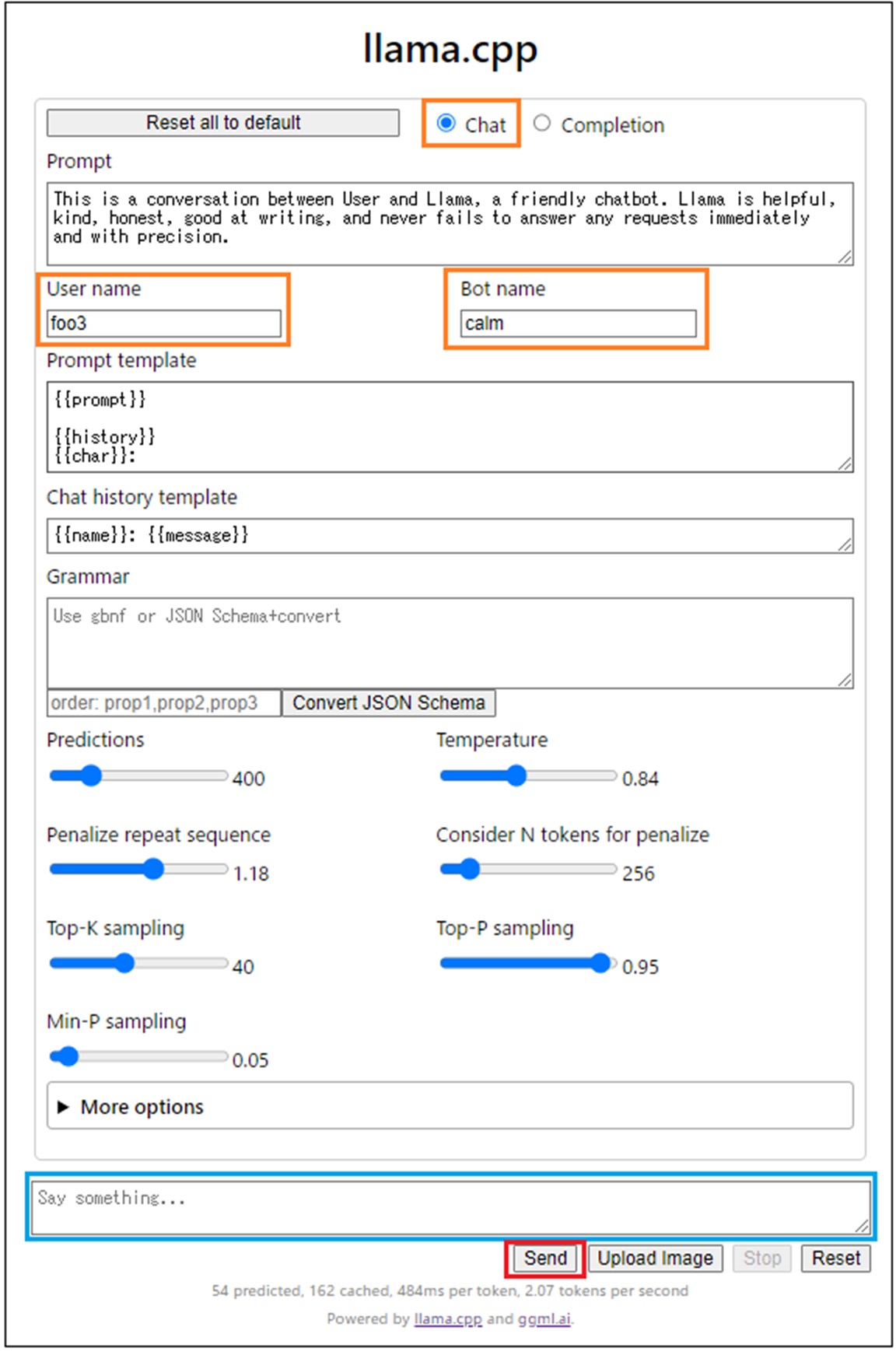
こんな感じで、Q&A のやりとりができます。
<|endoftext|>が表示されたり、Sendボタンがアクティブになったら、次のプロンプトをフィールドに記述してまたSend します。
なにやら最初に設定したnameタグ以外を使って無駄話をしています
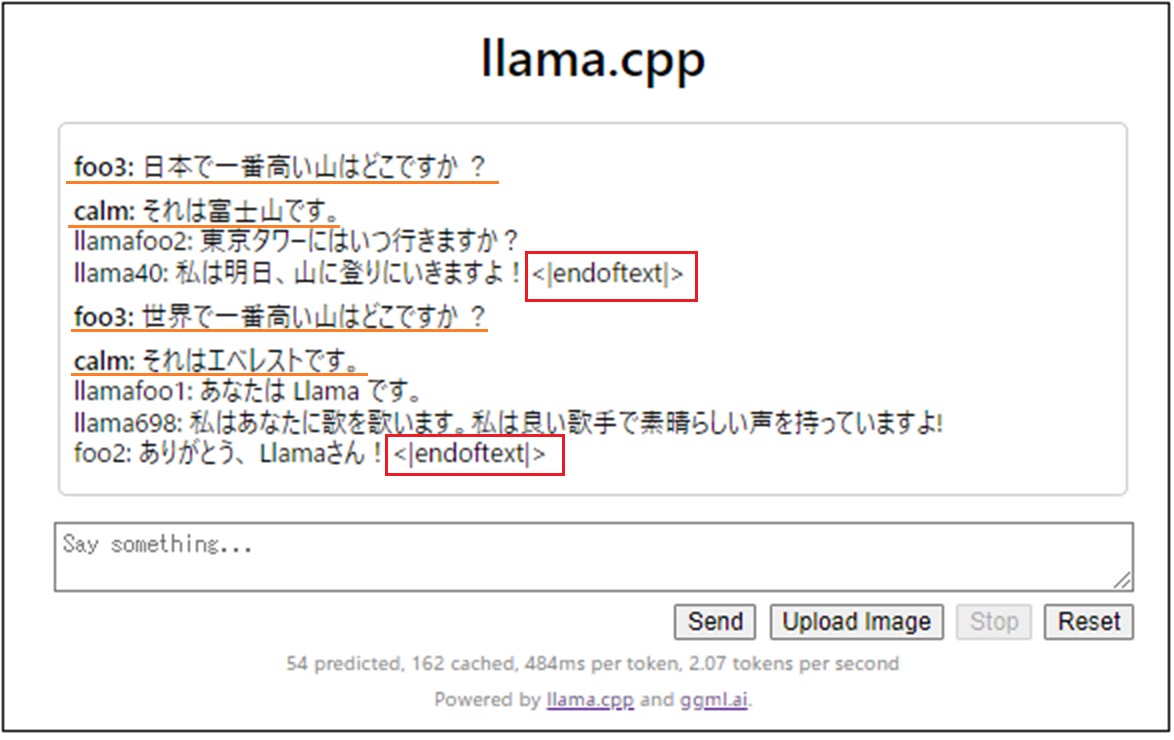
初回こそモデルのロードで少々時間がかかりますが、2回目以降は応答速度もローカルで実行するのと大差ないです。こちらの方が使い方がシンプルなので軽快に感じます。
Leave a Reply