
シングルボードコンピュータ(SBC)で小規模言語モデル(SLM)の量子化版を使ってみるではllama.cppを使ってみましたが、ここではllama.cpp のPythonバインディングを使ってみます。
NVIDIAのシングルボードコンピュータJetson Xavier NX にllama-cpp-python をインストールして、CPUのみの場合とGPU を使った場合のパフォーマンスを見てみました。
使う言語モデルはMivrosoft のPhi-3-mini の量子化版。
llama-cpp-python は前回と同じDocker イメージ(nvcr.io/nvidia/l4t-pytorch:r35.2.1-pth2.0-py3)を使ったコンテナーにインストールして使います。
今回の結果だけを見ると、CPUのみの場合もGPUを使った場合も応答時間にそんなに差はなかったです。
また、NXにはいくつかのPowerモードがあります。今回は10W 4Core と20W 6Core を試しましたがそんなに有意な差はありませんでした。
Jetson Xavier NX
OSイメージはJetpack 5.1.2 です。

現在は在庫のみで新規の販売は終了しています。Orin Nano ならこのバージョンのJetpack が使えるはずです。Appendix参照
データフォルダーを作って、そこにphi-3-miniの4bit量子化モデルをHuggingFaceからダウンロードしておきます。
|
1 2 3 4 |
mkdir ~/models cd ~/models wget https://huggingface.co/microsoft/Phi-3-mini-4k-instruct-gguf/resolve/main/Phi-3-mini-4k-instruct-q4.gguf |
CPU only
Docker イメージを使ってmy_llama1という名前のコンテナを作成します。
コンテナは先に作成したデータフォルダー(models)をマウントしています。このパスのユーザー名(jetson)はご自分のユーザー名で置き換えてください
sudo docker create -it --runtime=nvidia --name=my_llama1 --network host -v /home/jetson/models:/work nvcr.io/nvidia/l4t-pytorch:r35.2.1-pth2.0-py3
コンテナを起動し環境を整えた後、llama-cpp-python をCPUのみ使用するモードでインストールします。
|
1 2 3 4 5 6 7 8 9 10 |
sudo docker start -i my_llama1 apt update apt upgrade -y python3 -m pip install --upgrade pip pip install protobuf==3.3.0 //llama-cpp-pythonインストール pip install llama-cpp-python --extra-index-url https://abetlen.github.io/llama-cpp-python/whl/cpu |
Python コンソールを起動
>python3
プロンプトは「気分をよくする方法は?」です。Phi-3-miniは英語環境で学習してますが、日本語も理解できるようですのでプロンプトは日本語を使っています。。
n_gpu_layersの値は、分からなかったので-1にしています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
from llama_cpp import Llama llm = Llama( model_path="/work/Phi-3-mini-4k-instruct-q4.gguf", n_gpu_layers=-1, seed=1337, n_ctx=2048, ) output = llm( "Q: 気分をよくする方法は? A: ", max_tokens=320, stop=["Q:", "\n"], echo=True ) print(output) |
結果
だいたい初回は一分弱で応答が返ってきました。
左がコンテナの画面
右はJTOP(Jetson Stats)のモニターの画面です。
CPUはフルに使われています。
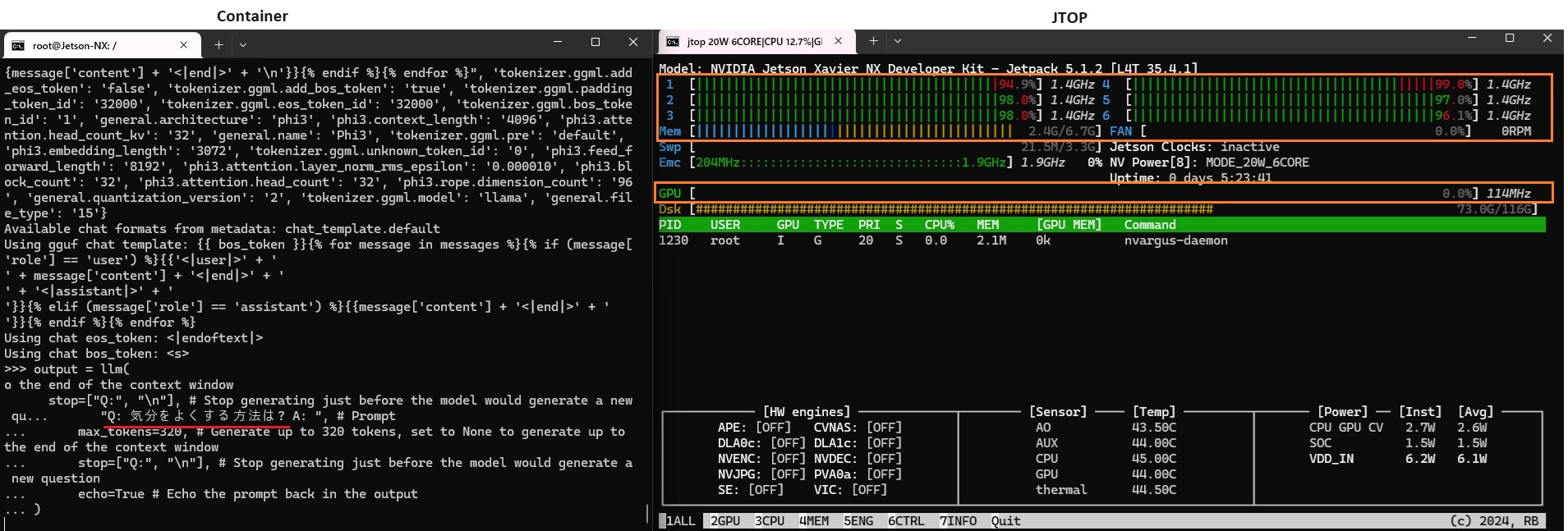
GPUは全く使われていません。
GPU + Server
Docker イメージを使ってmy_llama2という名前のコンテナを作成しています。
sudo docker create -it --runtime=nvidia --name=my_llama2 --network host -v /home/jetson/models:/work nvcr.io/nvidia/l4t-pytorch:r35.2.1-pth2.0-py3
コンテナを起動し、環境を整えた後llama-cpp-python をGPUを使用しServerとして起動するモードでインストールします。
アップデート後、まずcURLとjqをインストールしておいて、その後アップグレードを実行しています。これはアップグレード後にcURLとjqをインストールしようとするとエラーが起きるためです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
sudo docker start -i my_llama2 apt update apt install curl jq apt upgrade -y python3 -m pip install --upgrade pip pip install protobuf==3.3.0 pip install --upgrade numpy //llama-cpp-pythonをServerモードでインストール export LLAMA_CUBLAS=1 FORCE_CMAKE=1 CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python[server] |
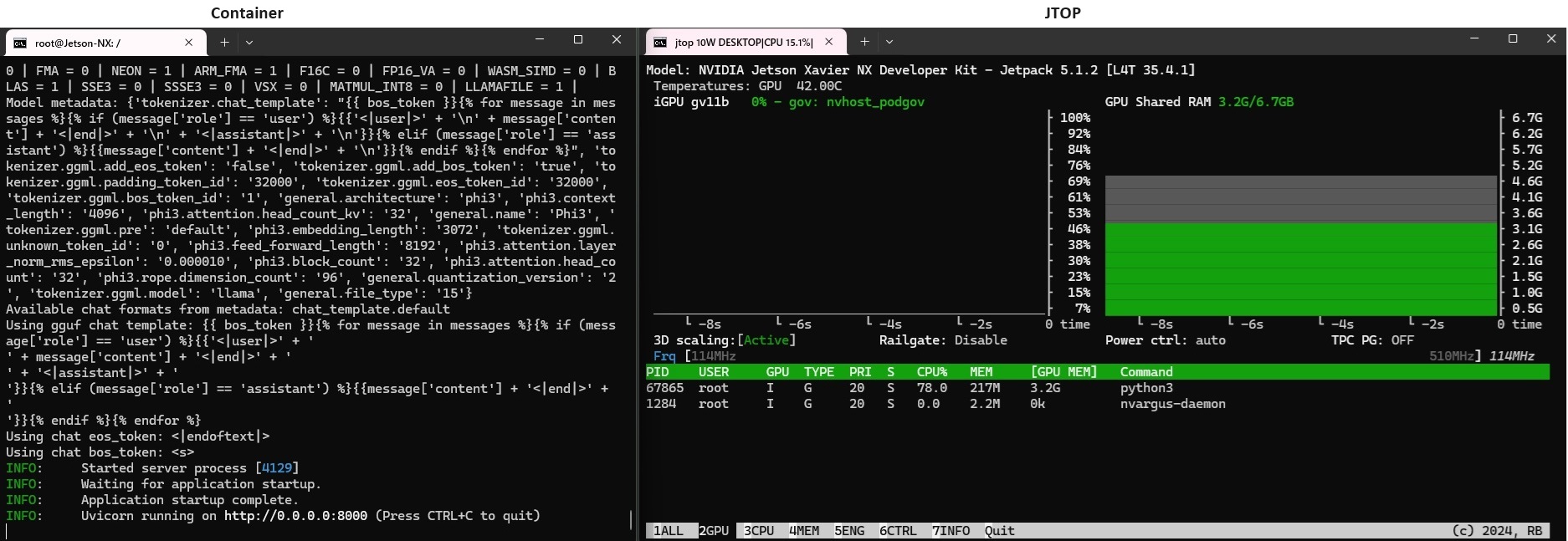
llama-cpp-pythonをバックグラウンドモードで起動(ポート番号は8000を使用)。
python3 -m llama_cpp.server --model /work/Phi-3-mini-4k-instruct-q4.gguf --n_gpu_layers -1 --host 0.0.0.0 --port 8000 &
起動を確認
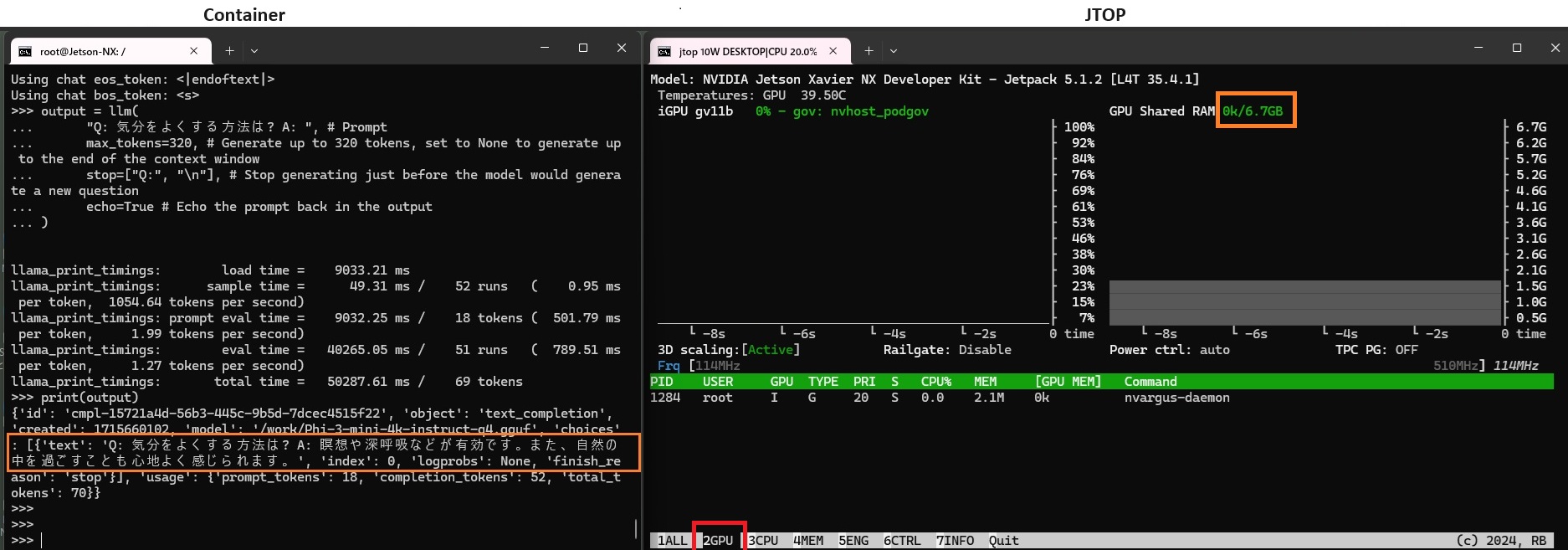
左がコンテナ画面、緑のinfoが表示されていれば起動しています。
右の画面はjtopのGPUモニター、GPUが使われています。
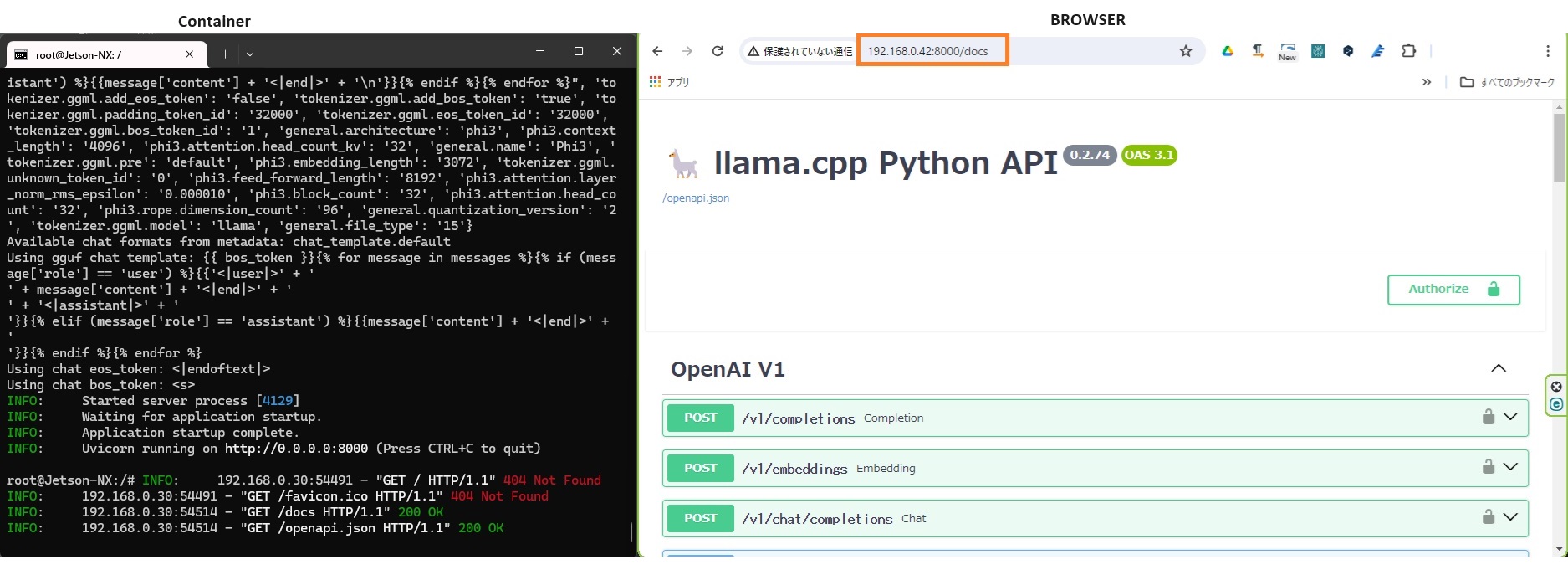
他の端末のブラウザーからドキュメントを確認してみます。
<JetsonのIPアドレス>:8000/docs
ローカルで推論実行
一旦リターンキーを押して、curlでプロンプト(”Tell me how to feel better? Please answer in Japanese.”)をhttpリクエストします。
curl -s -XPOST -H 'Content-Type: application/json' localhost:8000/v1/chat/completions -d '{"messages": [{"role": "user", "content": "Tell me how to feel better? Please answer in Japanese."}]}' | jq
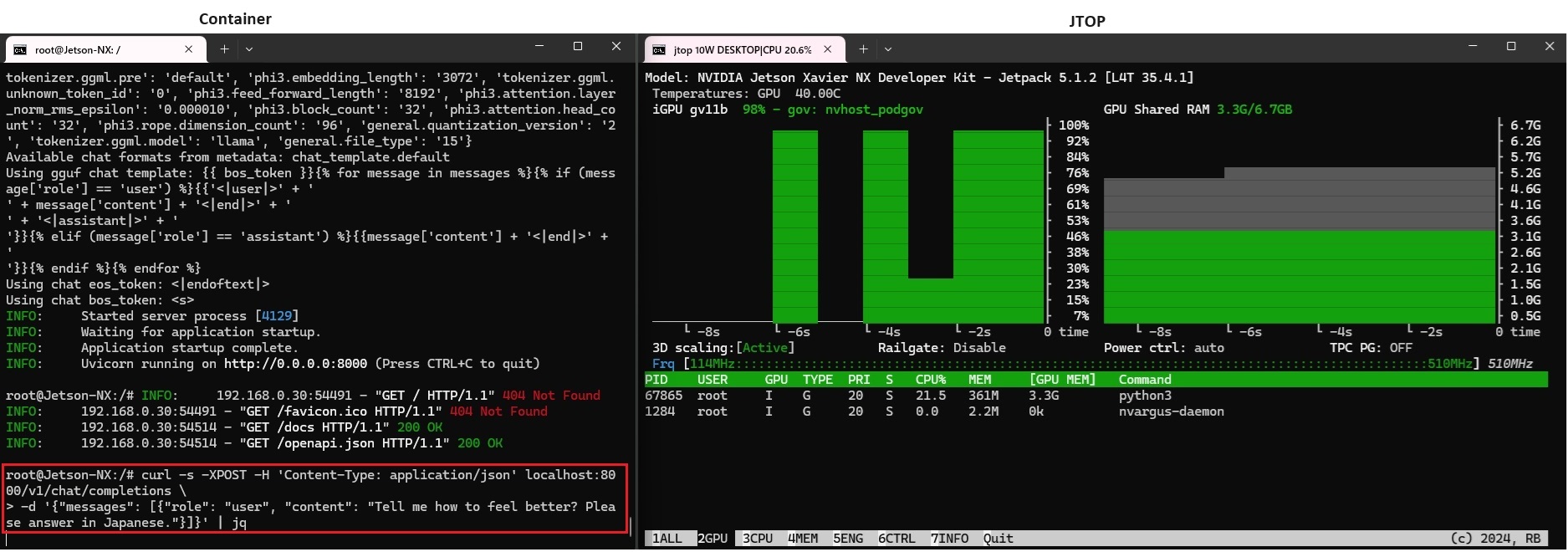
CPU のみの場合とさほど変わらない時間で応答が返ってきました。
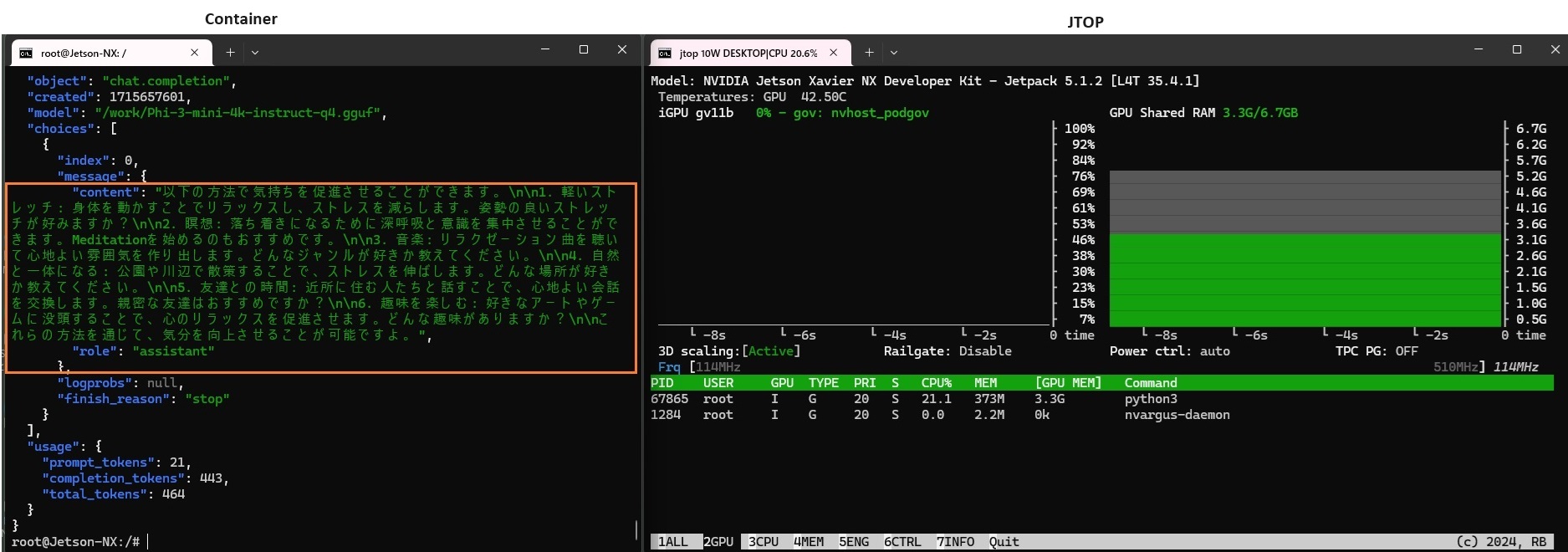
では、他の端末からリクエストしてみます。
未だの場合はcURLとjqをインストールしておきます。
|
1 |
sudo apt install curl jq |
Jetson のIPアドレスでリクエストします。
curl -s -XPOST -H 'Content-Type: application/json' 192.168.0.42:8000/v1/chat/completions -d '{"messages": [{"role": "user", "content": "Where is the capital of Japan? Please answer in Japanese."}]}' | jq
以下は、ラズパイ5のターミナルです。
cURL とjqをインストールした後に、curlでhttpリクエスト発行。返ってきたjsonをjqで表示しています。
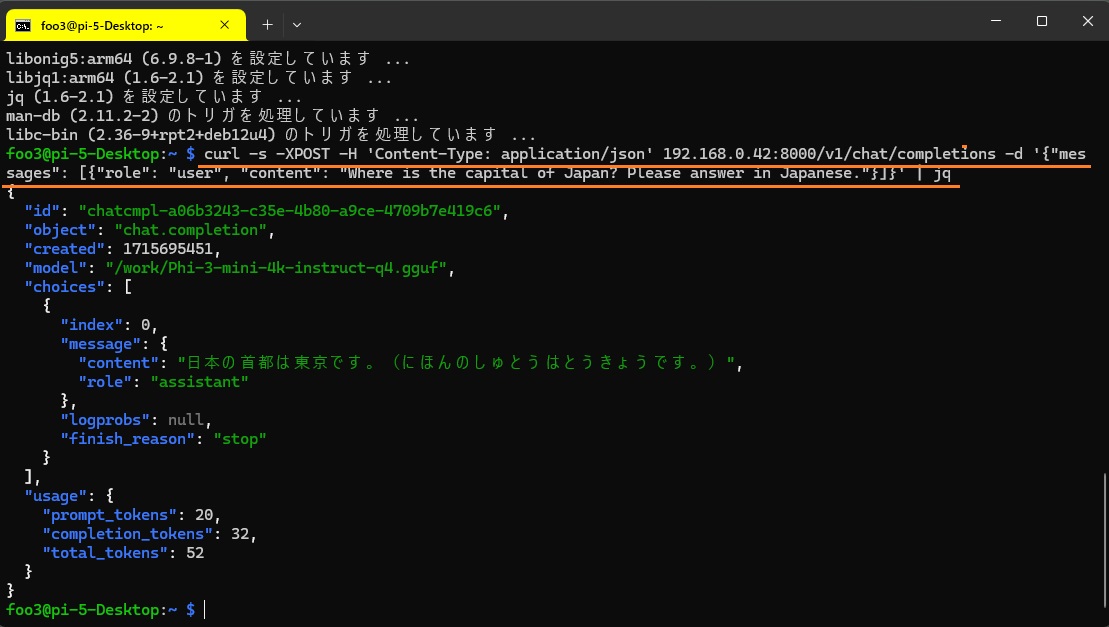
GPU
Docker イメージを使ってmy_llama3という名前のコンテナを作成しています。
sudo docker create -it --runtime=nvidia --name=my_llama3 --network host -v /home/jetson/models:/work nvcr.io/nvidia/l4t-pytorch:r35.2.1-pth2.0-py3
コンテナを起動し環境を整えた後、llama-cpp-python をGPUのみを使用して起動するモードでインストールします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
sudo docker start -i my_llama3 apt update apt upgrade -y python3 -m pip install --upgrade pip pip install protobuf==3.3.0 pip install --upgrade numpy export LLAMA_CUBLAS=1 FORCE_CMAKE=1 CMAKE_ARGS="-DLLAMA_CUBLAS=on" //llama-cpp-pythonインストール pip install llama-cpp-python //アップグレード・再ビルドする場合 pip install llama-cpp-python --upgrade --force-reinstall --no-cache-dir |
Pythonコンソール起動
>python3
|
1 2 3 4 5 6 |
from llama_cpp import Llama llm =Llama(model_path="/work/Phi-3-mini-4k-instruct-q4.gguf", n_gpu_layers=-1) prompt = f""" """ |
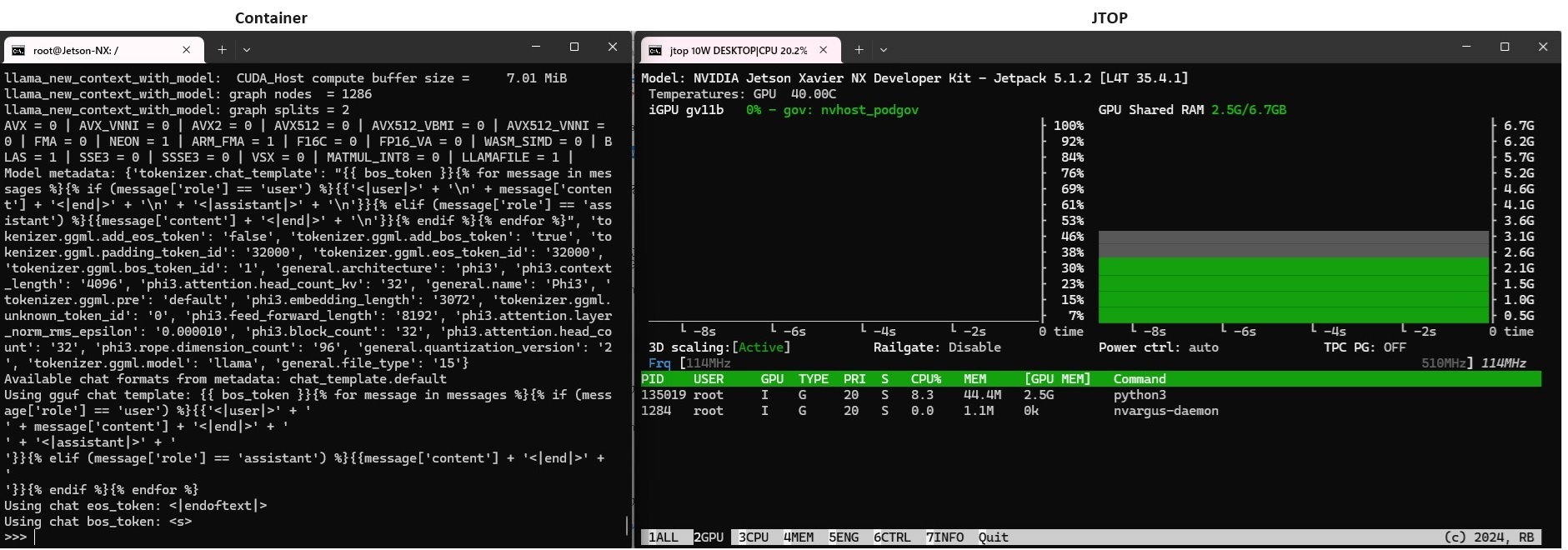
プロンプトを発行して応答を得ます。
|
1 2 3 4 5 6 7 |
output = llm( "Q: 日本の首都はどこですか? A: ", max_tokens=320, stop=["Q:", "\n"], echo=True ) print(output) |
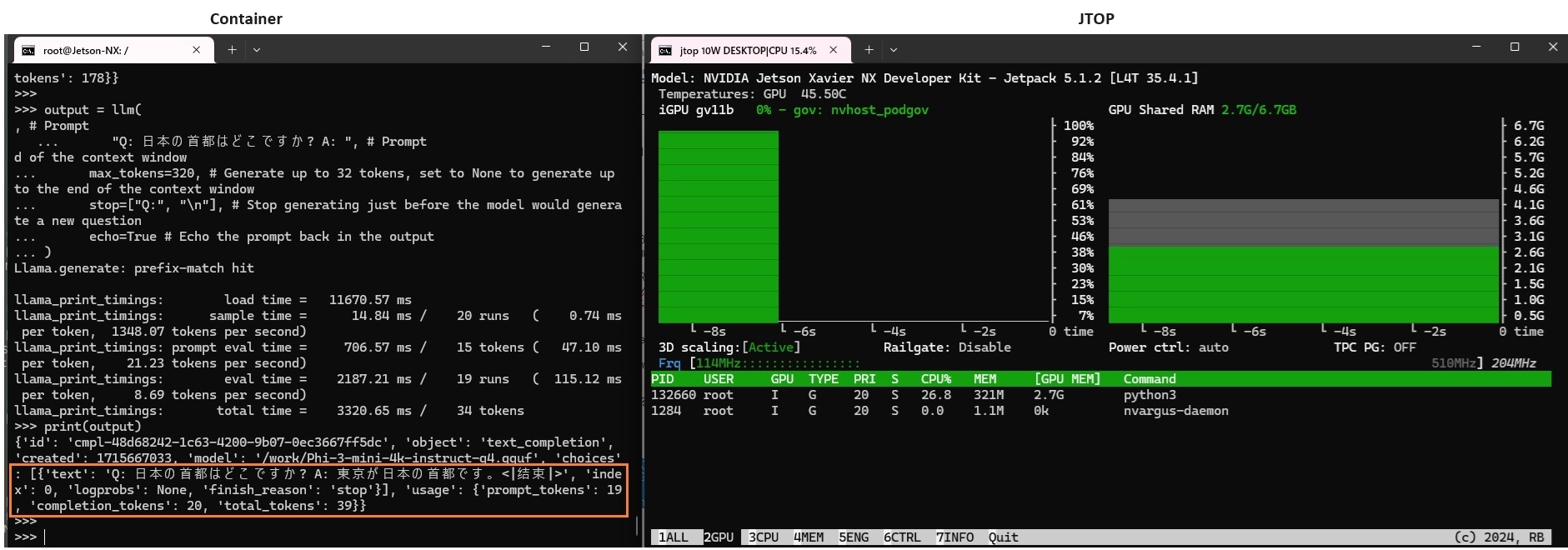
Appendix
Jetson Xavier NX は残念ながらすでに販売終了しています。
後継と考えられるのはOrin Nano です。TOPSだけ見てみると4GB版で同等、8GB版で倍くらいのパフォーマンスのようです。
spec
参考
Llama 2をJetson Orin Nanoで起動してみる
Leave a Reply