
オフロード画像のセグメンテーションチャレンジのチュートリアルをやってみます。
学習はクラウド、推論はエッジデバイスを使ってみます。
注:コンペは2021/02/11でクローズされています。
学習(トレーニング)にはGoogle ColabとGoogle Driveを使います。

推論実行はJetson Nano を使います。

画像データはColabにアップしておくと12時間ルールで消去されてしまうので、Googleドライブにアップしておき、実行時にマウントして使用します。
モデルを改良しながら学習すると、12時間ではすまないと思われるので、こうしておきます。
Google Drive は15GBまでは無償で利用できます。
Google Claob の環境はどんな感じでしょう。
CPU
vendor_id : GenuineIntel
cpu family : 6
model : 79
model name : Intel(R) Xeon(R) CPU @ 2.20GHz
stepping : 0
microcode : 0x1
cpu MHz : 2199.998
cache size : 56320 KB
GPU
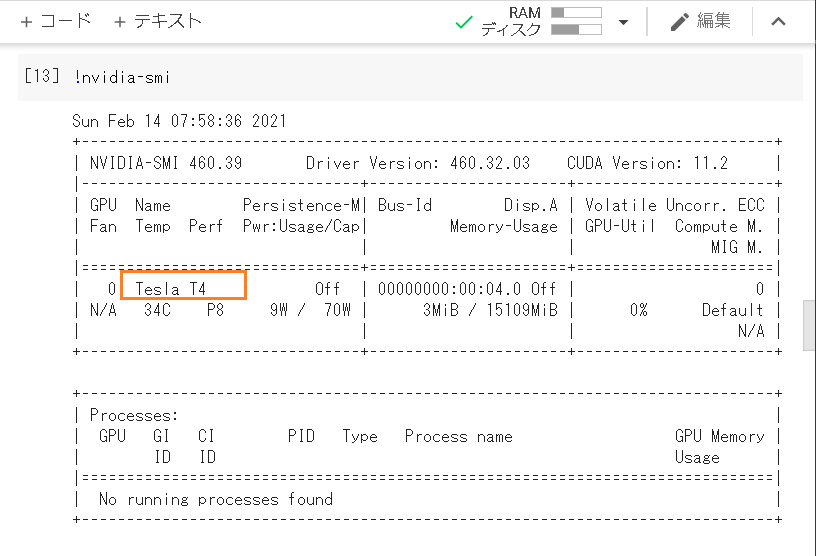
いろいろなGPUが優先度付きながらランダムに割り当てられるようです。k80とかp100とか。
今回はT4が割り当てられています。
その他
Python、ライブラリなど
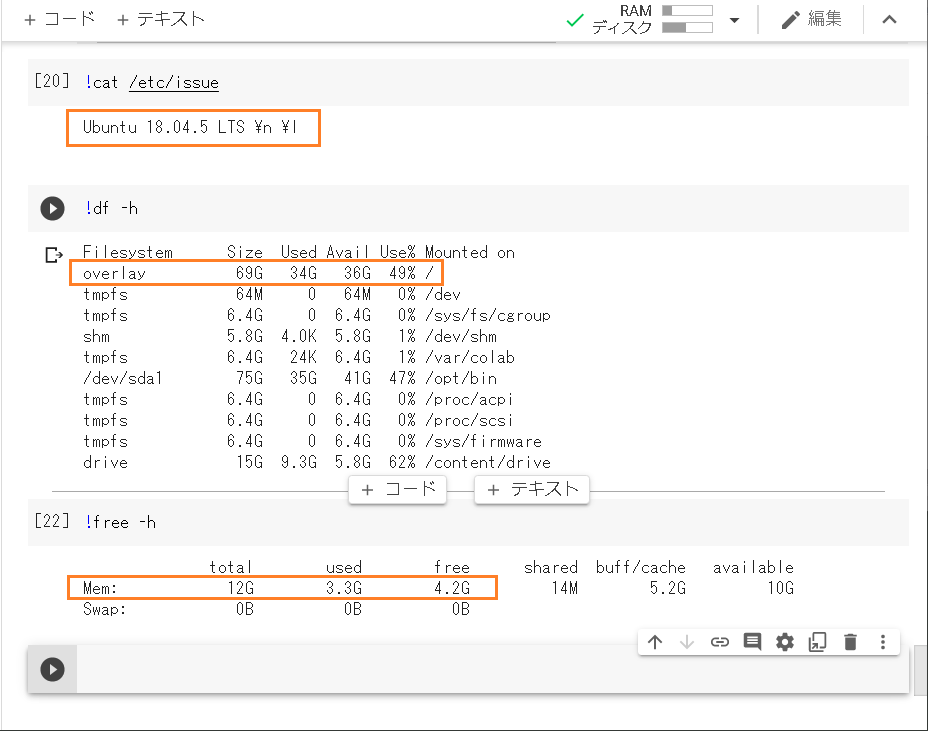
OS:Ubuntu 18.04,5 LTS
言語: Python==3,6,9
ライブラリ:
numpy==1.19.5
pandas== 1.1.5
matplotlib==3.2.2
torch==1.7.0+cu101
torchvision==0.8.1+cu101
Google Drive にSIGNATEから降ろしてきたoff_roadデータをアップロードしておきます。だいたい7GBちょっとです。
注:Google DriveにアップしたSIGNATEのデータはルールに基づくとコンペ終了後は削除しておきましょう。
Colabにアクセスして以下を実行
1:Notebookを新規作成
2:ランタイムー>ランタイムのタイプを変更ー>GPUを選んで保存。
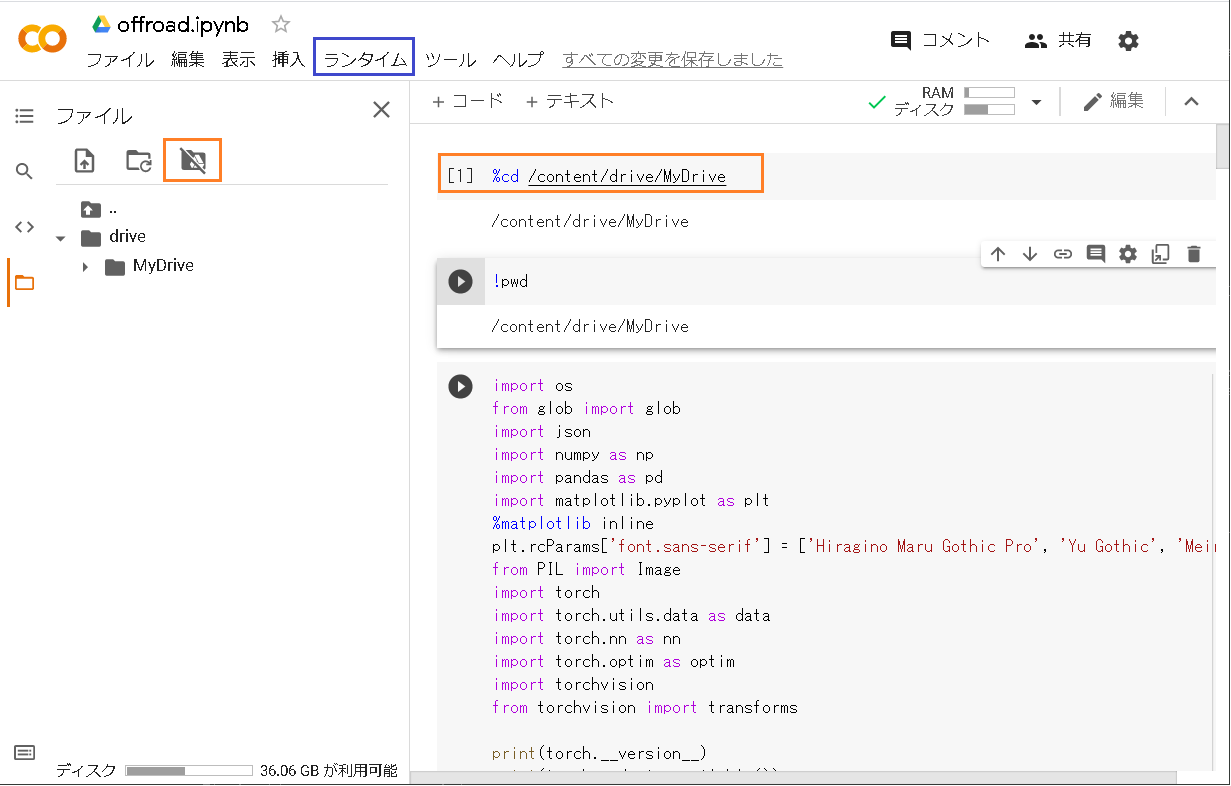
3:Google Driveをマウントしておきます。
4:カレントドライブを変更してoff_roadデータを読めるようします。
5:コードをコピペしてトレーニング実行開始
実行時間
ColabとDriveはネットワーク経由でデータをやり取りする場合、データ読み込みは2か所あってそれぞれで1時間ちょっとかかります。
トレーニングの実行は5epochで7時間弱、1epoch あたり1時間20~30分といったところ。
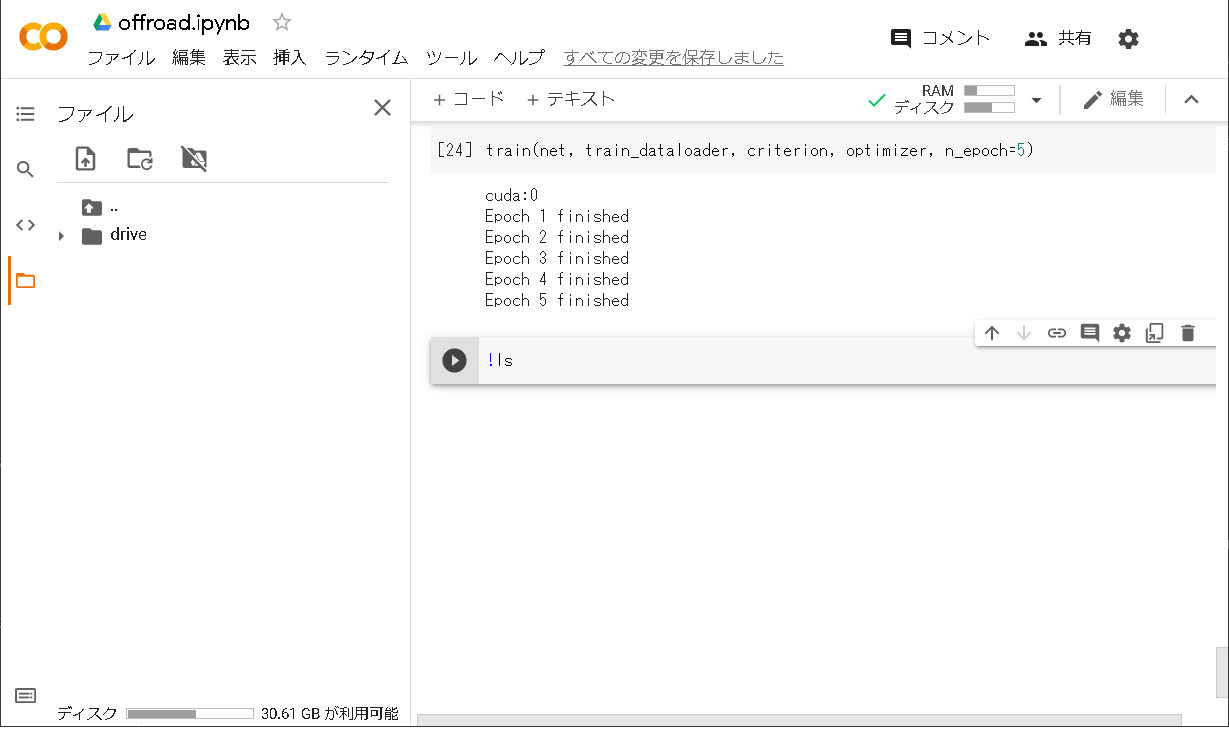
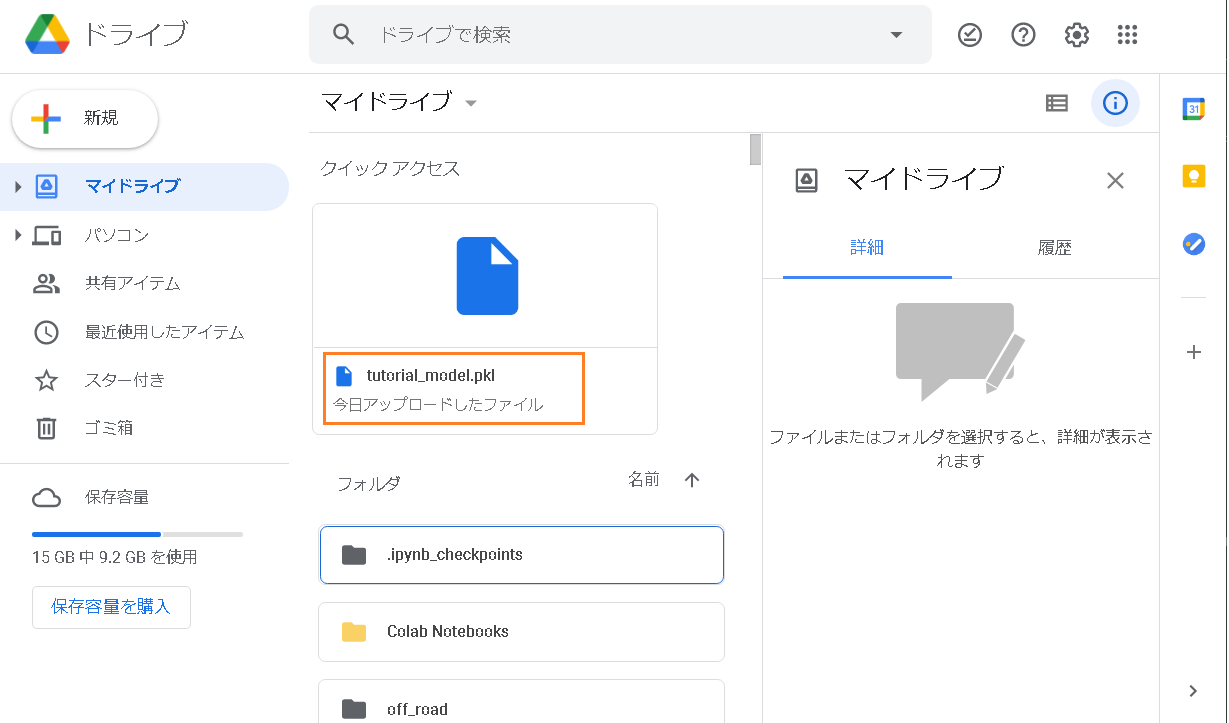
終了後トレーニン済みモデルがpickle化されてGoogle Driveに保存されます。
推論実行のエッジデバイスとしてJetson Nano を使います。
トレーニング済みのモデルデータ(tutorial_model.pkl)をJetson に転送しておきます。

コンテナを作成してそこで推論を実行します。
推論に必要なファイルを置いておくディレクトリをホストに作っておきます。
|
1 2 |
mkdir ~/work-offroad cd ~/work-offroad |
work-offroadに以下のファイルを置いておきます。
画像データはprecision_test_imagesフォルダーとtrain_annotations_Aフォルダーからコピー
tutorial_model.pkl
precision_test_image_0000.png
train_annotation_A0000.png
NVIDIAが用意している、Pytorchがインストールされたイメージを引っ張ってきます。
|
1 |
sudo docker pull nvcr.io/nvidia/l4t-pytorch:r32.4.4-pth1.6-py3 |
my_offroadという名前でコンテナー作成
sudo docker create -it --gpus all --name=my_offroad --network host -v "/home/jetson/work-offroad":"/work" nvcr.io/nvidia/l4t-pytorch:r32.4.4-pth1.6-py3
コンテナで作業
|
1 |
sudo docker start -i my_offroad |
アップデート&アップグレードしておきます。
|
1 2 3 |
apt update apt upgrade -y python3 -m pip install --upgrade pip |
イメージには以下のライブラリが無いので追加
|
1 2 |
pip3 install pandas pip3 install matplotlib |
環境
OS:Ubuntu 18.04,5 LTS
言語: Python==3,6,9
ライブラリ:
numpy==1.19.2
pandas== 1.1.5
matplotlib==3.2.4
torch==1.6.0
torchvision==0.7.0a0+78ed10c
Jupyterlabをインストール
|
1 |
pip3 install jupyterlab |
ディレクトリを移動しておきます。
|
1 |
cd /work |
Jupyterlabを起動
|
1 |
jupyter lab --ip=0.0.0.0 --allow-root |
ブラウザーからJupyter Notebook を開きます。
以下は例です。tokenはJupyterlabを起動した際に表示されます。
例
http://127.0.0.1:8888/lab?token=449b13bce5bc9d0e6c27b8abdd5745c85dd39f599d9fb781
ライブラリを読み込んで、配列を作っておきます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
import os from glob import glob import json import numpy as np import pandas as pd import matplotlib.pyplot as plt %matplotlib inline plt.rcParams['font.sans-serif'] = ['Hiragino Maru Gothic Pro', 'Yu Gothic', 'Meirio', 'Takao', 'IPAexGothic', 'IPAPGothic', 'VL PGothic', 'Noto Sans CJK JP'] from PIL import Image import torch import torch.utils.data as data import torch.nn as nn import torch.optim as optim import torchvision from torchvision import transforms print(torch.__version__) print(torch.cuda.is_available()) # 評価対象カテゴリ eval_names = ('road','dirt road', 'other obstacle') eval_colors = ((128, 64, 128), (255, 128, 128), (0, 0, 70)) |
# 学習済みモデルの読み込み
|
1 |
net = pd.read_pickle("tutorial_model.pkl") |
# 前処理クラスの定義
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
class OffRoadTransform(): def __init__(self, image_size, mean, std): self.image_size = image_size self.mean = mean self.std = std def __call__(self, image, annotation): # リサイズ image = image.resize((self.image_size[1], self.image_size[0])) annotation = annotation.resize((self.image_size[1], self.image_size[0])) # テンソル化&標準化 image = transforms.functional.to_tensor(image) image = transforms.functional.normalize(image, self.mean, self.std) # アノテーション画像の色(RGB)情報を以下のように対応するようマッピングし、2次元の配列に変換する """ road(128, 64, 128) -> 1 dirt road(255, 128, 128) -> 2 other obstacle(0, 0, 70) -> 3 上記以外 -> 0 """ annotation = np.array(annotation) converted_annotation = np.zeros(annotation.shape[:-1]) for i, eval_color in enumerate(eval_colors): mask = (annotation==eval_color).sum(axis=2)==3 converted_annotation[mask] = i+1 annotation = torch.from_numpy(converted_annotation) return image, annotation |
推論実行
画像データの読み込みのパスは適宜変更してください。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
# デバイスの設定 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") net.to(device) net.eval() # 前処理クラスのインスタンス化 test_transform = OffRoadTransform(image_size=(270, 480), mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)) # 画像データの読み込み test_image_0000 = Image.open('off_road/precision_test_images/precision_test_image_0000.png') dummy_annotation = Image.open('off_road/train_annotations_A/train_annotation_A0000.png') image_transformed, _ = test_transform(test_image_0000, dummy_annotation) image_transformed = image_transformed.unsqueeze(0) image_transformed = image_transformed.to(device) # 推論の実行 prediction = net(image_transformed)['out'] prediction = prediction[0].to('cpu').detach().numpy() prediction = np.argmax(prediction, axis=0).astype('uint8') prediction = np.array(Image.fromarray(prediction).resize([1920, 1080])) # 推論結果をRGB画像に変換 RGB = np.zeros([1080, 1920, 3], dtype='uint8') for i, color in enumerate(eval_colors): mask = prediction==i+1 RGB[mask] = color RGB_prediction = np.array(Image.fromarray(RGB).resize([1920, 1080])) # 可視化 fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(15, 10)) axes[0].imshow(test_image_0000) axes[0].set_title('元画像') axes[1].imshow(RGB_prediction) axes[1].set_title('予測結果') |
Jetson Nano だと、フツーに推論すると1分くらいかかります。jetson_clocksでCPU・CPUに実行を最大化しておけば5秒くらいです。

Next
推論に時間がかかりすぎですね。
NVIDIAのTensotRT が使えないか検討してみます。
Appendix
学習データのディレクトリ構成

フルコード
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 |
# ライブラリのインポート import os from glob import glob import json import numpy as np import pandas as pd import matplotlib.pyplot as plt %matplotlib inline plt.rcParams['font.sans-serif'] = ['Hiragino Maru Gothic Pro', 'Yu Gothic', 'Meirio', 'Takao', 'IPAexGothic', 'IPAPGothic', 'VL PGothic', 'Noto Sans CJK JP'] from PIL import Image import torch import torch.utils.data as data import torch.nn as nn import torch.optim as optim import torchvision from torchvision import transforms print(torch.__version__) print(torch.cuda.is_available()) # 評価対象カテゴリ eval_names = ('road','dirt road', 'other obstacle') eval_colors = ((128, 64, 128), (255, 128, 128), (0, 0, 70)) # データの読み込み。 #「学習用画像」「学習用アノテーション」「精度評価用画像」のファイルパスをそれぞれ取得。 train_images_path_list = sorted(glob('off_road/train_images_A/*.png')) train_annotations_path_list = sorted(glob('off_road/train_annotations_A/*.png')) precision_test_images_path_list = sorted(glob('off_road/precision_test_images/*.png')) print('================') print('学習用画像: ') print(len(train_images_path_list)) print(train_images_path_list[:5]) print('================') print('学習用アノテーション: ') print(len(train_annotations_path_list)) print(train_annotations_path_list[:5]) print('================') print('精度評価用画像: ') print(len(precision_test_images_path_list)) print(precision_test_images_path_list[:5]) # 画像データの可視化 # 画像の読み込み image_0000 = Image.open('off_road/train_images_A/train_image_A0000.png') annotation_0000 = Image.open('off_road/train_annotations_A/train_annotation_A0000.png') # 可視化 fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(15, 10)) axes[0].imshow(image_0000) axes[0].set_title('train_image_A0000.png') axes[1].imshow(annotation_0000) axes[1].set_title('train_annotation_A0000.png') plt.show() # 各評価対象カテゴリが含まれる画像枚数の確認 # 各評価対象カテゴリに該当する物体(road, dirt road, other obstacle)は、全ての画像内に登場するとは限りません。 # 各カテゴリの物体が各画像にどれほどの頻度で登場しているのかについて、学習用アノテーション画像を対象に確認しましょう。 count = { 'road': 0, 'dirt road': 0, 'other obstacle':0 } for train_annotation_path in train_annotations_path_list: image = np.array(Image.open(train_annotation_path)) for eval_name, eval_color in zip(eval_names, eval_colors): mask = (image==eval_color).sum(axis=2)==3 if np.any(mask): count[eval_name] += 1 plt.bar(count.keys(), count.values()) # モデリング # 前処理クラスの定義 # 前処理では、「画像の縮小」「テンソル化」「入力画像の標準化」「アノテーション画像の4カテゴリ表現への変換」などを行います class OffRoadTransform(): def __init__(self, image_size, mean, std): self.image_size = image_size self.mean = mean self.std = std def __call__(self, image, annotation): # リサイズ image = image.resize((self.image_size[1], self.image_size[0])) annotation = annotation.resize((self.image_size[1], self.image_size[0])) # テンソル化&標準化 image = transforms.functional.to_tensor(image) image = transforms.functional.normalize(image, self.mean, self.std) # アノテーション画像の色(RGB)情報を以下のように対応するようマッピングし、2次元の配列に変換する """ road(128, 64, 128) -> 1 dirt road(255, 128, 128) -> 2 other obstacle(0, 0, 70) -> 3 上記以外 -> 0 """ annotation = np.array(annotation) converted_annotation = np.zeros(annotation.shape[:-1]) for i, eval_color in enumerate(eval_colors): mask = (annotation==eval_color).sum(axis=2)==3 converted_annotation[mask] = i+1 annotation = torch.from_numpy(converted_annotation) return image, annotation # データセットの作成 # torch.utils.data.Datasetクラスを継承したクラスを作成します。 class OffRoadDataset(data.Dataset): def __init__(self, image_list, annotation_list, transform): self.image_list = image_list self.annotation_list = annotation_list self.transform = transform def __len__(self): return len(self.image_list) def __getitem__(self, index): image_filepath = self.image_list[index] annotation_filepath = self.annotation_list[index] image = Image.open(image_filepath) annotation = Image.open(annotation_filepath) image, annotation = self.transform(image, annotation) return image, annotation train_dataset = OffRoadDataset(train_images_path_list, train_annotations_path_list, transform=OffRoadTransform(image_size=(270, 480), mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225))) print(train_dataset.__getitem__(0)[0].shape) print(train_dataset.__getitem__(0)[1].shape) # データローダーの作成 batch_size = 8 train_dataloader = data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True) # モデルの初期化 # ここでは、torchvisionライブラリに標準で実装されているdeeplabv3_resnet101モデルを使用します。 net = torchvision.models.segmentation.deeplabv3_resnet101(pretrained=True) # 課題内容に合わせて、モデルの出力層のチャンネル数を変更しましょう。 # 3つの評価対象カテゴリ(「road」「dirt road」「other obstacle」)及び「その他」の合計4つのカテゴリに分類するということで # チャンネル数は4に変更します。 net.classifier[-1] = nn.Conv2d(256, 4, kernel_size=(1, 1), stride=(1, 1)) # 損失関数、最適化手法の定義 criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(net.parameters()) # モデルの学習を実行する関数の定義 # 全エポックの終了後に学習済みモデルのオブジェクトをpickleファイルとして保存するように設定します。 def train(net, train_dataloader, criterion, optimizer, n_epoch): device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") print(device) net.to(device) net.train() for epoch in range(1, n_epoch+1): epoch_train_loss = 0.0 optimizer.zero_grad() for images, annotations in train_dataloader: images = images.to(device) annotations = annotations.to(device) optimizer.step() optimizer.zero_grad() with torch.set_grad_enabled(True): outputs = net(images)['out'] loss = criterion(outputs, annotations.long()) loss.backward() print(f'Epoch {epoch} finished') pd.to_pickle(net, "tutorial_model.pkl") # 学習の実行 train(net, train_dataloader, criterion, optimizer, n_epoch=5) # 推論結果の可視化 # 学習済みのモデルを用いて推論を実行。 # 元画像と推論の結果生成された画像を並べて可視化することで、モデルの学習が上手くいっているのかを確認。 # 学習済みモデルの読み込み net = pd.read_pickle("tutorial_model.pkl") # デバイスの設定 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") net.to(device) net.eval() # 前処理クラスのインスタンス化 test_transform = OffRoadTransform(image_size=(270, 480), mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)) # 画像データの読み込み test_image_0000 = Image.open('off_road/precision_test_images/precision_test_image_0000.png') dummy_annotation = Image.open('off_road/train_annotations_A/train_annotation_A0000.png') image_transformed, _ = test_transform(test_image_0000, dummy_annotation) image_transformed = image_transformed.unsqueeze(0) image_transformed = image_transformed.to(device) # 推論の実行 prediction = net(image_transformed)['out'] prediction = prediction[0].to('cpu').detach().numpy() prediction = np.argmax(prediction, axis=0).astype('uint8') prediction = np.array(Image.fromarray(prediction).resize([1920, 1080])) # 推論結果をRGB画像に変換 RGB = np.zeros([1080, 1920, 3], dtype='uint8') for i, color in enumerate(eval_colors): mask = prediction==i+1 RGB[mask] = color RGB_prediction = np.array(Image.fromarray(RGB).resize([1920, 1080])) # 可視化 fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(15, 10)) axes[0].imshow(test_image_0000) axes[0].set_title('元画像') axes[1].imshow(RGB_prediction) axes[1].set_title('予測結果') |
Leave a Reply