
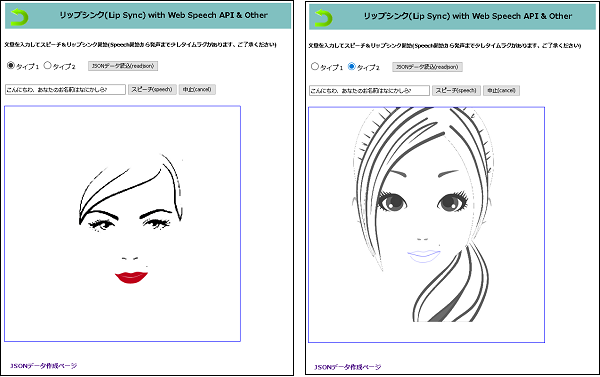
Web Speech APIの音声合成による発声と 自由曲線で描いたLipの変形を同期させます。
Web Speech APIの音声認識と合成を使って2Dキャラクターとの簡単な対話もやってみます。
3DのMMDとのからみはまた別途です。
2017/11/19 追加
母音「あ」の口形を修正。
“ぷ”や”ふ”などの口形は別に追加しました。
ま・ぱ・ば行では一度唇を閉じてから発声しています。
Catmull-Rom スプライン曲線で唇をトレースしてみました。唇データは最大23個のポイントで描かれています。
これらはいわゆる特徴点ではありません、それがちょっと問題かな。OpenCVなんかで取得できる特徴点で自由曲線が描ければハッピーなんですが。
位置合わせという意味でなら、OpenCVで取得した特徴点で作ったポリゴンと唇データのポリゴンの重心位置で合わせる…というのはどうかな?試してみます。
あいうえおん+1(sil)の7つのバリエーションでせいぜい23x7。
基本データ量はそれだけです。
変位量(相対座標)でも絶対座標でもどっちでも線形で変える分にはデータ量にそんなに差はないです。
カクカクした感じになるのは中間描画がないからで、つなぎの演算を挿入すればそれなりになる…..んじゃないかなぁと思います。
また、AmazonのAIサービスPollyにはスピーチマーク(viseme)があります、これで簡単なリップシンクもできる…..と思います。
visemeはsil(無音), PP, FF, TH, DD, kk, CH, SS, nn, RR, aa, E, ih, oh, ouの15種類が国際規格で決められているようですので、バリエーションをもっと増やさないといけませんが。
でも、欧米語なんか発音時に下唇の使い方が多様で数多いですが日本語はそんなに多くないと思います。せいぜい8~9個もあればいいんじゃないでしょうか?
あいうえおん+無音+う音の協調形など…..。
まあ、おいおいです。
でも、Catmull-Rom Spline Curveは唇のような曲線を描くのに向いてるのか?

モンロー曲線(Monroe Curve)をトレースしてみて、どのカーブが適正が高いか探してみるのもいいかも。
体の線はBezierだけど、唇は、Catmull-Romの方が……..とか。
赤は普通の赤ではなく、少し暗めのスカーレット、錆朱色というやつです、鹿島アントラーズの赤ですね。
New
Speechの音素のタイミングに合わせて、口形素の変形を行っています。
漢字も使える通常入力版、口形素を増やして音声ピッチも変えてます。
口形素はアフィン変換しているだけなので、画像はいろいろに変えられます。
新規作成ページをつくりました。
ここで作ったJSONファイルを読み込めるようにしました。
なまっているのは変えられませんでした。
OpenJTalkを使いたいです。MMDならできるんですけど、ここではは2Dにこだわっていきます。
OpenJTalkもCeVIOと同じでHMM(*)を使ってます。
3Dにする場合は、three.js + MMD + OpenJTalk……(?)
初回起動時は発声が数秒遅れます、ご了承ください。
Next
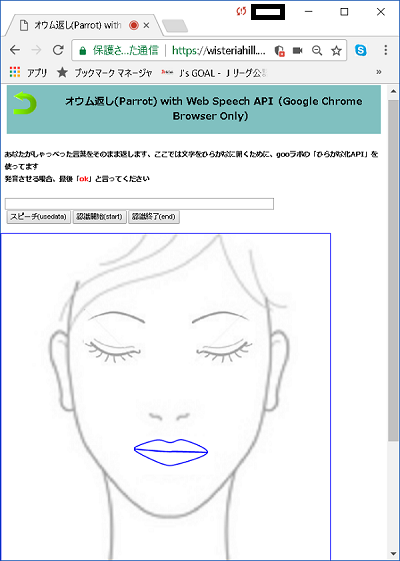
リップシンク with Web Speech API ではAPIの音声合成を使っていますが、次は音声認識を使って発音させてみます。
Web Speech APIの音声認識は巷で言われている程に精度が低いとは感じられませんね。
ちなみに、音声認識などを単体で試せるページを作っておきました。
AIサービスとは比較できませんが、フリーで使えるライブラリとしてはよくできているんじゃないでしょうか?
また、ここでは発音とのリップシンクが眼目なので、すべての認識結果は一度「ひらがな」に開かれます、なので漢字変換の精度も必要なしですし。
ここが開発主体になってる? Speech API Community Group
ベータです。バグ満載ですが、一応アップ。Google Chromeにのみ対応。
PCにマイクをつないでおいてください。話しかけて最後に「ok」と言ったら、言葉をそのまま返します。okと言わなくても返す場合もあります(^^)。
マイクに話しかけて認識結果を表示するのに1~2秒ほどのタイムラグがあります。ちょっと待ってね。
モンローの場合なら、合成音源に向井真理子さんなんでしょうが、ここではそんな贅沢できません。合成音は一択です。CeVIOの音源が使えないかとも思ったのですがI/FがWindowsのアプリ用しかないのでdocomoに頼るしかないのかな?
目を閉じてますが、話すときには目を開けます。
Web Speech APIで対話
対話を合理的に行うには当然中間にAIを使うということになるのでしょうが、それだと当たり前すぎて全然面白くないですね。
なんかないか、考えてみます。
ところで、以下はリクルートがやってる無償サービスAIのTalk APIです。
日本語の質問を記述してCALLをクリックすれば応えてくれます、お試しにどうぞ。
ふざけんな、という応答が時々ありますが、APIがそうなっているんだからしようがない。要は、なんらかの方法でAPIを変えればいいだけ。人同士の会話でも冗談を言い合っている途中でまじめな話をしたい場合「何かを変える」でしょう?
作り方の問題すね。
音声合成をWebで使うとなると選択肢が狭まります。docomoなどのサービスを使うといつ有料になったり
停止になるか分からないですし。
OpenJTalkやOpenHRIをWebで使うとなるとコンパイルしてインストールせにゃならんが、レンタルサーバーだと許してくれんでしょうし。
ここはWeb Speech APIと、杉浦孔明さんとこのrospeexをだまって使わせてもらいます(^^)。
近々にオープンします。
会話API(Conversation API) 比較
*HMM
隠れマルコフモデル(Hidden Markov Model)
Leave a Reply