
機械学習がどんなものかを学ぶビデオ・レッスンです。
機械学習が何をしようとしているのかをコーディングを通して、教えてくれます。
GoogleのJosh Gordonさんのレッスンでシリーズものになっています。
その1回目
はじめに – 機械学習レシピ1
以下はムービーの説明を補足するヘルプです
Pythonとscikit-learnライブラリーを使った決定木のお話です。
環境
scikit-learnの依存ライブラリー
- NumPy
- Scipy
- Pandas
ムービーではMacOS + Python2を使っているようですが、WisteriaHillはMacを持っていないのでubuntu 16.04 LTS + Python3でやってみます。
$sudo pip3 install scikit-learn
$python3
>>>import sklearn
以下のようなエラーが出た場合
RuntimeWarning: numpy.dtype size changed, may indicate binary incompatibility. Expected 96, got 88
この警告を止めるコードが誤ってnumpyの1.14.5と1.15.0の間で削除されていたようです(バグです)。
この間のバージョンに相当する場合は、一度削除して
$sudo pip3 ununstall numpy
バージョン指定して再インストール(numpyを最新にします)
$sudo pip3 install numpy==1.15.1
バグはフィックスされています。
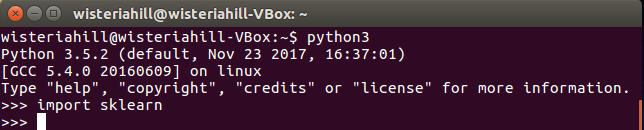
やってみます。
Training data
| Weight | Texture | Label |
| 150g | Bumpy | Orange |
| 170g | Bumpy | Orange |
| 140g | Smooth | Apple |
| 130g | Smooth | Apple |
↓
ムービーとは違って、配列はすべてかぎ括弧です。featuresの成分のセットに中括弧を使うとエラーになります
× features = [{140,”smooth”},{130,”smooth”},{150,”bumpy”},{170,”bumpy”}]
○ features = [[140,”smooth”],[130,”smooth”],[150,”bumpy”],[170,”bumpy”]]
labels = [“apple”,”apple”,”orange”,”orange”]
↓
features = [[140,1],[130,1],[150,0],[170,0]]
labels = [“apple”,”apple”,”orange”,”orange”]
ムービーとは少し変えて、「160gでbumpy(160で0)なものはどっち?」を推測します。
【test.py】
from sklearn import tree
features = [[140,1],[130,1],[150,0],[170,0]]
labels = [“apple”,”apple”,”orange”,”orange”]
clf = tree.DecisionTreeClassifier()
clf = clf.fit(features ,labels)
print (clf.predict([[160,0]]))
$python3 test.py
結果

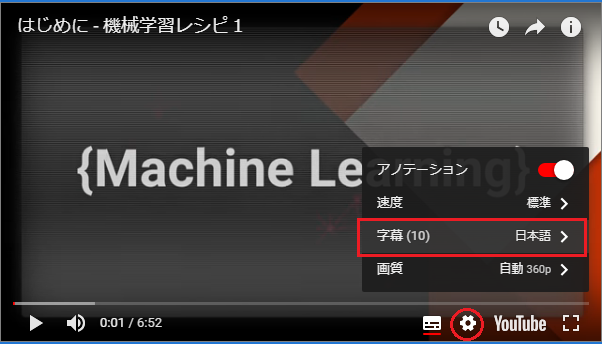
Youtubeの字幕(subtitles)の変更
English -> ?
下のギアアイコン->字幕->言語選択
Leave a Reply