
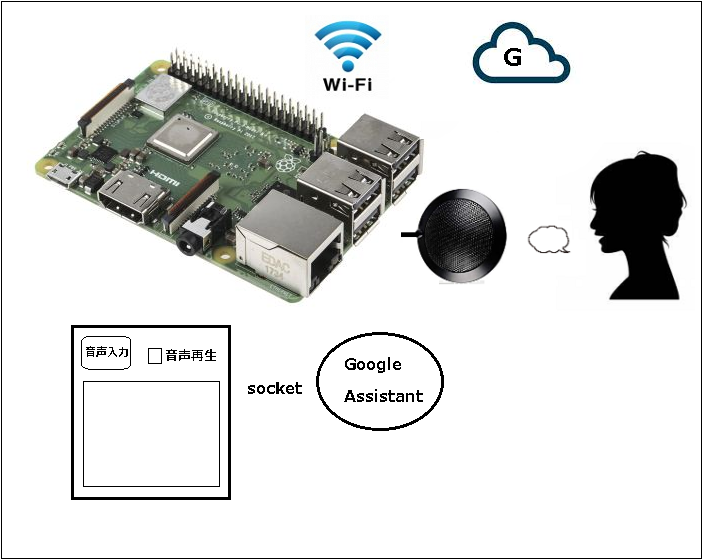
Google Assistant SDKのサンプルの中のpushtotalk.pyを使ってやってみます。
こんな感じ
やってみました…..の図
SDKのインストールとかはここを参照
Google Assistantのpushtotalk.pyとtextinput.pyは1つのものと書いてましたが、この2つを使えば、Google Assistantの音声認識の結果を、テキストでも取得できます。
目次
主に使用するコードはサンプルのpushtotalk.pyですが、これを以下のようにカスタマイズします。
(行番号は下のフルコードを参照してください)
① 210 – 211行
リクエストの発声の音声認識をtextで返してくれるところにコードを追加
if resp.speech_results:
txt_request = ‘ ‘.join(r.transcript for r in resp.speech_results)
② 201 – 207行
リクエストのtext化の最終処理はここでとっています
if resp.event_type == END_OF_UTTERANCE:
logging.info(‘End of audio request detected.’)
logging.info(‘Stopping recording.’)
self.conversation_stream.stop_recording()
print(txt_request)
③ 218 – 229行
リクエストに対するAssistantの応答をtextで返してもらうところではtextinput.pyからコードを拝借しています
ここで結果をGUIに送ります。
text_response = None
if resp.dialog_state_out.supplemental_display_text:
text_response = resp.dialog_state_out.supplemental_display_text
④ 232 – 242行
Googleからの応答の最終処理はここでとっています
if resp.dialog_state_out.conversation_state:
ここでtext_responseがNoneのままなら、Googleからの応答がなかったということになります
⑤ 245 – 274行
Assistantの音声応答部分、フラグで応答を流すか止めるかしています
if(speak_flag == True):
if len(resp.audio_out.audio_data) > 0:
・
・
・
⑥ 560 – 565行
ボタンのプッシュを待ち受けているところを変更します、ここで条件を与えればGoogleにリクエストを送るかどうか決められます
while True:
if(hotword_flag == True):
continue_conversation = assistant.assist()
wait_for_user_trigger = not continue_conversation
if once and (not continue_conversation):
break
⑥ 61 – 74行
通信用関数の送信部
⑦ 77 – 106行
通信用関数の受信部
⑧ 109 – 112行
GUIからの通信待ち受け開始
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 530 531 532 533 534 535 536 537 538 539 540 541 542 543 544 545 546 547 548 549 550 551 552 553 554 555 556 557 558 559 560 561 562 563 564 565 566 567 568 |
import concurrent.futures import json import logging import os import os.path import pathlib2 as pathlib import sys import time import uuid import click import grpc import google.auth.transport.grpc import google.auth.transport.requests import google.oauth2.credentials from google.assistant.embedded.v1alpha2 import ( embedded_assistant_pb2, embedded_assistant_pb2_grpc ) from tenacity import retry, stop_after_attempt, retry_if_exception #### from socket import socket, AF_INET, SOCK_STREAM import threading HOST = 'localhost' PORT1 = 60000 PORT2 = 60001 MAX_BUFFER = 2048 NUM_THREAD = 4 hotword_flag = False speak_flag = False #### try: from . import ( assistant_helpers, audio_helpers, browser_helpers, device_helpers ) except (SystemError, ImportError): import assistant_helpers import audio_helpers import browser_helpers import device_helpers ASSISTANT_API_ENDPOINT = 'embeddedassistant.googleapis.com' END_OF_UTTERANCE = embedded_assistant_pb2.AssistResponse.END_OF_UTTERANCE DIALOG_FOLLOW_ON = embedded_assistant_pb2.DialogStateOut.DIALOG_FOLLOW_ON CLOSE_MICROPHONE = embedded_assistant_pb2.DialogStateOut.CLOSE_MICROPHONE PLAYING = embedded_assistant_pb2.ScreenOutConfig.PLAYING DEFAULT_GRPC_DEADLINE = 60 * 3 + 5 #### #⑥ def responce_send(mess): while True: try: nani_sock = socket(AF_INET, SOCK_STREAM) nani_sock.connect((HOST, PORT2)) nani_sock.send(mess.encode('utf-8')) print ('responce_send:OK ') nani_sock.close() break except: #voice("populer","junbihaiikana") print ('responce_retry: ' + mess) break #⑦ def request_receive(): global hotword_flag global speak_flag sock = socket(AF_INET, SOCK_STREAM) sock.bind ((HOST, PORT1)) sock.listen (NUM_THREAD) print ('receiver ready, NUM_THREAD = ' + str(NUM_THREAD)) resp = r'{"resp1":"' + "assist_waked" + '","resp2":"' + "おはようございます" + '"}' responce_send(resp) while True: try: conn,addr = sock.accept() mess = conn.recv(MAX_BUFFER).decode('utf-8') conn.close() print('RECEIVED MESSAGE:' + mess) mess_list = mess.split("/") if(mess_list[0] == "assist_open"): hotword_flag = True if(mess_list[1] == "speak_open"): speak_flag = True elif(mess_list[1] == "speak_close"): speak_flag = False except: print('Receive Error') sock.close() #⑧ def request_receive_start(): #別スレッドで待ち受け th=threading.Thread(target=request_receive) th.start() class SampleAssistant(object): """Sample Assistant that supports conversations and device actions. Args: device_model_id: identifier of the device model. device_id: identifier of the registered device instance. conversation_stream(ConversationStream): audio stream for recording query and playing back assistant answer. channel: authorized gRPC channel for connection to the Google Assistant API. deadline_sec: gRPC deadline in seconds for Google Assistant API call. device_handler: callback for device actions. """ def __init__(self, language_code, device_model_id, device_id, conversation_stream, display, channel, deadline_sec, device_handler): self.language_code = language_code self.device_model_id = device_model_id self.device_id = device_id self.conversation_stream = conversation_stream self.display = display # Opaque blob provided in AssistResponse that, # when provided in a follow-up AssistRequest, # gives the Assistant a context marker within the current state # of the multi-Assist()-RPC "conversation". # This value, along with MicrophoneMode, supports a more natural # "conversation" with the Assistant. self.conversation_state = None # Force reset of first conversation. self.is_new_conversation = True # Create Google Assistant API gRPC client. self.assistant = embedded_assistant_pb2_grpc.EmbeddedAssistantStub( channel ) self.deadline = deadline_sec self.device_handler = device_handler def __enter__(self): return self def __exit__(self, etype, e, traceback): if e: return False self.conversation_stream.close() def is_grpc_error_unavailable(e): is_grpc_error = isinstance(e, grpc.RpcError) if is_grpc_error and (e.code() == grpc.StatusCode.UNAVAILABLE): logging.error('grpc unavailable error: %s', e) return True return False @retry(reraise=True, stop=stop_after_attempt(3), retry=retry_if_exception(is_grpc_error_unavailable)) def assist(self): """Send a voice request to the Assistant and playback the response. Returns: True if conversation should continue. """ global hotword_flag global speak_flag txt_request = "" print("<<Speak something>>") continue_conversation = False device_actions_futures = [] resp_list = [] self.conversation_stream.start_recording() logging.info('Recording audio request.') def iter_log_assist_requests(): for c in self.gen_assist_requests(): assistant_helpers.log_assist_request_without_audio(c) yield c logging.debug('Reached end of AssistRequest iteration.') # This generator yields AssistResponse proto messages # received from the gRPC Google Assistant API. for resp in self.assistant.Assist(iter_log_assist_requests(), self.deadline): assistant_helpers.log_assist_response_without_audio(resp) #② if resp.event_type == END_OF_UTTERANCE: logging.info('End of audio request detected.') logging.info('Stopping recording.') self.conversation_stream.stop_recording() print("REQUEST:" + txt_request) resp_list.append(txt_request) #① if resp.speech_results: txt_request = ' '.join(r.transcript for r in resp.speech_results) logging.info('Transcript of user request: "%s".', ' '.join(r.transcript for r in resp.speech_results)) #③ text_response = None if resp.dialog_state_out.supplemental_display_text: text_response = resp.dialog_state_out.supplemental_display_text text_response = text_response.replace("\n","。") print("RES:" + text_response) resp_list.append(text_response) if(len(resp_list) == 2): resp_voice = r'{"resp1":"' + resp_list[0] + '","resp2":"' + resp_list[1] + '"}' responce_send(resp_voice) resp_list = [] #④ if resp.dialog_state_out.conversation_state: if(text_response == None): #グーグルからの応答がない場合 resp_message = "none" resp_voice = r'{"resp1":"' + resp_list[0] + '","resp2":"' + resp_message + '"}' responce_send(resp_voice) print("NONE") hotword_flag = False #⑤ if(speak_flag == True): if len(resp.audio_out.audio_data) > 0: if not self.conversation_stream.playing: self.conversation_stream.stop_recording() self.conversation_stream.start_playback() logging.info('Playing assistant response.') self.conversation_stream.write(resp.audio_out.audio_data) if resp.dialog_state_out.conversation_state: conversation_state = resp.dialog_state_out.conversation_state logging.debug('Updating conversation state.') self.conversation_state = conversation_state if resp.dialog_state_out.volume_percentage != 0: volume_percentage = resp.dialog_state_out.volume_percentage logging.info('Setting volume to %s%%', volume_percentage) self.conversation_stream.volume_percentage = volume_percentage if resp.dialog_state_out.microphone_mode == DIALOG_FOLLOW_ON: continue_conversation = True logging.info('Expecting follow-on query from user.') elif resp.dialog_state_out.microphone_mode == CLOSE_MICROPHONE: continue_conversation = False if resp.device_action.device_request_json: device_request = json.loads( resp.device_action.device_request_json ) fs = self.device_handler(device_request) if fs: device_actions_futures.extend(fs) if self.display and resp.screen_out.data: system_browser = browser_helpers.system_browser system_browser.display(resp.screen_out.data) if len(device_actions_futures): logging.info('Waiting for device executions to complete.') concurrent.futures.wait(device_actions_futures) logging.info('Finished playing assistant response.') self.conversation_stream.stop_playback() return continue_conversation def gen_assist_requests(self): """Yields: AssistRequest messages to send to the API.""" config = embedded_assistant_pb2.AssistConfig( audio_in_config=embedded_assistant_pb2.AudioInConfig( encoding='LINEAR16', sample_rate_hertz=self.conversation_stream.sample_rate, ), audio_out_config=embedded_assistant_pb2.AudioOutConfig( encoding='LINEAR16', sample_rate_hertz=self.conversation_stream.sample_rate, volume_percentage=self.conversation_stream.volume_percentage, ), dialog_state_in=embedded_assistant_pb2.DialogStateIn( language_code=self.language_code, conversation_state=self.conversation_state, is_new_conversation=self.is_new_conversation, ), device_config=embedded_assistant_pb2.DeviceConfig( device_id=self.device_id, device_model_id=self.device_model_id, ) ) if self.display: config.screen_out_config.screen_mode = PLAYING # Continue current conversation with later requests. self.is_new_conversation = False # The first AssistRequest must contain the AssistConfig # and no audio data. yield embedded_assistant_pb2.AssistRequest(config=config) for data in self.conversation_stream: # Subsequent requests need audio data, but not config. yield embedded_assistant_pb2.AssistRequest(audio_in=data) @click.command() @click.option('--api-endpoint', default=ASSISTANT_API_ENDPOINT, metavar='<api endpoint>', show_default=True, help='Address of Google Assistant API service.') @click.option('--credentials', metavar='<credentials>', show_default=True, default=os.path.join(click.get_app_dir('google-oauthlib-tool'), 'credentials.json'), help='Path to read OAuth2 credentials.') @click.option('--project-id', metavar='<project id>', help=('Google Developer Project ID used for registration ' 'if --device-id is not specified')) @click.option('--device-model-id', metavar='<device model id>', help=(('Unique device model identifier, ' 'if not specifed, it is read from --device-config'))) @click.option('--device-id', metavar='<device id>', help=(('Unique registered device instance identifier, ' 'if not specified, it is read from --device-config, ' 'if no device_config found: a new device is registered ' 'using a unique id and a new device config is saved'))) @click.option('--device-config', show_default=True, metavar='<device config>', default=os.path.join( click.get_app_dir('googlesamples-assistant'), 'device_config.json'), help='Path to save and restore the device configuration') @click.option('--lang', show_default=True, metavar='<language code>', default='en-US', help='Language code of the Assistant') @click.option('--display', is_flag=True, default=False, help='Enable visual display of Assistant responses in HTML.') @click.option('--verbose', '-v', is_flag=True, default=False, help='Verbose logging.') @click.option('--input-audio-file', '-i', metavar='<input file>', help='Path to input audio file. ' 'If missing, uses audio capture') @click.option('--output-audio-file', '-o', metavar='<output file>', help='Path to output audio file. ' 'If missing, uses audio playback') @click.option('--audio-sample-rate', default=audio_helpers.DEFAULT_AUDIO_SAMPLE_RATE, metavar='<audio sample rate>', show_default=True, help='Audio sample rate in hertz.') @click.option('--audio-sample-width', default=audio_helpers.DEFAULT_AUDIO_SAMPLE_WIDTH, metavar='<audio sample width>', show_default=True, help='Audio sample width in bytes.') @click.option('--audio-iter-size', default=audio_helpers.DEFAULT_AUDIO_ITER_SIZE, metavar='<audio iter size>', show_default=True, help='Size of each read during audio stream iteration in bytes.') @click.option('--audio-block-size', default=audio_helpers.DEFAULT_AUDIO_DEVICE_BLOCK_SIZE, metavar='<audio block size>', show_default=True, help=('Block size in bytes for each audio device ' 'read and write operation.')) @click.option('--audio-flush-size', default=audio_helpers.DEFAULT_AUDIO_DEVICE_FLUSH_SIZE, metavar='<audio flush size>', show_default=True, help=('Size of silence data in bytes written ' 'during flush operation')) @click.option('--grpc-deadline', default=DEFAULT_GRPC_DEADLINE, metavar='<grpc deadline>', show_default=True, help='gRPC deadline in seconds') @click.option('--once', default=False, is_flag=True, help='Force termination after a single conversation.') def main(api_endpoint, credentials, project_id, device_model_id, device_id, device_config, lang, display, verbose, input_audio_file, output_audio_file, audio_sample_rate, audio_sample_width, audio_iter_size, audio_block_size, audio_flush_size, grpc_deadline, once, *args, **kwargs): global hotward_flag """Samples for the Google Assistant API. Examples: Run the sample with microphone input and speaker output: $ python -m googlesamples.assistant Run the sample with file input and speaker output: $ python -m googlesamples.assistant -i <input file> Run the sample with file input and output: $ python -m googlesamples.assistant -i <input file> -o <output file> """ # Setup logging. logging.basicConfig(level=logging.DEBUG if verbose else logging.INFO) # Load OAuth 2.0 credentials. try: with open(credentials, 'r') as f: credentials = google.oauth2.credentials.Credentials(token=None, **json.load(f)) http_request = google.auth.transport.requests.Request() credentials.refresh(http_request) except Exception as e: logging.error('Error loading credentials: %s', e) logging.error('Run google-oauthlib-tool to initialize ' 'new OAuth 2.0 credentials.') sys.exit(-1) # Create an authorized gRPC channel. grpc_channel = google.auth.transport.grpc.secure_authorized_channel( credentials, http_request, api_endpoint) logging.info('Connecting to %s', api_endpoint) # Configure audio source and sink. audio_device = None if input_audio_file: audio_source = audio_helpers.WaveSource( open(input_audio_file, 'rb'), sample_rate=audio_sample_rate, sample_width=audio_sample_width ) else: audio_source = audio_device = ( audio_device or audio_helpers.SoundDeviceStream( sample_rate=audio_sample_rate, sample_width=audio_sample_width, block_size=audio_block_size, flush_size=audio_flush_size ) ) if output_audio_file: audio_sink = audio_helpers.WaveSink( open(output_audio_file, 'wb'), sample_rate=audio_sample_rate, sample_width=audio_sample_width ) else: audio_sink = audio_device = ( audio_device or audio_helpers.SoundDeviceStream( sample_rate=audio_sample_rate, sample_width=audio_sample_width, block_size=audio_block_size, flush_size=audio_flush_size ) ) # Create conversation stream with the given audio source and sink. conversation_stream = audio_helpers.ConversationStream( source=audio_source, sink=audio_sink, iter_size=audio_iter_size, sample_width=audio_sample_width, ) if not device_id or not device_model_id: try: with open(device_config) as f: device = json.load(f) device_id = device['id'] device_model_id = device['model_id'] logging.info("Using device model %s and device id %s", device_model_id, device_id) except Exception as e: logging.warning('Device config not found: %s' % e) logging.info('Registering device') if not device_model_id: logging.error('Option --device-model-id required ' 'when registering a device instance.') sys.exit(-1) if not project_id: logging.error('Option --project-id required ' 'when registering a device instance.') sys.exit(-1) device_base_url = ( 'https://%s/v1alpha2/projects/%s/devices' % (api_endpoint, project_id) ) device_id = str(uuid.uuid1()) payload = { 'id': device_id, 'model_id': device_model_id, 'client_type': 'SDK_SERVICE' } session = google.auth.transport.requests.AuthorizedSession( credentials ) r = session.post(device_base_url, data=json.dumps(payload)) if r.status_code != 200: logging.error('Failed to register device: %s', r.text) sys.exit(-1) logging.info('Device registered: %s', device_id) pathlib.Path(os.path.dirname(device_config)).mkdir(exist_ok=True) with open(device_config, 'w') as f: json.dump(payload, f) device_handler = device_helpers.DeviceRequestHandler(device_id) @device_handler.command('action.devices.commands.OnOff') def onoff(on): if on: logging.info('Turning device on') else: logging.info('Turning device off') @device_handler.command('com.example.commands.BlinkLight') def blink(speed, number): logging.info('Blinking device %s times.' % number) delay = 1 if speed == "SLOWLY": delay = 2 elif speed == "QUICKLY": delay = 0.5 for i in range(int(number)): logging.info('Device is blinking.') time.sleep(delay) with SampleAssistant(lang, device_model_id, device_id, conversation_stream, display, grpc_channel, grpc_deadline, device_handler) as assistant: # If file arguments are supplied: # exit after the first turn of the conversation. if input_audio_file or output_audio_file: assistant.assist() return # If no file arguments supplied: # keep recording voice requests using the microphone # and playing back assistant response using the speaker. # When the once flag is set, don't wait for a trigger. Otherwise, wait. wait_for_user_trigger = not once #⑧ request_receive_start() #⑥ while True: if(hotword_flag == True): continue_conversation = assistant.assist() wait_for_user_trigger = not continue_conversation if once and (not continue_conversation): break if __name__ == '__main__': main() |
音声入力ボタンなどを配置したGUI
Assistantの応答が表示されます
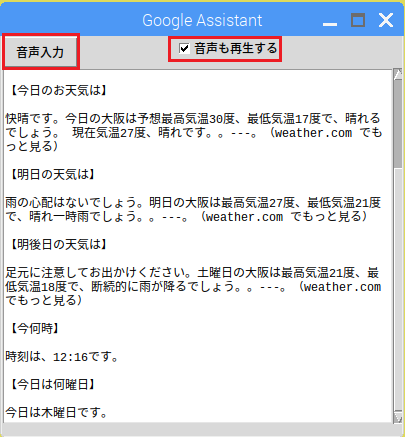
【Gui.py】
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 |
#!/usr/bin/env python3 # -*- coding: utf-8 -*- import tkinter import socket import threading import json import urllib.parse import subprocess import os HOST = 'localhost' PORT1 = 60000 PORT2 = 60001 MAX_BUFFER = 2048 NUM_THREAD = 4 def quit(): root.quit() root.destroy() os._exit(0) def assist_open(): print("OPEN") mes = "assist_open" if(bln.get()): mes += "/speak_open" else: mes += "/speak_close" send_message(mes) def send_message(mes): while True: try: s_sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s_sock.connect((HOST, PORT1)) s_sock.send(mes.encode('utf-8')) s_sock.close() break except: print ('error: ' + mess) break def show_responce(reception): obj = json.loads(reception) resp1 = obj['resp1'] resp2 = obj['resp2'] resp = "【" + resp1 + "】" + "\n\n" + resp2 print(resp) textBox.delete('1.0','end') textBox.insert('1.0',resp) toEnd() def toEnd(): textBox.see('end') def receive_responce(): r_sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) r_sock.bind ((HOST, PORT2)) r_sock.listen (NUM_THREAD) while True: try: conn,addr = r_sock.accept() reception = conn.recv(MAX_BUFFER).decode('utf-8') conn.close() print('RECEPT:' + reception) show_responce(reception) except: print('Receive Error') r_sock.close() def receive_start(): th=threading.Thread(target=receive_responce) th.start() root = tkinter.Tk() root.title(u"Google Assistant") root.geometry("400x400") root.resizable(0,0) root.protocol('WM_DELETE_WINDOW', quit) bln = tkinter.BooleanVar() #チェックボックス chkBox = tkinter.Checkbutton(master=root,variable=bln,width=60, text='音声も再生する') chkBox.place(x=50,y=0) #ボタン button1 = tkinter.Button(master=root, text="音声入力", width=15, bg="#ff6633", command=assist_open) button1.place(x=0,y=0) #テキストボックス textBox = tkinter.Text(master=root,width=50,font=("",10)) textBox.place(x=0,y=30) receive_start() root.mainloop() |
Assistantのコンソール表示用シェル
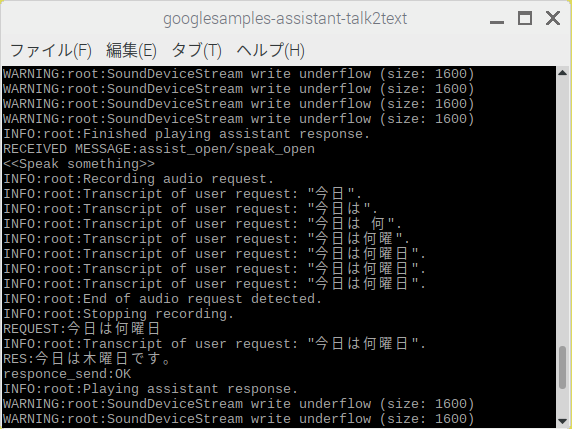
【grpc_assistant.sh】
XXXXXXXX、YYYYYYYYYY はAssistant SDKをインストールした際に取得したプロジェクトIDとデバイスモデルIDです、ご自分ので置き換えてください。
#!/bin/bash
source /home/pi/env/bin/activate
lxterminal -e googlesamples-assistant-talk2text –project-id XXXXXXXX –device-model-id YYYYYYYYYY
Assistant起動コード
【googlesamples-assistant-talk2text】
|
1 2 3 4 5 6 7 8 9 10 11 |
#!/home/pi/env/bin/python # -*- coding: utf-8 -*- import re import sys from googlesamples.assistant.grpc.talk2text import main if __name__ == '__main__': sys.argv[0] = re.sub(r'(-script\.pyw?|\.exe)?$', '', sys.argv[0]) sys.exit(main()) |
ファイルの配置
Assistantの環境をSDKで作った場合、ラズパイのホームに仮想環境(env)が作成されています。
そこに配置します。
/home/pi/env/bin/googlesamples-assistant-talk2text
/home/pi/env/lib/python3.5/site-packages/googlesamples/assistant/grpc/talk2text.py
以下の2つのファイルはどこに置いてもいいです。talk2textというフォルダーを作ってまとめて配置しときましょう。
grpc_assistant.shは上記に従ってIDを書き換えてください。
/home/pi/talk2text/grpc_assistant.sh
/home/pi/talk2text/Gui.py
実行
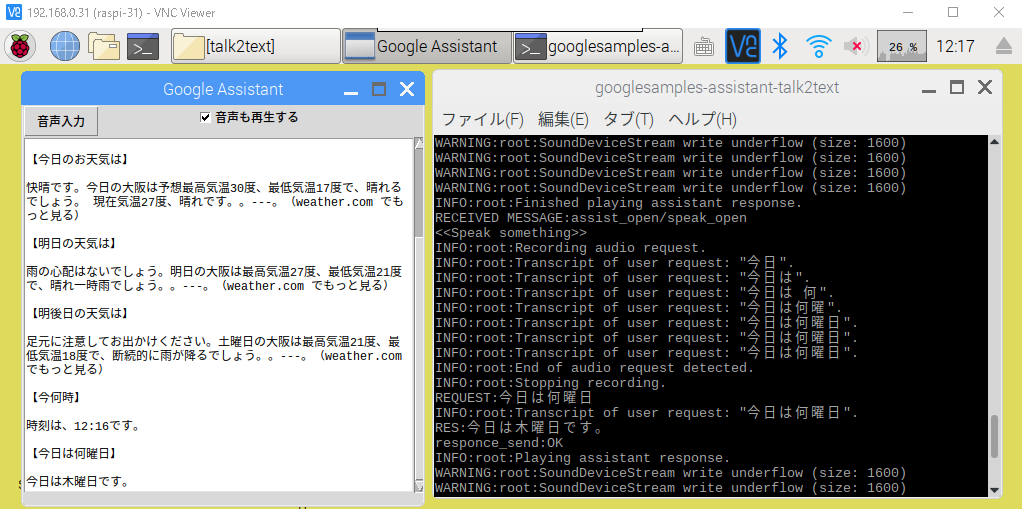
左がGui.pyの起動画面、先に起動しておきます。右がgrpc_assistant.shの起動画面。
初期画面
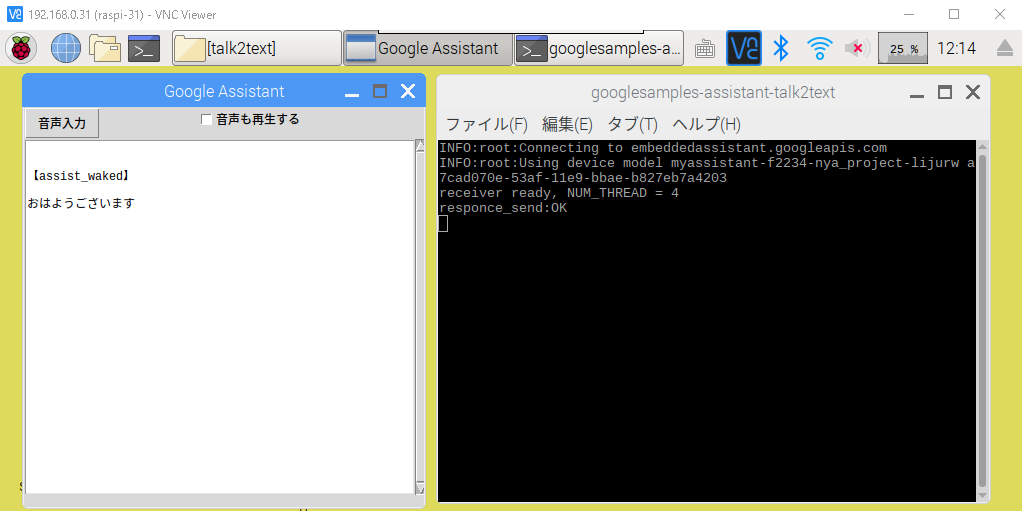
音声入力ボタンをクリックしてから話しかけてください
(Googleの音声出力も再生する場合はチェックを入れてからクリック)
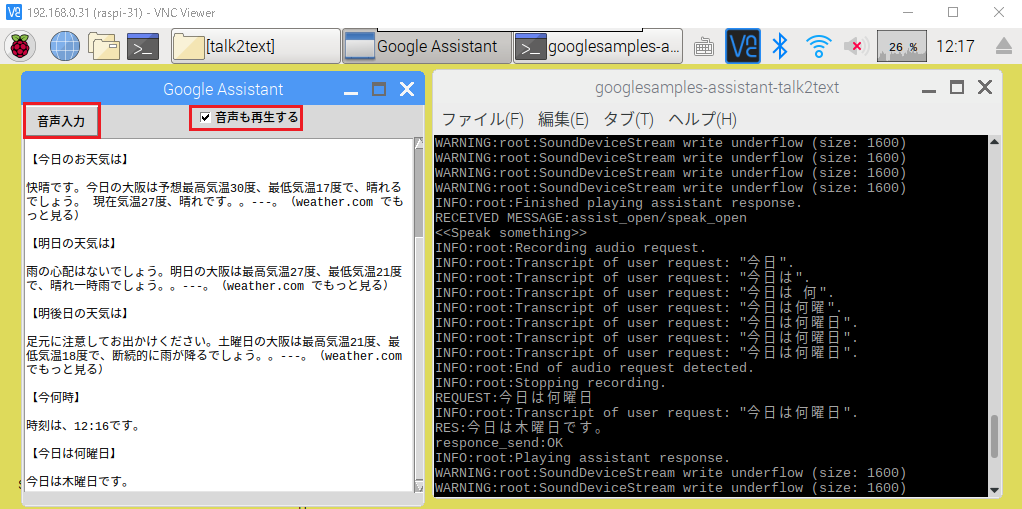
ボタンをクリックしてフラッグを送信している部分をJuliusの音声認識にすれば、ホットワードをご自分のものに置き換えられます。ここ参照
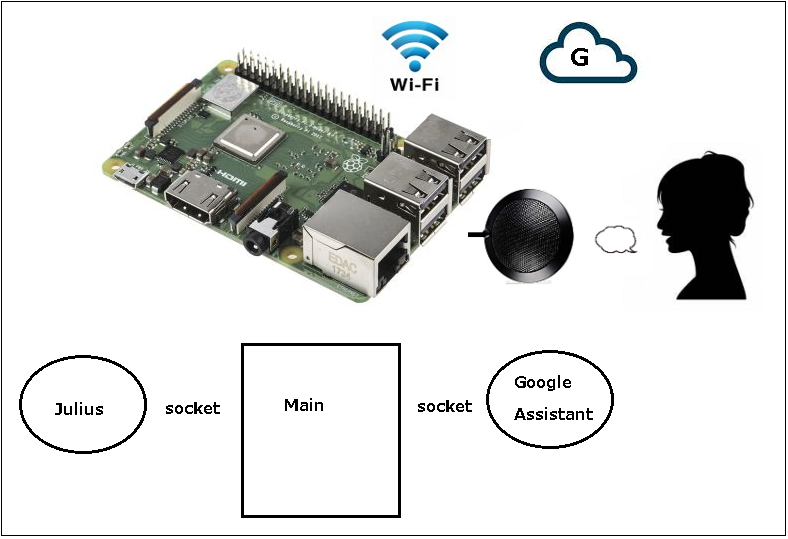
ラズパイでGoogle Assistantへのリクエストをテキストでやってみる
Leave a Reply