
日本語音声認識でクラウド・サービスを利用しない(自己完結型の)場合、OSS界隈では現実的な選択肢はJulius一択のようです。
高速・高精度・高効率をうたってますが、「自分の、しかも、それなりの」精度が欲しい場合はチューニングせにゃいかんようです。
MozillaのDeep Speechに期待しますが、まだラズパイは非力過ぎます。
Discussion Forums(Raspbianについても若干)

準備
OSは32bitのRaspbian。
USBマイクがサウンドデバイスとして認識されているか確認
$cat /proc/asound/modules
既存の内蔵オーディオモジュールが優先されるので多分こうなっている
0 snd_bcm2835
1 snd_usb_audio <-ここ
注:ラズパイ4の場合
HDMIポートが2個あるので、こうなっています。ただ、番号だけの問題なので影響なし。
0 snd_bcm2835
1 snd_bcm2835
2 snd_usb_audio <-ここ
USBマイクの優先度を上げる
$sudo leafpad /lib/modprobe.d/aliases.conf
コメントアウト
#options snd-usb-audio index=-2
挿入
options snd slots=snd_usb_audio,snd_bcm2835
options snd_usb_audio index=0
options snd_bcm2835 index=1
ラズパイ再起動
再確認
$cat /proc/asound/modules
0 snd_usb_audio <-ここ
1 snd_bcm2835
インストール
GitHubでJuliusの最新版を確認
(2019/01/04現在、最新バージョンは4.5です、が、安定の4.4.2.1を使ってみます。
4.5を使う場合は以下の4.4.2.1を4.5に書き換えてください、問題なくインストールできます)
適当なディレクトリーを作って、ここにダウンロードしてmakeします。
|
1 2 3 4 5 6 7 8 |
$mkdir julius $cd ~/julius $wget https://github.com/julius-speech/julius/archive/v4.4.2.1.tar.gz $tar zxvf v4.4.2.1.tar.gz $cd julius-4.4.2.1 |
インストール
|
1 2 3 |
$./configure $make $sudo make install |
ossのキャラクター型デバイスの1つの/dev/dspを使えるようにします(juliusはこれを使います)。
$sudo apt-get install osspd-alsa
再起動
juliusフォルダーへ移動
|
1 |
$cd ~/julius/julius-4.4.2.1 |
Juliusディクテーション実行キット
ダウンロード&解凍
|
1 2 3 |
$wget https://osdn.net/dl/julius/dictation-kit-v4.4.zip $unzip dictation-kit-v4.4.zip |
ダウンロード&解凍
|
1 2 3 |
$wget https://github.com/julius-speech/grammar-kit/archive/v4.3.1.zip $unzip v4.3.1.zip |
サウンドカード指定
|
1 |
$arecord -l |
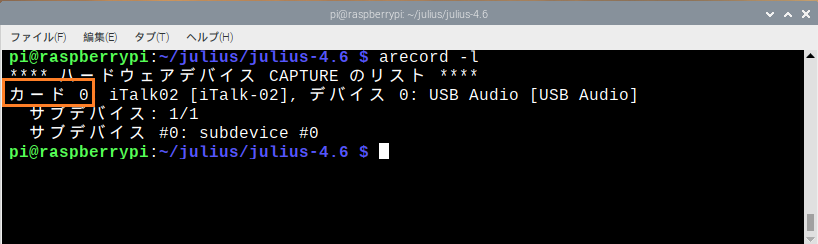
|
1 |
$export ALSADEV=hw:<カード番号> |
例
$export ALSADEV=hw:0
設定しておく場合は以下のファイルに書き込む
$sudo leafpad ~/.profile
追加
export ALSADEV=hw:0
サンプルファイルを用いてテスト
|
1 2 3 |
$cd ~/julius/julius-4.4.2.1/dictation-kit-v4.4 $julius -C main.jconf -C am-gmm.jconf -demo |

注:ラズパイ4+raspberrypi 5.10.17-v7l+でJukius 4.6 、dictation-kit-v4.4で以下のようなエラーが出た場合
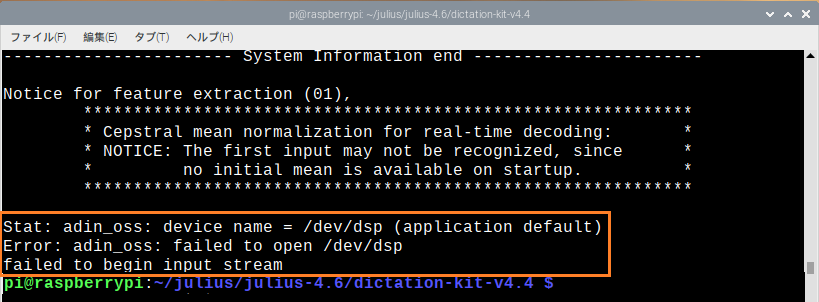
以下を実行
|
1 |
$sudo modprobe snd-pcm-oss |
恒久化する場合は以下のように/etc/modulesに書き込みます。
|
1 |
sudo sh -c "echo snd-pcm-oss >> /etc/modules" |
起動時に実行されるはずですが、うまくいかない場合もあります。ちょっと乱暴ですが、.bashrcに書き込んでしまいます。
|
1 |
echo sudo modprobe snd-pcm-oss >> ~/.bashrc |
注:マイクの反応がないか、なんか鈍いようなら….
感度チェック
|
1 |
$amixer -D hw:0 |
100%にする場合
|
1 |
$amixer -D hw:0 sset Mic 100% |
注:サンプリングレートが48000hzになっている場合
juliusは16000hzでサンプリングするので、ダウンレートするように….
XXX.jconfに以下を追加
-48
バックアップ環境に作成ファイル一式をコピーして起動した際、認識率が低下したと感じた場合、この項をチェックする必要がある。音響モデルが環境にどう影響されるのかもっと調べてみます。
注:
精度アップーA
対象語数を絞って、単語だけを高速に認識できるよう自作の辞書を用意
dictation-kit-v4.4ディレクトリーに以下のように3段階でファイルを作成してjuliusを実行します。
1:sample.yomi(tab区切り)
エディタで開いてyomiファイル作成
|
1 |
$sudo nano sample.yomi |
例えば以下のを記述(空白行があるとエラーになるので注意)
|
1 2 3 4 5 |
おはよう おはよう こんにちわ こんにちわ こんばんわ こんばんわ おやすみ おやすみ 元気ですか? げんきですか |
2:sample.dic
yomiファイルからdicファイル作成
Vsersion 4.5 以前
|
1 |
$iconv -f shiftjis -t eucjp sample.yomi | <パス>/yomi2voca.pl > sample.dic |
Vsersion 4.5以降(文字コードはUTF-8に統一されました)
|
1 |
$cat sample.yomi | <パス>/yomi2voca.pl > sample.dic |
*ちなみにjulius-4.4.2.1の場合のフルパス
/home/pi/julius/julius-4.4.2.1/gramtools/yomi2voca/yomi2voca.pl
3:sample.jconf
エディタで開いてjconfファイル作成
|
1 |
$sudo nano sample.jconf |
以下を記述
|
1 2 3 4 5 6 7 8 9 10 11 12 |
-w sample.dic #単語辞書ファイル。作成した「sample.dic」を指定 -v model/lang_m/bccwj.60k.htkdic #N-gram、または文法用の単語辞書ファイルを指定 -h model/phone_m/jnas-tri-3k16-gid.binhmm #使用するHMM定義ファイル -hlist model/phone_m/logicalTri #HMMlistファイルを指定する -n 3 #n個の文仮説数が見つかるまで検索を行う。3〜5。 -output 1 #見つかったN-best候補のうち、結果として出力する個数 #-input mic #マイク使用 引数で指定している場合は不要 -input oss #オープンサウンドシステム使用 -rejectshort 1000 #検出された入力時間(msec)が閾値以下なら棄却 #-charconv euc-jp utf8 #入出力エンコード指定(内部euc-jp, 出力utf-8) version 4.5 以降は不要らしい -lv 1000 #入力の振幅レベルの閾値(0~32767) -fvad 1 |
fvadオプションはver4.5以降
実行します
|
1 |
$julius -C sample.jconf -input mic |
こんな感じ
精度アップーB
Julius記述文法音声認識実行キットを使ってみます。
言語モデルを参考にして記述文法を作成
作成する認識用文法ファイルは2つ(xxx.grammar、xxx.voca)。
ファイル名のxxxは同じにします。
vocaファイルに書き込む音素の記述ルールは特殊なものもあります。
コンパイル時には気づきませんが、Juliusで読み込んだ時に分かります、ご注意ください。
例えば家電を操作するような場合。
これは「〇〇〇を△△△して」というお願い系のコマンド。
【kaden.grammar】
S : NS_B KADEN_ PLEASE NS_E
KADEN_ : KADEN
KADEN_ : KADEN WO
#
PLEASE : TSUKETE
PLEASE : KESHITE
【kaden.voca】
% KADEN
エアコン e a k o n
テレビ t e r e b i
% WO
を w o
% TSUKETE
つけて t u k e t e
% KESHITE
消して k e s i t e
% NS_B
<s> silB
% NS_E
</s> silE
grammar ファイルと voca ファイルをオートマトン(dfa ファイル)と単語辞書(dict ファイル)に変換します。
$mkdfa.pl kaden
kaden.dfa,kaden.dictが新たに作成されます。
記述文法は複数つくることができます。
例えば声掛け用をもう一つ。
【call.grammar】
S : NS_B CALL_ NS_E
CALL_ : CALL
CALL_ : CALL NOISE
【call.voca】
% CALL
キリン k i r i n
レモン r e m o n
アラレちゃん a r a r e ch a N
% NOISE
<sp> sp
% NS_B
<s> silB
% NS_E
</s> silE
$mkdfa.pl call
*ちなみに
/home/pi/julius/julius-4.4.2.1/gramtools/mkdfa/mkdfa.pl
設定ファイル
【sample2.jconf】
-gram kaden -gram call #2つの文法を使います
-v ../model/lang_m/bccwj.60k.htkdic
-h ../model/phone_m/jnas-tri-3k16-gid.binhmm
-hlist ../model/phone_m/logicalTri
-n 1 #見つける文仮説数は1
-output 1
-input mic
-rejectshort 600
#入出力エンコード指定は使わない、何故かmultibyteがらみのinternalErrorになる
#-charconv euc-jp utf8
-lv 1000
実行
$julius -C sample2.jconf -input mic
注:このやり方がAより精度が高いというわけではないです。
精度アップ-C
Juliusはver4.3からDNN-HMM音響モデルが使われています。
それ以前のバージョンでは誤認識対策でSVM(サポートベクターマシン)を使おうとされた方もいらっしゃるようです。
参考までにJulius + SVM
どこにどんな学習モデルなどが適用できるか、少し探してみましょう。
また、パラメータ調節でどの程度認識率が上がるのかも調査してみます。
Juliusとはなんぞや(ビギナー編)に書かれているように、付録 B. オプション一覧の、第1パスパラメータ、第2パスパラメータ、単語ラティス / confusion network 出力の項をいじってカスタマイズしてみます。
認識パラメータの調節は以下の3項目でやってみなはれ…だそうです(どれかではなく1から順番に)。
1. 第一パスのビーム幅を設定する!
2. 言語スコア重みと、挿入ペナルティを設定する!
3. 文仮説数や出力形式を設定する!
で、達成目標
「環境」や「私」のノイズと、「私の」声掛けの言葉を高い確率で区別できること!
「私の」短い命令形の語句を正しく認識できること!
ただJuliusBookを読んでみると、この程度の目標なら認識パラメータの調節はいらないんじゃないか?という気もするのだけど……..。「私の」環境の音響モデルは作ってみる価値はあるかもしれないけど。
もっとシンプルにjconfのオプション設定
まず、音声区間検出(ここ参照)
振幅レベル(-lv)は2000くらいに設定します(デフォルト?)。
マイクの近くで普通にしゃべりかけるなら、1000くらい。
以下のパラメーターは検出された入力の時間(msec)が閾値以下なら棄却するというもので、咳などの雑音は少し大きめの値にしてみる。
-rejectshort 1000
工事中
ノイズ対策
Juliusは入力された音をとにかく辞書から検索してとにかくマッピングしようとするクセ(?)があります。
(どうしようもない音の場合は空を返してくる場合もありますが)
対策としては以下を参照。
まだ、試していませんけど……。
くしゃみや咳の誤認対策には有効だと思われます。ただ問題なのは、くしゃみや咳は録音しようと思ってもなかなかできないってことです。
で、とりあえずの対策としては、ノイズを間違って正解文にマッピングしないようにしてみます。
気休めです。
上記の辞書にキリンやレモンがあるのは、これをダミーに使うためです。
咳やクシャミなどの「’%’&%%’△65◇….」という入力音を「アラレちゃん」と解釈しないようにJuliusにダミーをマッピングさせます。どうもJuliusは困った時には似た(?)言葉を採用してしまうようです。
こういう無駄なダミーをいくつか用意しておくと、Juliusの誤認識というか誤適合を回避できるかもしれません。管理人はダミーのことを「捨て台詞」と呼んでます(^^)。
例えば、「バイバイ」という単語のみ登録している場合、”ほいほい”という呼びかけ(無意味な呼びかけもJuliusにとってはノイズと等価)に対してJuliusは高確率で”バイバイ”を採用します。でもダミーとして「ホイホイ」も登録しておけばJuliusは”ホイホイ”も選択肢にいれるので”バイバイ”を採用する確率は下がります。
まぁ、誤適合を防ぐためにノイズに「正解」を与えておこうということです。
また、モジュールモードでの出力ではクライアントへ第2パスの認識結果とともに単語信頼度も出力されます。
この単語信頼度(CM)を指標にしてもいいかもしれません。CMは単語辞書なら1個、記述文法なら区切り(?)単位で返してくるので、どう扱うか思案します。
単純に、単語辞書のみ使う場合、CMは1個だけ返ってきますが、このCMの値が0.990以上の場合のみ採用するというだけで、例えばマイクのそばで柏手を打ったり咳をするだけで反応するというアホな誤認識は相当に軽減できるようです。
ただ、ウェイクワードとして使う言葉の場合は閾値を下げておかないと、なっかなか返事をしてくれないシステムになってしまうので注意が必要です。
やり方は、例えばこんな感じ。
単語信頼度はCM=”0.898″というようなフォーマットで返ってくるので、下記のraspi-julius.pyでWORDを取得しているようにindex2 = line.find(‘CM=”‘)という感じで値を取得すればいいです。
|
1 2 3 4 5 6 |
cm_list = [] index2 = line.find('CM="') if index2 != -1: cm = line[index2 + 4:line.find('"', index2 + 4)] cm_list.append(cm) |
で、
|
1 2 3 |
if(len(cm_list) == 1): if(float(cm_list[0]) >= 0.990): process_query(sentence) |
これでいいのかは不明です、もう少し学習してまたレポートします。
後は、命令文は、最も誤認識されにくい言葉で代替する?
「〇〇〇を△△△して」を分かってもらえない場合、認識されやすい単語で命令する…..とか。
認識結果を利用する
Juliusをモジュールとして起動し、結果をPythonで利用してみます(socketを使ったプロセス間通信)。
ラズパイのローカルIPが192.168.0.31だとして、10500番ポートを使っています。
Juliusが認識した結果をsentenceで取得しています。その中に所定の命令文や声掛け文(XXXX)があれば、何かします。
#何かする….のところは、例えば「声かけ」で赤外線リモコン制御とか、カメラと顔認識AIとサーボモーターがあれば、あなたの方を向いてくれます(^^)。
【raspi-julius.py】
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 |
#!/usr/bin/env python3 # -*- coding: utf-8 -*- from tkinter import messagebox import socket import subprocess import time julius_host = '192.168.0.31' julius_port = 10500 has_recongized = False def process_query(sentence): global has_recongized if "ハロー" in sentence: messagegbox('message box',"hello") has_recongized = True else: if has_recongized == True: if "XXXX" in sentence: print('"' + sentence + '"') #<strong>何かする</strong> has_recongized = False elif "キャンセル" in sentence or "中止" in sentence: #何もしない has_recongized = False messagegbox('message box',"ok") def main(): # julius起動 process = subprocess.Popen(["./<strong>start-julius.sh</strong>"], stdout=subprocess.PIPE, shell=True) #プロセスIDを取得 pid = str(process.stdout.read().decode('utf-8')) client = socket.socket(socket.AF_INET, socket.SOCK_STREAM) client.connect((julius_host, julius_port)) print("●なんか言って!") try: data = '' sentence ='' while True: if '</RECOGOUT>\n.' in data: word = "" for line in data.split('\n'): index = line.find('WORD="') if index != -1: line = line[index + 6:line.find('"', index + 6)] word = str(line) if word != '[s]': sentence += word print('"' + sentence + '"') process_query(sentence) sentence = '' data = '' print("●なんか言って!") else: data += str(client.recv(1024).decode('utf-8')) except KeyboardInterrupt: #Ctrl+ Cなどで起動スクリプトのプロセスを終了 process.kill() subprocess.call(["kill "+pid],shell=True) client.close() if __name__ == "__main__": main() |
【start-julius.sh】
|
1 2 3 4 5 6 7 8 |
#!/bin/sh julius -C /home/pi/julius/julius-4.4.2.1/dictation-kit-v4.4/sample.jconf -input mic -module > /dev/null & #プロセスIDを出力 echo $! sleep 2 |
マイク・スピーカー
セルフパワーUSBハブを使います。
スピーカー
ダイソーの300円USBスピーカーで必要十分
アンプ内蔵なので音量調整できます。この商品はコスパの高さが評判で、いろいろな方がグレードアップの方法などもアップしていおられますね。
マイク
スペックどおりの範囲で使う場合は、ラズパイのUSBコネクターに直差しではなくセルフパワーUSBハブを通して給電した方がいいです(直差しだと場合によっては10ft≒3mの集音範囲が30cmくらいになります)。
全指向性なので、そばに置いといて、あさっての方に向かって喋ってもJuliusは認識してくれます。
こんな構成
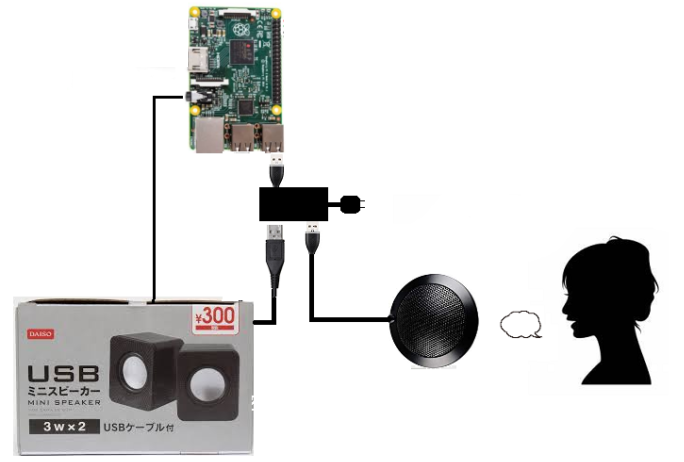
音声出力時の不具合例
●aplay実行時に「そのようなファイルはありません」と出る場合
サウンドデバイスを明示的に指定しなければならないかもしれません。
$aplay -l
で、[bcm2835 ALSA]のカード番号とデバイス番号をチェック
例
カード番号=1、デバイス番号 = 0の場合
$ aplay -D hw:1,0 /usr/share/sounds/alsa/Front_Center.wav
●ミニジャックに接続したスピーカーから音が出ない場合
ここもチェック。
スピーカーアイコンを右クリック。
●セルフパワーUSBハブに接続時の不具合例
接続したまま起動した場合、なぜか認識されない不具合がありました。
イレギュラーなので原因はつかみにくいです。
この場合は、単に抜き差しすればいいだけですが、こういうこともあるってことですね。
音声入力時の不具合例
●/dev/dspが見つからない….Juliusが起動しない場合
ALSA設定ファイル(.asoundrc)が問題を起こしている可能性がある->削除
.asoundrcは/home/piにある隠しファイルです。
こんな構成の場合
USBタイプのマイク・スピーカー一体型(ヘッドセット)
$aplay -l
で、[USB Audio]のカード番号とデバイス番号をチェック
例
カード番号=0、デバイス番号 = 0の場合
$ aplay -D plughw:0,0 xxx.wav
モノラル音源がいいかも…。
音素列の記述ルールは、”登録したい単語+半角スペース+ローマ字読み”となります。
ローマ字読み(音素記号)の記述ルールは以下の通りです。
・基本は小文字のアルファベットを使う。
・母音と子音の間に半角スペースを入れる。
・「ん」は大文字の「N」。
・小さい「っ」は「q」で表す。
・伸ばす音は母音に「:(コロン)」を付ける。
例 大阪 o: s a k a
・発音に近い表記をする。
例 「昨日」は「きのー」と表現し「k i n o:」と表記する。
・助詞の「は」「へ」は,それぞれ「w a」「e」と表記する。
・記述の例
チェンジ ch e N j i
終了 sh u: ry o:
ウェーブファイル w e: b u f a i r u
ガンバ g a N b a
| あ | い | う | え | お | か | き | く | け | こ |
| a | i | u | e | o | k a | k i | k u | k e | k o |
| さ | し | す | せ | そ | た | ち | つ | て | と |
| s a | sh i | s u | s e | s o | t a | ch i | ts u | t e | t o |
| な | に | ぬ | ね | の | は | ひ | ふ | へ | ほ |
| n a | n i | n u | n e | n o | h a | h i | f u | h e | h o |
| ま | み | む | め | も | や | ゆ | よ | ||
| m a | m i | m u | m e | m o | y a | y u | y o | ||
| ら | り | る | れ | ろ | わ | ||||
| r a | r i | r u | r e | r o | w a | ||||
| が | ぎ | ぐ | げ | ご | ざ | じ | ず | ぜ | ぞ |
| g a | g i | g u | g e | g o | z a | j i | z u | z e | z o |
| だ | で | ど | ば | び | ぶ | べ | ぼ | ||
| d a | d e | d o | b a | b i | b u | b e | b o | ||
| ぱ | ぴ | ぷ | ぺ | ぽ | きゃ | きゅ | きょ | ||
| p a | p i | p u | p e | p o | ky a | ky u | ky o | ||
| しゃ | しゅ | しょ | ちゃ | ちゅ | ちょ | にゃ | にゅ | にょ | |
| sh a | sh u | sh o | ch a | ch u | ch o | ny a | ny u | ny o | |
| ひゃ | ひゅ | ひょ | みゃ | みゅ | みょ | りゃ | りゅ | りょ | |
| hy a | hy u | hy o | my a | my u | my o | ry a | ry u | ry o | |
| ぎゃ | ぎゅ | ぎょ | じゃ | じゅ | じょ | ||||
| gy a | gy u | gy o | j a | j u | j o | ||||
| びゃ | びゅ | びょ | ぴゃ | ぴゅ | ぴょ | てぃ | でぃ | でゅ | |
| by a | by u | by o | py a | py u | py o | t i | d i | dy u | |
| とぅ | どぅ | ふぁ | ふぃ | ふぇ | ふぉ | ちぇ | しぇ | じぇ | |
| t u | d u | f a | f i | f e | f o | ch e | sh e | j e | |
| あー | いー | うー | えー | おー | かー | きー | くー | けー | こー |
| a: | i: | u: | e: | o: | k a: | k i: | k u: | k e: | k o: |
| さー | しー | すー | せー | そー | たー | ちー | つー | てー | とー |
| s a: | sh i: | s u: | s e: | s o: | t a: | ch i: | ts u: | t e: | t o: |
| なー | にー | ぬー | ねー | のー | はー | ひー | ふー | へー | ほー |
| n a: | n i: | n u: | n e: | n o: | h a: | h i: | f u: | h e: | h o: |
| まー | みー | むー | めー | もー | やー | ゆー | よー | ||
| m a: | m i: | m u: | m e: | m o: | y a: | y u: | y o: | ||
| らー | りー | るー | れー | ろー | わー | ||||
| r a: | r i: | r u: | r e: | r o: | w a: | ||||
| がー | ぎー | ぐー | げー | ごー | ざー | じー | ずー | ぜー | ぞー |
| g a: | g i: | g u: | g e: | g o: | z a: | j i: | z u: | z e: | z o: |
| だー | でー | どー | ばー | びー | ぶー | べー | ぼー | ||
| d a: | d e: | d o: | b a: | b i: | b u: | b e: | b o: | ||
| ぱー | ぴー | ぷー | ぺー | ぽー | きゃー | きゅー | きょー | ||
| p a: | p i: | p u: | p e: | p o: | ky a: | ky u: | ky o: | ||
| しゃー | しゅー | しょー | ちゃー | ちゅー | ちょー | にゃー | にゅー | にょー | |
| sh a: | sh u: | sh o: | ch a: | ch u: | ch o: | ny a: | ny u: | ny o: | |
| ひゃー | ひゅー | ひょー | みゃー | みゅー | みょー | りゃー | りゅー | りょー | |
| hy a: | hy u: | hy o: | my a: | my u: | my o: | ry a: | ry u: | ry o: | |
| ぎゃー | ぎゅー | ぎょー | じゃー | じゅー | じょー | びゃー | びゅー | びょー | |
| gy a: | gy u: | gy o: | j a: | j u: | j o: | by a: | by u: | by o: | |
| ぴゃー | ぴゅー | ぴょー | てぃー | でぃー | でゅー | とぅー | どぅー | ||
| py a: | py u: | py o: | t i: | d i: | dy u: | t u: | d u: | ||
| ふぁー | ふぃー | ふぇー | ふぉー | ちぇー | しぇー | じぇー | ん | ||
| f a: | f i: | f e: | f o: | ch e: | sh e: | j e: | N |
JuliusBookを読む上で引っかかったキーワード
零交差波(解説じゃないですが、読み通すと、ああ、こういう風に使うものなのかぁ…と妙に納得する)
工事中
Appendex
複数のwavを連結する場合
soxを使います。
$sudo apt-get install sox
$sox s1.wav s2.wav …. out.wav
現時点で最も認識精度が高いと思われるのは、やはりGoogle Cloud Speech-to-Text API ( and Google Assistant SDK ) です。
ただし、Google Cloud Speech-to-Text APIは制限を超えると課金されます、ちょっとまずい。
60 分/月が無料枠、これを超えると15 秒ごとに音声処理の料金が発生します。
基本単位は15秒。「はい」みたいな1秒にも満たない音声でも15秒。15.01秒の音声なら30秒と換算されます。
また、 Google Assistantは500リクエスト/日の制限付き(無料)。
相談事を持ち掛けたり無駄話をするのでなければ500あれば十分?
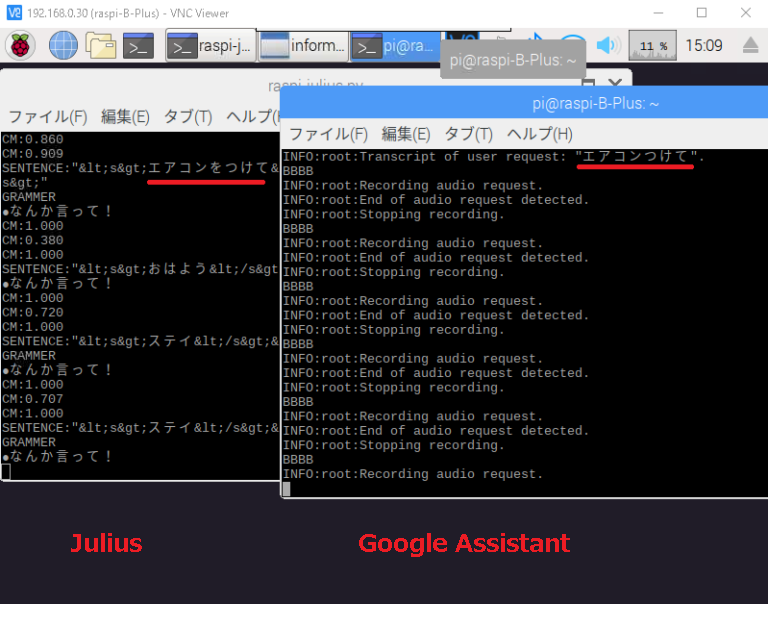
で、現状の最適解はJuliusとGoogleの合わせ技。
Juliusにも高精度で認識できるワードはあるので、声掛けや待ち受け状態ではJuliusを使います。
APIコンソールでいちいち利用料金をチェックするのも面倒。
制限を超えそうならJulius一本に切り替えます。
ルールを作ってGoogle Speech-to-Text API(and/or Google Assistant SDK)を使ってみます。
Juliusをウェイクワード(ホットワード)受付のフロントエンドにしてみます。
Assitantの認識が本来と一致していませんが、ここは文字列のレーベンシュタイン距離なんぞを使って「認識としてだいたい合ってる」を判断します。
意味まで含めると話は厄介になりますが、今回は必要ないと思われます。
まずは、ラズパイにGoogle Assistantをセットアップします。
Appendix2
Pythonでファイルの読み込み・書き出し
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
#!/usr/bin/env python3 # -*- coding: utf8 -*- import os.path path = '/home/pi/test.txt' #読み込み if os.path.exists(path): print(u"存在") with open(path,'r') as f: s = f.read() f.close() print(s) else: print(u"不在") #書き出し s = "aaa" with open(path,'w') as f: f.write(s) f.close() |
メモ
Juliusの音声認識結果を何らかの「命令」や「質問」に使用しようとした場合、完全な文章・センテンスを取得するのは難しい場合が多いです。
こういう場合は、期待される文・センテンスに対して音声認識で得られた文・センテンスがどれくらい「近いか」、「類似しているか」を判定する必要があります。
「近さ・類似度」としては確率・統計的な意味での距離ということになります。
レーベンシュタイン距離やWord2Vec、Doc2Vecなどを使ってみます。
閾値を設定しておいて、あるレベル以下なら「今なんつった?」と聞き直しましょう。
Leave a Reply