
注
2021/03/01現在、下記のtf-pose-estimationへのリンクは切れています、Githubのリポジトリも無くなっています。ただ、tf-pose-estimationで検索すると68、openposeで検索すると1000以上ヒットするので、やる気になれば再構築できるかもしれません^^。
姿勢推定をお使いになる場合は新規にtrt_pose の使用をご検討ください。
Jetson Nanoで学習済みモデルを使って、いろいろやってみる(4-1)姿勢推定(ResNet-18)
上記のページではPytorchが使われています。TensorFlow + OpenPose でやってみたい方は、こちらのページ(GitHub)をご参照ください。
時系列内のフィールドでのプレーヤーの体の向きを識別する技術に関して、
AUTOMATED TRACKING OF BODY POSITIONING USING MATCH FOOTAGE
(日本語訳)
この論文でOpenPoseが使われています(paper)。
FC Barcelona Sports Analytics Summitで発表されていたものです。
OpenPoseって何?
OpenPoseは人間の姿勢推定に使うアルゴリズムです、arXivはここ。
実際に触ってみようではないか….ということで。
こういう構成で使ってみます。
Jetson Nano + WebCam

OpenPoseはTensorFlow版を使ってみます。
インストール
Jetpackは4.2を使います。最新のJetpackは4.3でOpenCVは4.xらしく、TensorFlow版OpenPoseは3.xでしか動かないそうなので、前のOSを使います。
Jetpackのインストールはこのページをご参照ください。
tf-pose-estimationは依存ライブラリが結構複雑そうなので、Jetpackをクリーンインストールした状態から以下を実行してみました。
pip3インストール
sudo apt-get install python3-pip
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
pip3 install --upgrade cython sudo apt-get -yV install libopenblas-dev sudo apt-get -yV install liblapacke-dev sudo apt-get -yV install gfortran sudo apt-get -yV install llvm-7* echo 'export PATH="/usr/lib/llvm-7/bin:$PATH"' >> ~/.bash_profile source ~/.bash_profile git clone https://github.com/ildoonet/tf-pose-estimation.git cd tf-pose-estimation pip3 install argparse pip3 install dill pip3 install fire sudo apt install -y python3-matplotlib pip3 install numba pip3 install psutil pip3 install pycocotools pip3 install requests pip3 install scikit-image |
scikit-imageでscipyとpillowのインストールで失敗した場合
scipyはバージョンが低いとnumpy.testing.nosetesterが使えなくなるので、バージョン指定してインストールします。
|
1 2 3 4 5 6 7 8 9 10 |
pip3 install scipy==1.1.0 sudo apt install -y python3-pillow pip3 install slidingwindow pip3 install tqdm pip3 install git+https://github.com/ppwwyyxx/tensorpack.git cd tf_pose/pafprocess sudo apt install swig swig -python -c++ pafprocess.i && python3 setup.py build_ext --inplace |
TensorFlowをインストール
|
1 2 3 4 5 |
sudo apt-get install libhdf5-serial-dev hdf5-tools sudo apt-get install zlib1g-dev zip libjpeg8-dev libhdf5-dev sudo pip3 install -U numpy grpcio absl-py py-cpuinfo psutil portpicker grpcio six mock requests sudo pip3 install -U gast h5py astor termcolor sudo pip3 install https://developer.download.nvidia.com/compute/redist/jp/v42/tensorflow-gpu/tensorflow_gpu-1.13.1+nv19.5-cp36-cp36m-linux_aarch64.whl |
TensorFlowのグラフデータをダウンロード
|
1 2 3 |
cd ~/tf-pose-estimation cd models/graph/cmu bash download.sh |
実行してみます
リモートデスクトップで確認できます。リモートデスクトップの設定もここを参照。
cd ~/tf-pose-estimation
静止画
|
1 |
python3 run.py --model=mobilenet_thin --image=./images/yatto7.jpg |
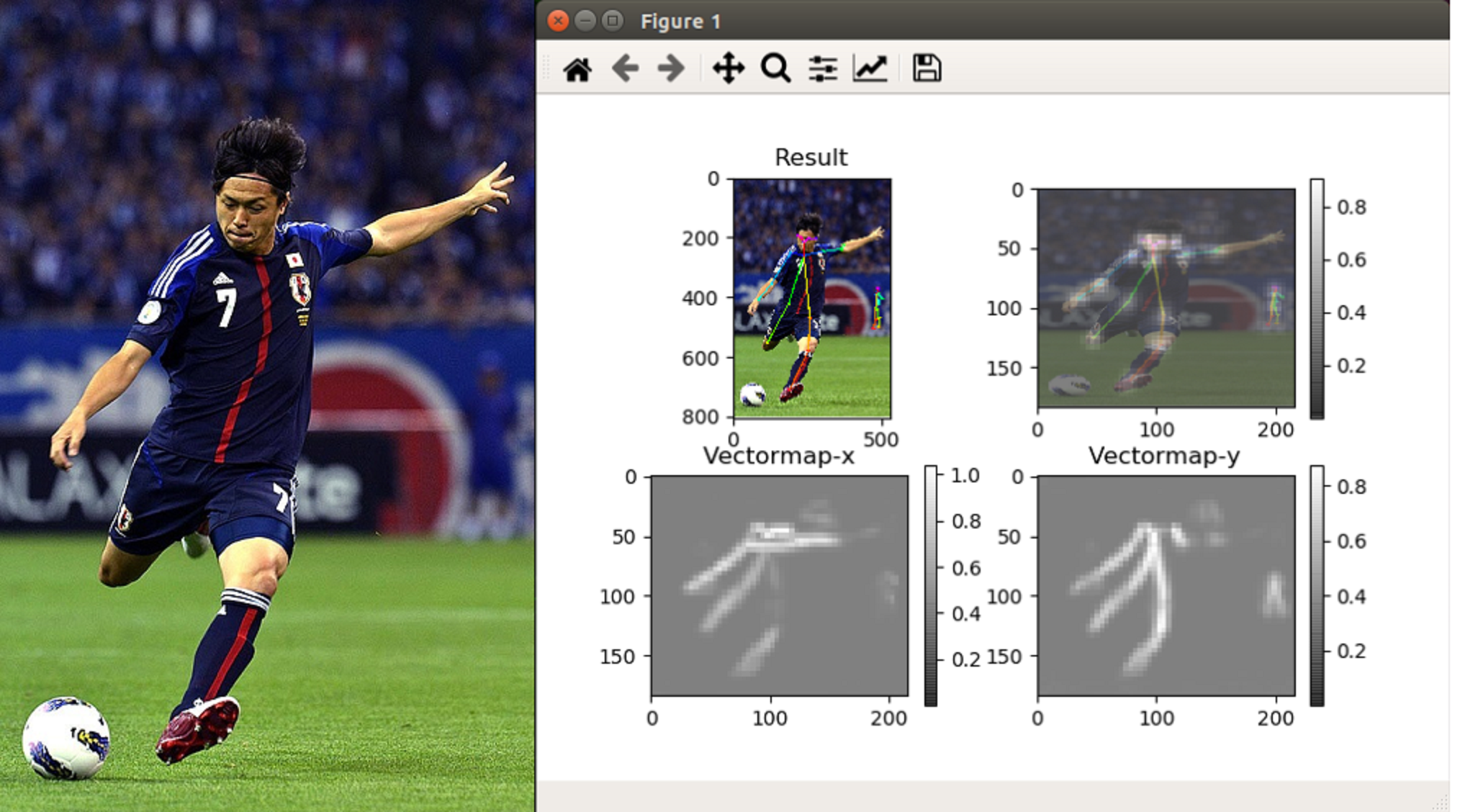
動画
ダウンロードしたrun_video.pyはバグっているようです。
この方のGitHubにあるコードを使わせていただきます。
修正箇所は以下の2ケ所。
from estimator -> from tf_pose.estimator
from networks -> from tf_pose.networks
|
1 |
python3 run_video.py --model=mobilenet_thin --video=./videos/gamba-U15.mp4 --resize=432x368 |
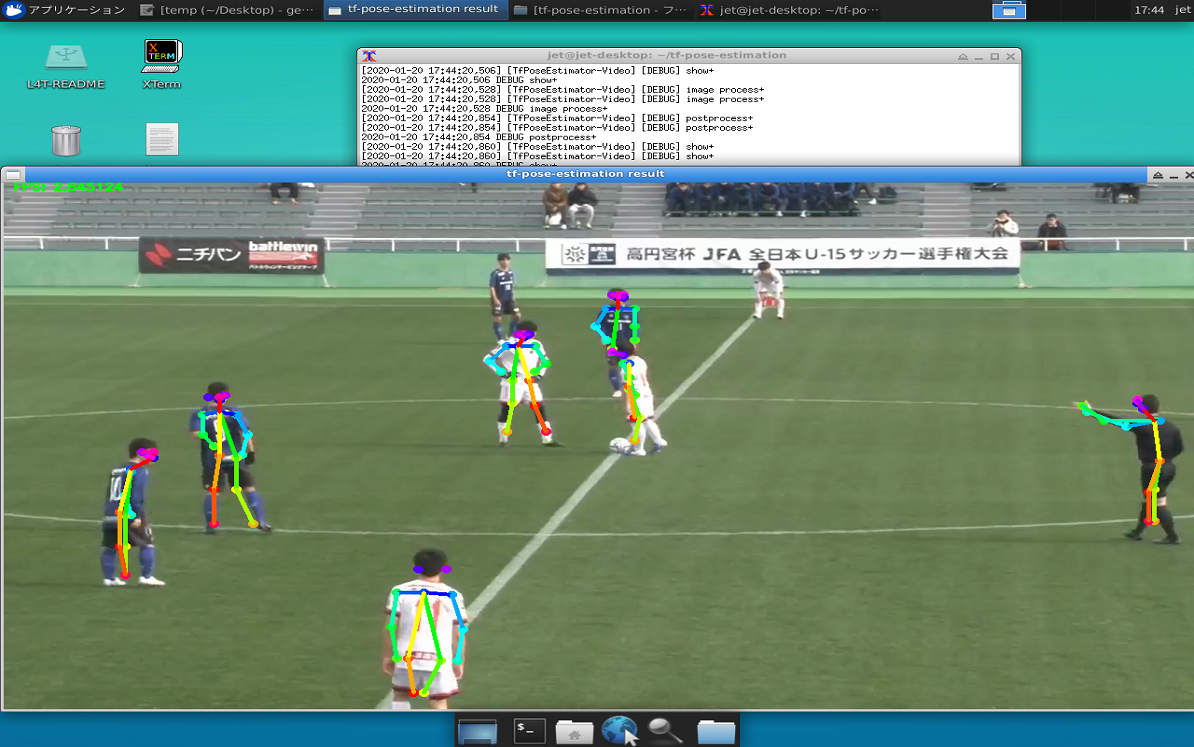
カメラ
Youtubeの動画をカメラでモニター
なお、Youtubeなどの動画は設定で再生速度を0.25あたりにしておくと、視認しやすいです。
|
1 |
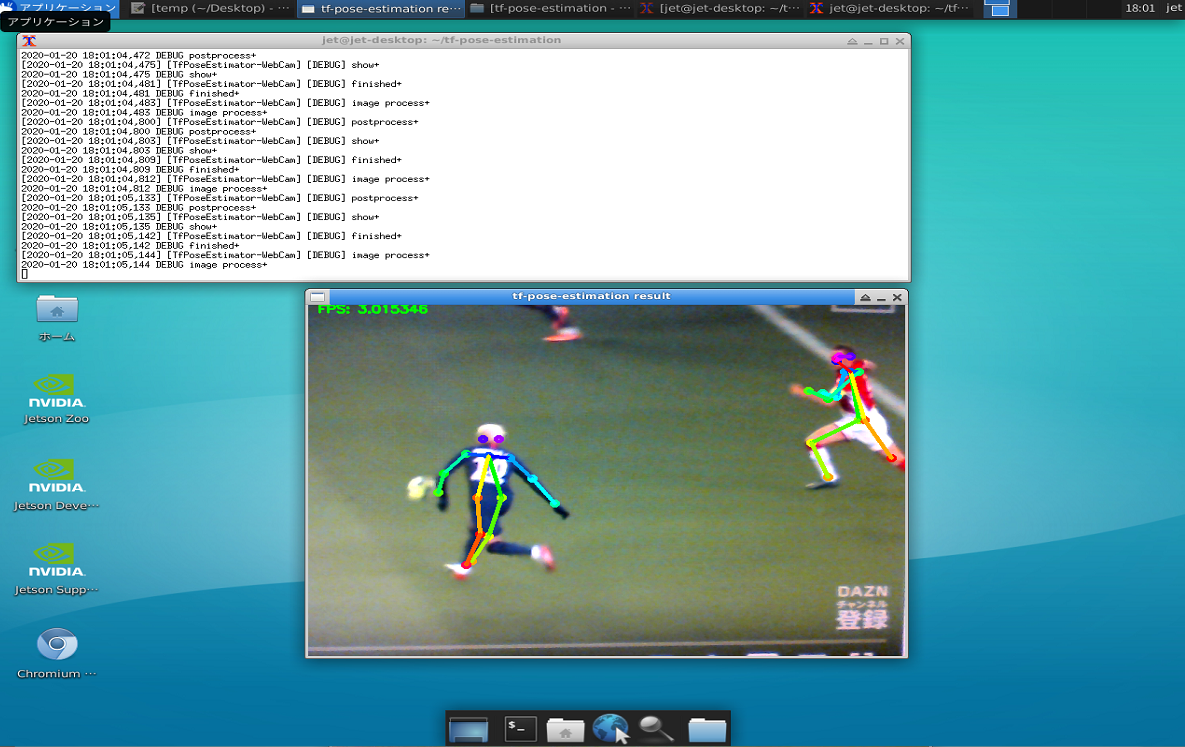
python3 run_webcam.py --model=mobilenet_thin --resize=432x368 --camera=0 |
裏に抜け出したネイマール(PSG)がボールをトラップした瞬間と、あわてて戻るモナコディフェンダーという構図。この後、ほぼGKと1対1になってゴール(^^)。
AUTOMATED TRACKING OF BODY POSITIONING USING MATCH FOOTAGE
によれば、上体の向きを決めるのに重要なのは肩と腰の部分のデータで、選手がカメラと正対した場合のみ鼻、目、耳のデータを使うようです。
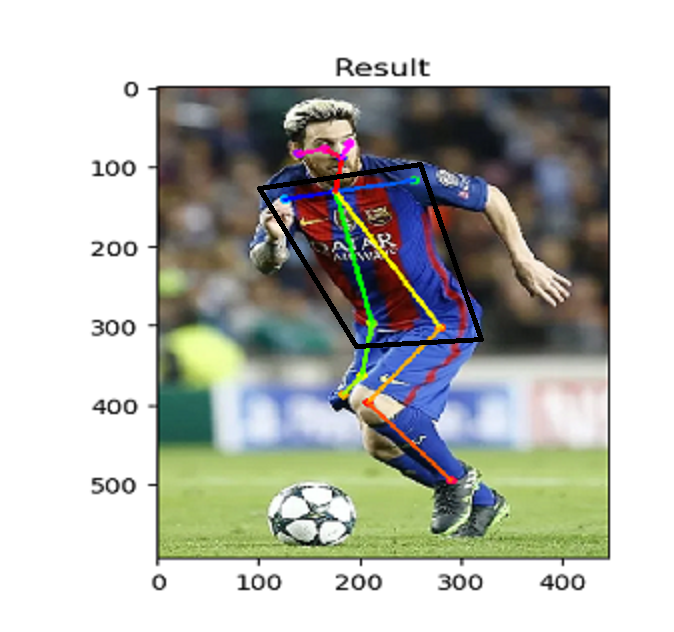
データを採取してみました
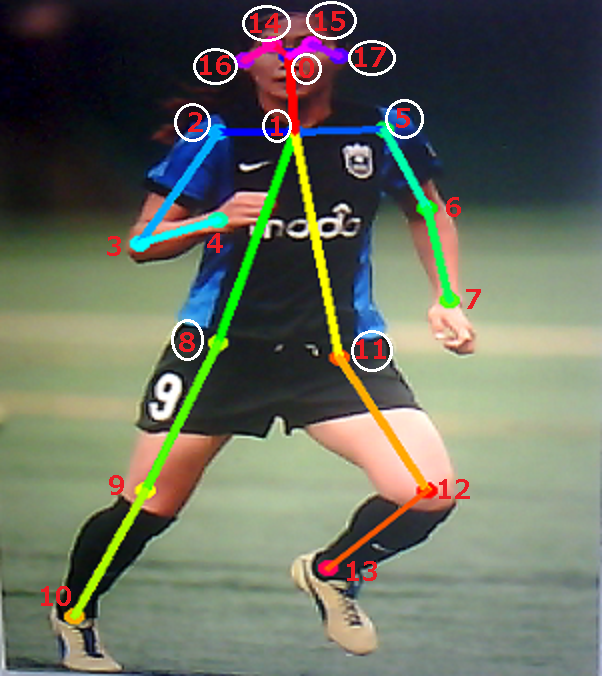
ヒントになるのは、tf-pose-estimation/tf_pose/にあるcommon.pyとestimator.pyです。
common.pyには人体パーツの各番号や線を引く時のペア番号の配列などが定義されています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
class CocoPart(Enum): Nose = 0 Neck = 1 RShoulder = 2 RElbow = 3 RWrist = 4 LShoulder = 5 LElbow = 6 LWrist = 7 RHip = 8 RKnee = 9 RAnkle = 10 LHip = 11 LKnee = 12 LAnkle = 13 REye = 14 LEye = 15 REar = 16 LEar = 17 Background = 18 |
|
1 2 3 4 |
CocoPairs = [ (1, 2), (1, 5), (2, 3), (3, 4), (5, 6), (6, 7), (1, 8), (8, 9), (9, 10), (1, 11), (11, 12), (12, 13), (1, 0), (0, 14), (14, 16), (0, 15), (15, 17), (2, 16), (5, 17) ] |
estimator.pyのdraw_humans関数で、検出されたポイントを結ぶ線が引かれます。
(2,16)、(5,17)の線のシチュエーションが分かりませんでした(横顔?….違います)
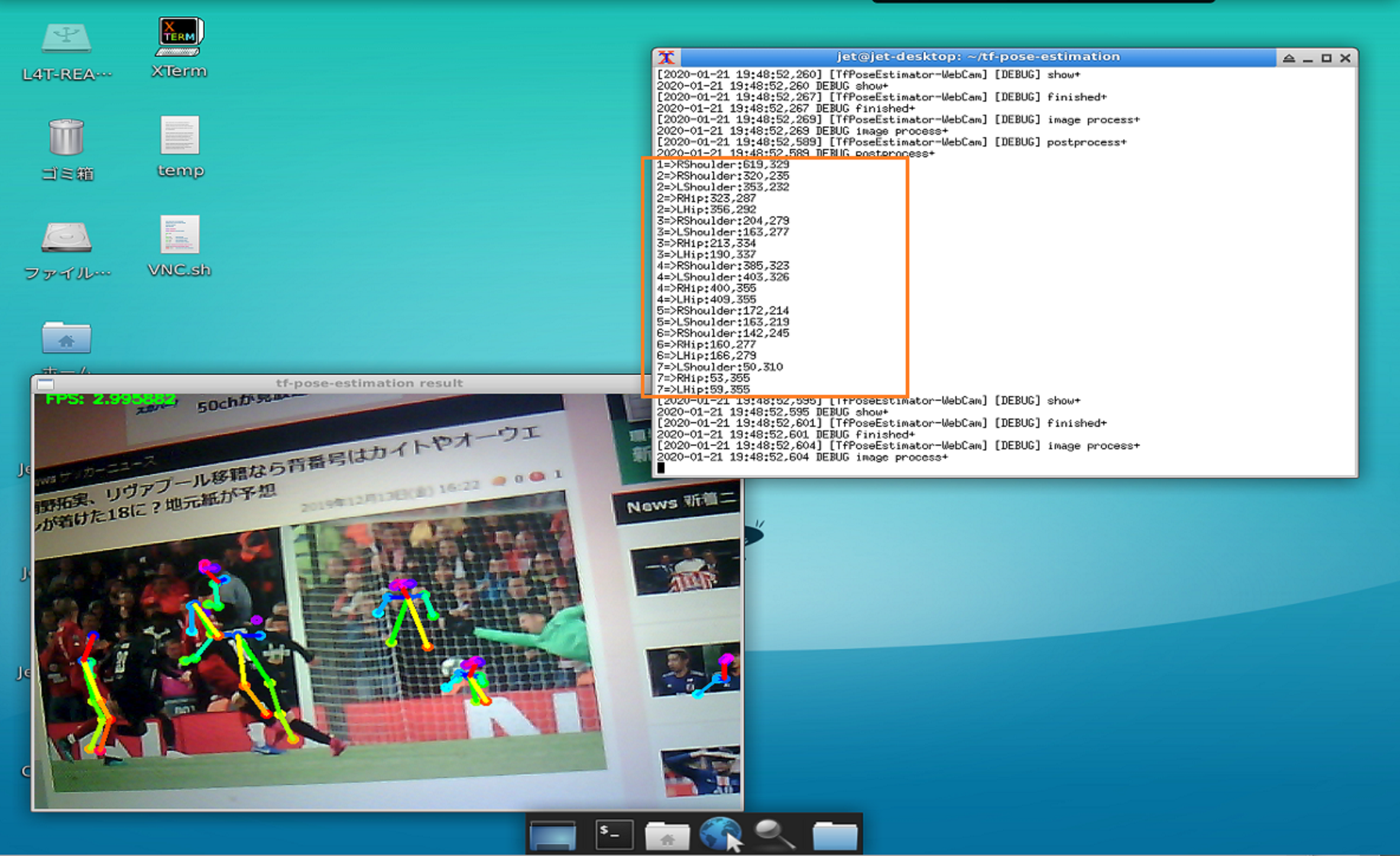
検出された人体ごとの各パーツの座標を表示しデータを取得するようにしています。
後はこれらのデータをdraw_humansが呼び出されるごとにファイルに落とすかDBに記録するようにすればいいと思います。
データはdraw pointで首・鼻・両目・両耳、draw lineで肩の2点と腰の2点を採取しています。
外部で変数を1個定義しておきます(フレーム番号用)。
fr_num = 0
データはフレーム単位で取得します。
この関数内の「#ここ」で示した8つ場所でコードを追加しました。最後にデータを追記で保存しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 |
def draw_humans(npimg, humans, imgcopy=False): global fr_num #ここ fr_num = fr_num + 1 #ここ id_num = 0 #ここ data_a = "" #ここ data_b = "" #ここ if imgcopy: npimg = np.copy(npimg) image_h, image_w = npimg.shape[:2] centers = {} for human in humans: id_num = id_num + 1 # draw point for i in range(common.CocoPart.Background.value): if i not in human.body_parts.keys(): continue body_part = human.body_parts[i] center = (int(body_part.x * image_w + 0.5), int(body_part.y * image_h + 0.5)) centers[i] = center cv2.circle(npimg, center, 3, common.CocoColors[i], thickness=3, lineType=8, shift=0) #ここ coordinate = str(center[0]) + "," + str(center[1]) if(i == 0): print(str(id_num) + "=>" + "Nose:" + coordinate) data_a = data_a + str(id_num) + "," + "Nose," + coordinate + "\n" elif(i == 1): print(str(id_num) + "=>" + "Neck:" + coordinate) data_a = data_a + str(id_num) + "," + "Neck," + coordinate + "\n" elif(i == 14): print(str(id_num) + "=>" + "REye:" + coordinate) data_a = data_a + str(id_num) + "," + "REye," + coordinate + "\n" elif(i == 15): print(str(id_num) + "=>" + "LEye:" + coordinate) data_a = data_a + str(id_num) + "," + "LEye," + coordinate + "\n" elif(i == 16): print(str(id_num) + "=>" + "REar:" + coordinate) data_a = data_a + str(id_num) + "," + "REar," + coordinate + "\n" elif(i == 17): print(str(id_num) + "=>" + "LEar:" + coordinate) data_a = data_a + str(id_num) + "," + "LEar," + coordinate + "\n" # draw line for pair_order, pair in enumerate(common.CocoPairsRender): if pair[0] not in human.body_parts.keys() or pair[1] not in human.body_parts.keys(): continue # npimg = cv2.line(npimg, centers[pair[0]], centers[pair[1]], common.CocoColors[pair_order], 3) cv2.line(npimg, centers[pair[0]], centers[pair[1]], common.CocoColors[pair_order], 3) #ここ coordinates = str(centers[pair[1]][0]) + "," + str(centers[pair[1]][1]) if(pair[0] == 1 and pair[1] == 2): print(str(id_num) + "=>" + "RShoulder:" + coordinates) data_b = data_b + str(id_num) + "," + "RShoulder," + coordinates + "\n" elif (pair[0] == 1 and pair[1] == 5): print(str(id_num) + "=>" + "LShoulder:" + coordinates) data_b = data_b + str(id_num) + "," + "LShoulder," + coordinates + "\n" elif (pair[0] == 1 and pair[1] == 8): print(str(id_num) + "=>" + "RHip:" + coordinates) data_b = data_b + str(id_num) + "," + "RHip," + coordinates + "\n" elif (pair[0] == 1 and pair[1] == 11): print(str(id_num) + "=>" + "LHip:" + coordinates) data_b = data_b + str(id_num) + "," + "LHip," + coordinates + "\n" else: pass #ここ if(data_b != ""): data_c = "frame" + str(fr_num) + "\n" + data_a + data_b with open('data.txt', 'a') as f: f.write(data_c) f.close() return npimg |
こんな感じです。検出される人物IDは選手なのか観客なのか区別できませんので、この辺工夫が必要ですけど。
昨今のAIの界隈では、動画内の特定の人物を追跡したり、画像処理でその人物を「居なかったことにする」のも可能なようです(GANを使ってます)。また、解像度が低い画像の場合は推定が困難になりますが、この場合も論文に触れられている「超解像」が役に立ちそうです。超解像というのは例えばこんな感じのものです。
ここでは、2,3,4のIDを持った人物が肩2点と腰2点の4つのデータを持っています。そのうちの1人は多分ゴール裏の観客です。
OpenPoseは規約で商用利用にはライセンスが必要なようで、さらにたとえ商用利用であってもスポーツの分野では使っちゃダメなんだそうです。
非商用の個人利用などはもちろんOKです。
ちなみに、姿勢推定にはOpenPose以外にこういうのもあります。
paperで使われる方法はExpected Goalsのモデルにも有効なようです。
Expected Goals(得点期待値に関する新指標「xG」)は結構有名な指標だそうです。
フットボール・データアナリティクス:得点期待値に関する新指標「xG」についての解説
Leave a Reply