
Jetson Nano を使って転移学習をやってみます。
転移学習とはなんぞや(分かってる人には分かりやすく、分かってない人には分かりにくい説明^^)。
このページで作成しておいた、Jetson Nano(4GB)+Jetpack(4.4.1) + NVIDIA Container + Pytorch + TensorRT の環境です。
転移学習でモデルを再トレーニングする場合、メモリを大量に消費するのでデスクトップ環境は使いません。
CUI環境に変更します。また、CPU・GPUがフルに稼働するので冷却ファンは必須です。
Swapは4GBほど確保しておきます。
|
1 2 3 |
sudo fallocate -l 4G /mnt/4GB.swap sudo mkswap /mnt/4GB.swap sudo swapon /mnt/4GB.swap |
永続化します。
|
1 |
/mnt/4GB.swap none swap sw 0 0 |
Disabling the Desktop GUI
Jetson NanoのRAMメモリは4GBしかありません。
メモリを節約するため、Desktopを停止して、CUIでやってみます。
以下を実行することで、ウィンドウマネージャーとデスクトップが使用する余分なメモリが解放されます。
|
1 |
sudo init 3 |
Nano 2GBではなぜかinitが効きませんでしたので、CUI環境は以下のように設定します。
sudo systemctl set-default multi-user.target
sudo reboot
GUIに戻す
sudo systemctl set-default graphical.target
sudo reboot
CUI画面になります(2バイトキャラは文字化けしています)。
jetson-statsで実行状況をモニターしたり、スクリーンショットを撮ったりする場合は、仮想コンソールや、SSHを使います。
複数のコンソールを開く場合は、仮想コンソールなら、Alt + F2~F6で開きます。Alt + F1 で初期コンソールに復帰します(chvt 番号でも可)。
あるいは、Tera TermなどでSSHを複数接続して開きます。
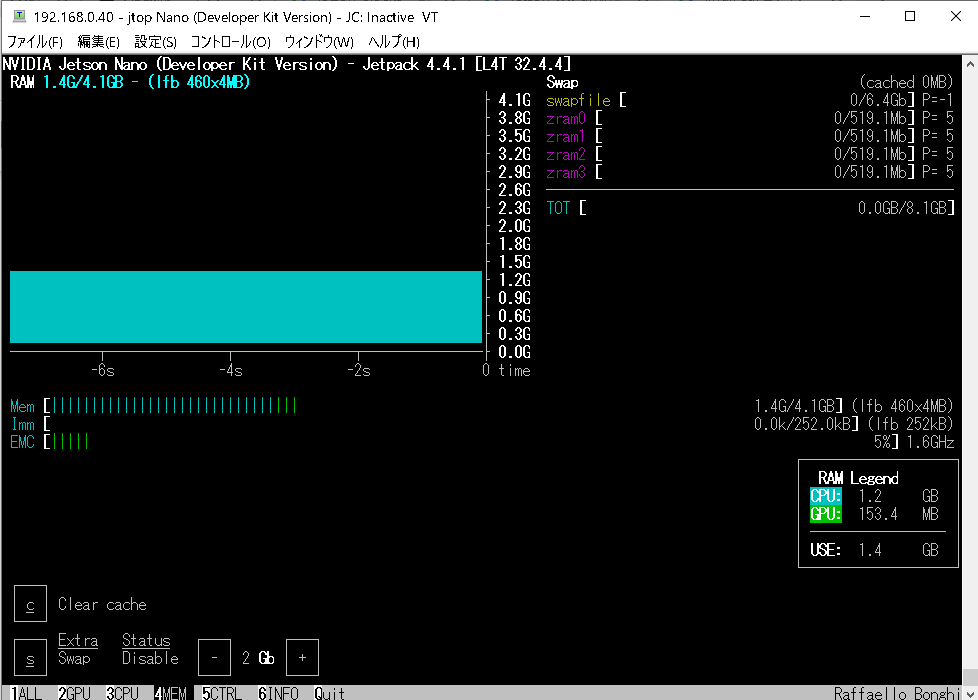
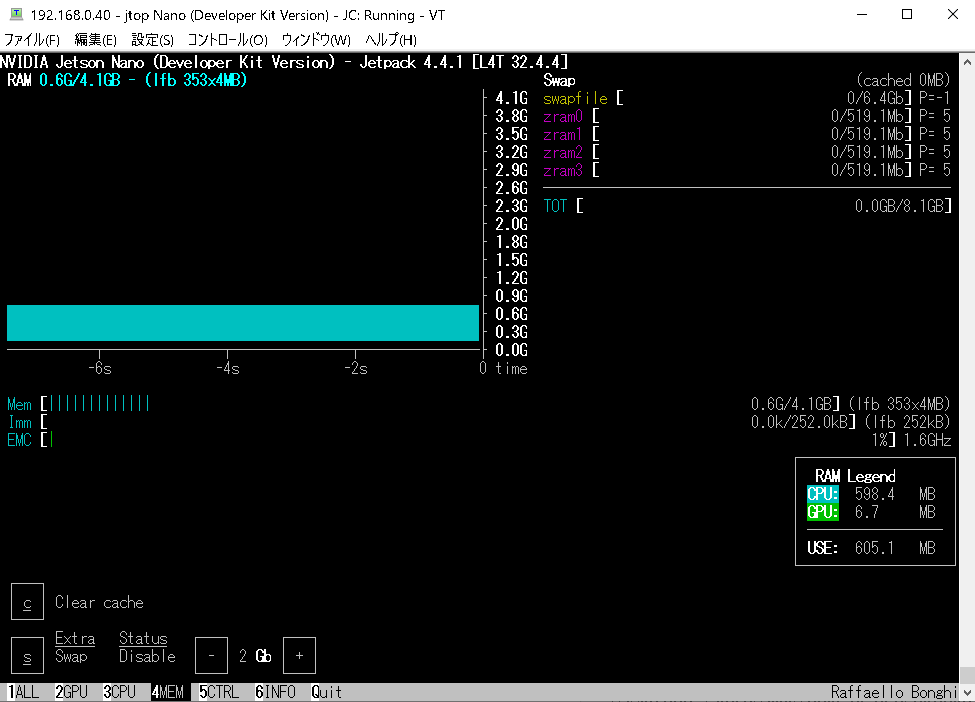
CUIの環境ならメモリーはこの程度(約700~800MB、2GB版のLXDEなら300MBくらい)節約できます。
Desktop使用時
Desktopを使わない場合
Dockerを起動
Dockerの作成などはこのページをご参照ください。コンテナ名はmy_cont にしています。
Is the docker daemon running? というメッセージが出たら以下を実行。
sudo dockerd
|
1 |
sudo docker start -i my_cont |
【転移学習(Transfer Learning)】
Re-training on the Cat/Dog Dataset
Cat/Dogのデータセットを再トレーニングします。
ResNet-18を使ったイヌ科とネコ科の2クラス分類です。
以下は、独自のデータを収集して独自のカスタマイズされたモデルを作成することに加えて、転移学習を使用していくつかのサンプルデータセットでモデルを再トレーニングするためのステップバイステップの手順です。
Downloading the Data
トレーニング用のデータセットをダウンロードして解凍
|
1 2 3 |
cd /jetson-inference/python/training/classification/data wget https://nvidia.box.com/shared/static/o577zd8yp3lmxf5zhm38svrbrv45am3y.gz -O cat_dog.tar.gz tar xvzf cat_dog.tar.gz |
Cat と Dog それぞれで、
学習用データ:2500枚 x 2
/jetson-inference/python/training/classification/data/cat_dog/train/cat
/jetson-inference/python/training/classification/data/cat_dog/train/dog
検証用データ:500枚 x 2
/jetson-inference/python/training/classification/data/cat_dog/val/cat
/jetson-inference/python/training/classification/data/cat_dog/val/dog
テスト用データ:100枚 x 2
/jetson-inference/python/training/classification/data/cat_dog/test/cat
/jetson-inference/python/training/classification/data/cat_dog/test/dog
Re-training ResNet-18 Model
RessNet-18 モデルを使って再トレーニング
モデルのresnet18-5c106cde.pth はtrain.py の実行中にダウンロードされます。
|
1 2 |
cd /jetson-inference/python/training/classification python3 train.py --model-dir=models/cat_dog data/cat_dog |
epoch数はデフォルトで35、再トレーニングは大体4時間くらいが想定されます。
Nano 4GBで大体4時間、2GB版ならSwapを使うことになりますが、それでも4時間半くらいで実行完了しました。Xavier NX なら2時間ほどです。
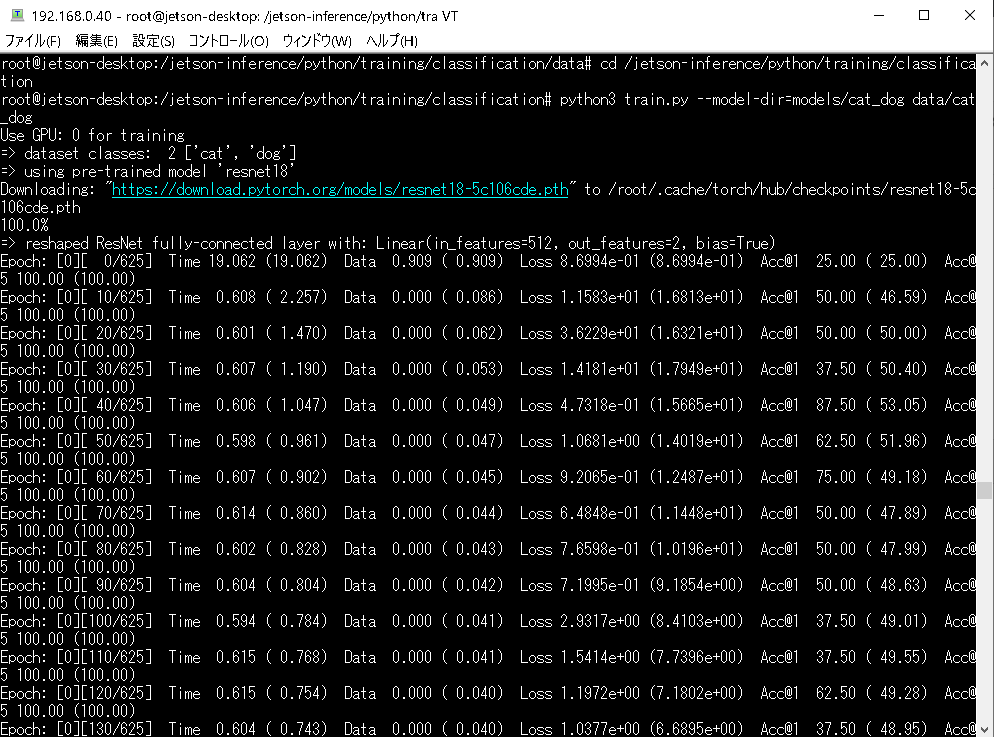
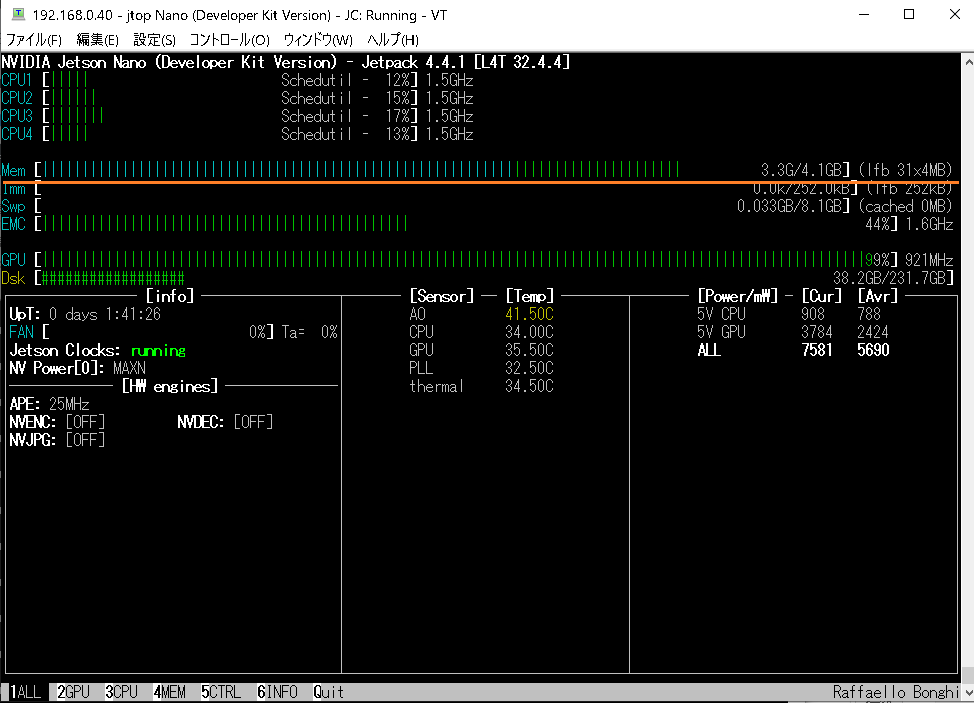
jetson-statsを見てみます。
GPUはフル稼働状態です。メモリはCUIのみの環境なので余裕がありますが、デスクトップ環境で使っていれば、ほぼ満杯状態だと思われます。
冷却ファンは必須です。無いと回路周りの温度が60度くらいになって、Warningが出続けます。
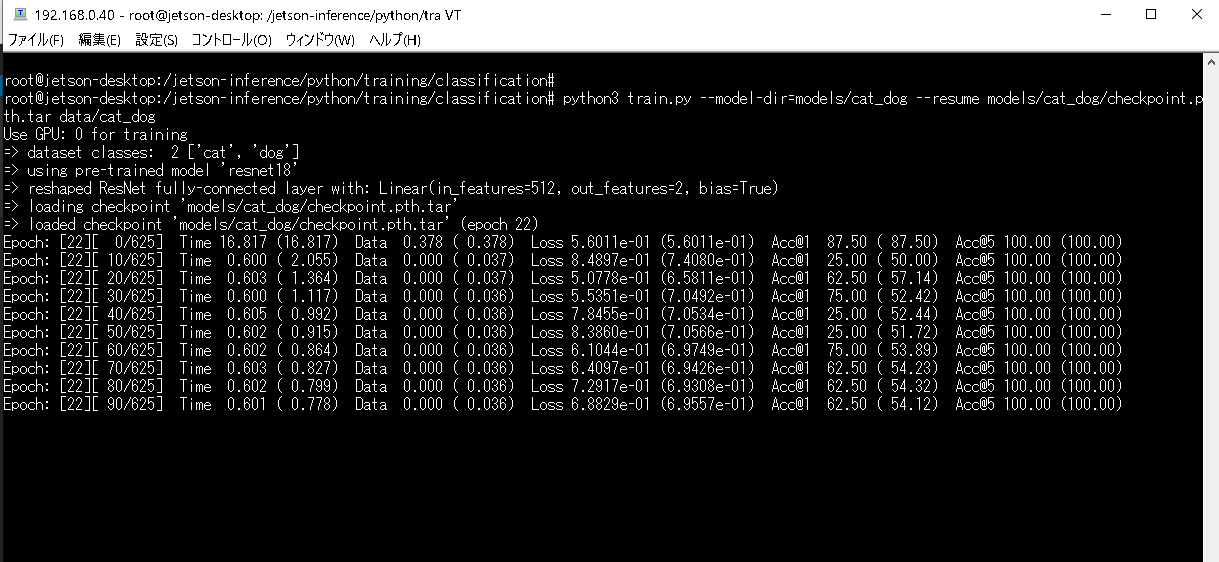
トレーニングは中断->再開ができます。
Ctr + C で中断。
再開する場合は resumeオプションを使います。引数の並びはこうです。
epoch-start(マニュアルでは start-epoch)はオプションであり、厳密には必須ではありません….だそうです。
|
1 |
python3 train.py [モデルの場所] --resume [checkpoint指定] [データセットの場所] |
Cat/Dog の場合はこうです。
|
1 2 |
cd /jetson-inference/python/training/classification python3 train.py --model-dir=models/cat_dog --resume models/cat_dog/checkpoint.pth.tar data/cat_dog |
epoch の途中で中断した場合、再開はepoch の初めからになります。
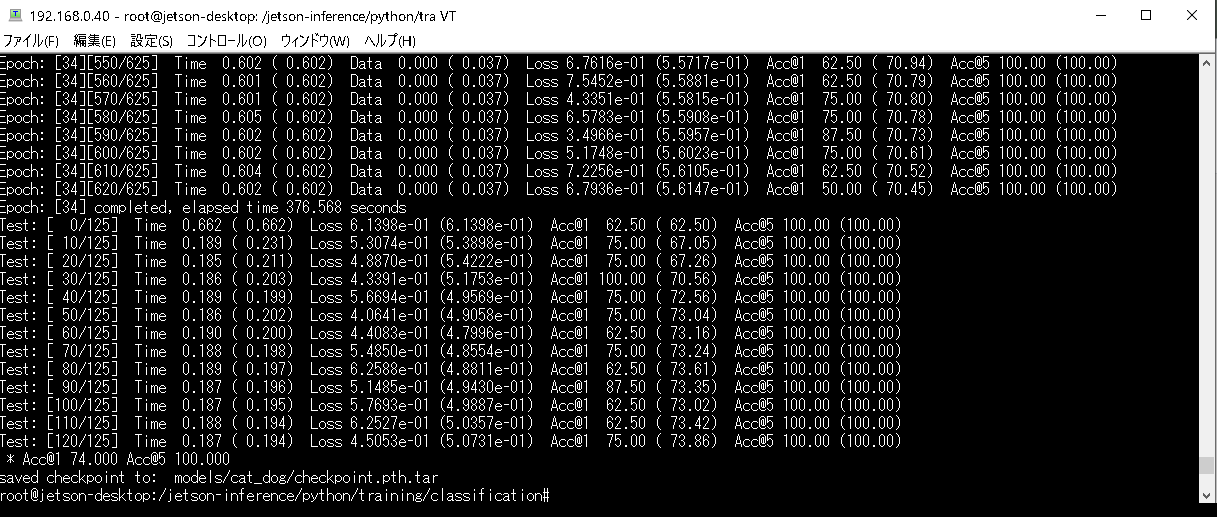
再トレーニング終了
train.py のマニュアル
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
usage: train.py [-h] [--model-dir MODEL_DIR] [-a ARCH] [--resolution N] [-j N] [--epochs N] [--start-epoch N] [-b N] [--lr LR] [--momentum M] [--wd W] [-p N] [--resume PATH] [-e] [--pretrained] [--world-size WORLD_SIZE] [--rank RANK] [--dist-url DIST_URL] [--dist-backend DIST_BACKEND] [--seed SEED] [--gpu GPU] [--multiprocessing-distributed] DIR PyTorch ImageNet Training positional arguments: DIR path to dataset optional arguments: -h, --help show this help message and exit --model-dir MODEL_DIR path to desired output directory for saving model checkpoints (default: current directory) -a ARCH, --arch ARCH model architecture: alexnet | densenet121 | densenet161 | densenet169 | densenet201 | googlenet | inception_v3 | mnasnet0_5 | mnasnet0_75 | mnasnet1_0 | mnasnet1_3 | mobilenet_v2 | resnet101 | resnet152 | resnet18 | resnet34 | resnet50 | resnext101_32x8d | resnext50_32x4d | shufflenet_v2_x0_5 | shufflenet_v2_x1_0 | shufflenet_v2_x1_5 | shufflenet_v2_x2_0 | squeezenet1_0 | squeezenet1_1 | vgg11 | vgg11_bn | vgg13 | vgg13_bn | vgg16 | vgg16_bn | vgg19 | vgg19_bn | wide_resnet101_2 | wide_resnet50_2 (default: resnet18) --resolution N input NxN image resolution of model (default: 224x224) note than Inception models should use 299x299 -j N, --workers N number of data loading workers (default: 2) --epochs N number of total epochs to run --start-epoch N manual epoch number (useful on restarts) -b N, --batch-size N mini-batch size (default: 8), this is the total batch size of all GPUs on the current node when using Data Parallel or Distributed Data Parallel --lr LR, --learning-rate LR initial learning rate --momentum M momentum --wd W, --weight-decay W weight decay (default: 1e-4) -p N, --print-freq N print frequency (default: 10) --resume PATH path to latest checkpoint (default: none) -e, --evaluate evaluate model on validation set --pretrained use pre-trained model --world-size WORLD_SIZE number of nodes for distributed training --rank RANK node rank for distributed training --dist-url DIST_URL url used to set up distributed training --dist-backend DIST_BACKEND distributed backend --seed SEED seed for initializing training. --gpu GPU GPU id to use. --multiprocessing-distributed Use multi-processing distributed training to launch N processes per node, which has N GPUs. This is the fastest way to use PyTorch for either single node or multi node data parallel training |
Converting the Model to ONNX
再トレーニングされたResNet-18モデルをTensorRTで実行するには、PyTorchモデルをONNX形式に変換して、TensorRTがロードできるようにする必要があります。
ちなみに、上記再トレーニングでアップデートされるファイルは以下の4つです。
/jetson-inference/python/training/classification/models/cat_dog
● checkpoint.pth.tar
● labels.txt
● model_best.pth.tar
● tensorboardフォルダー内のファイル
提供されている onnx_export.py スクリプトで Cat/Dog モデルを変換します。
ディレクトリは上記と同じ
/jetson-inference/python/training/classification
|
1 |
python3 onnx_export.py --model-dir=models/cat_dog |
これで、resnet18.onnxというモデルがアップデートされます。
/jetson-inference/python/training/classification/models/cat_dog/resnet18.onnx
Processing Images with TensorRT
TensorRTで画像を処理します。
例えばcat画像で推論実行。
画像はdata/cat_dog/test/cat/02.jpg、実行結果はcat_02.jpgという画像で出力します。
X11への接続が要求されますが、無くてもOKです(気になる方はコンテナ起動前にsudo xhost si:localuser:rootを実行しておきます)。
imagenet.py --model=models/cat_dog/resnet18.onnx --input_blob=input_0 --output_blob=output_0 --labels=data/cat_dog/labels.txt data/cat_dog/test/cat/02.jpg cat_02.jpg
上記のドッカースクリプトでコンテナを作成した場合、以下の場所が共有されています。
コンテナ ホスト
/jetson-inference/build/aarch64/bin/images/test <—-> ~/work/jetson-inference/data/images/test
以下のように実行すれば結果画像は共有ディレクトリに出力されるのでホスト側で直接見ることができます。
imagenet.py --model=models/cat_dog/resnet18.onnx --input_blob=input_0 --output_blob=output_0 --labels=data/cat_dog/labels.txt data/cat_dog/test/cat/02.jpg /jetson-inference/build/aarch64/bin/images/test/cat_02.jpg
初回はresnet18.onnxが読み込まれてコンパイルされるので少々時間がかかります。コンパイル後のモデルは/resnet18.onnx.1.1.8201.GPU.FP16.engineなどの名前で以下に保存されています(.engineの拡張子があればTensorRTで読み込めます)。
/jetson-inference/python/training/classification/models/cat_dog/resnet18.onnx.1.1.8201.GPU.FP16.engine
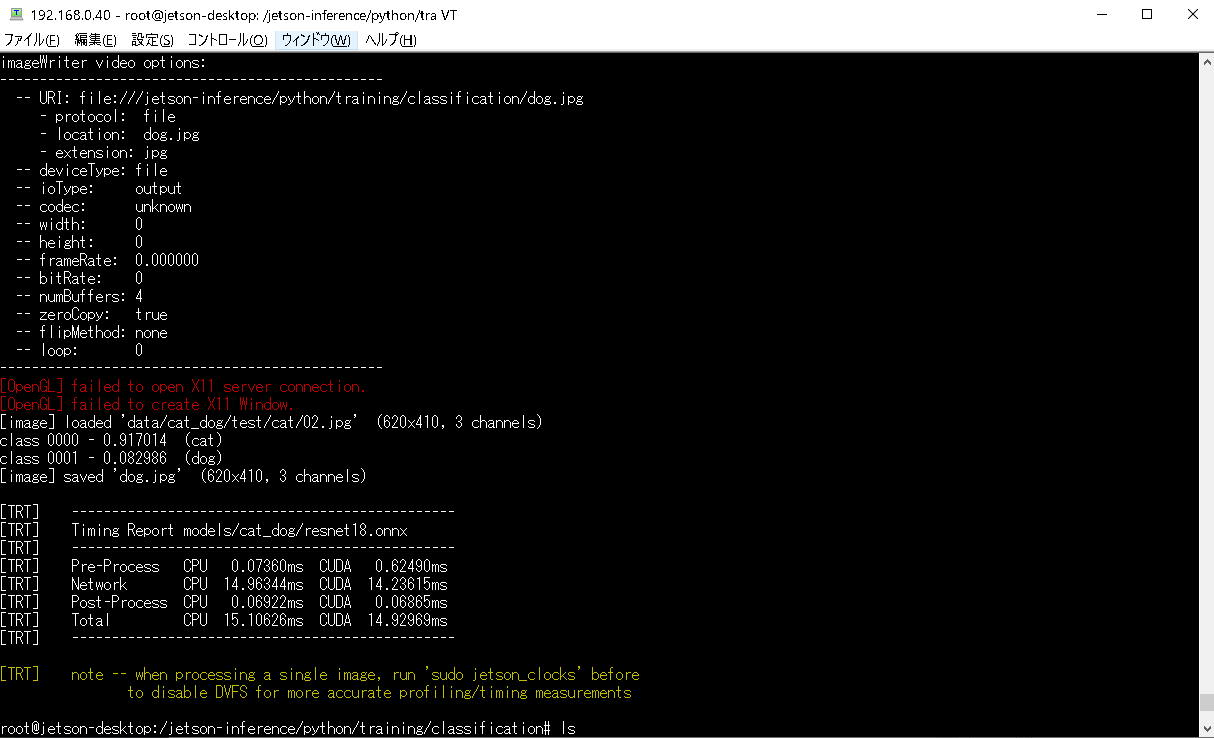
結果画像を共有ディレクトリに出力しない場合、画像は以下に出力されています。
/jetson-inference/python/training/classification/cat_02.jpg
この場合コンテナ内の画像は直接見れないのでホスト側にコピーします。
コンテナのIDを調べます。
|
1 |
sudo docker container ps -a |
画像をフルパスで指定します、こんな感じ。
sudo docker cp <コンテナのID>:/jetson-inference/python/training/classification/cat_02.jpg ~/cat_02.jpg
ホストのホームディレクトリに画像がコピーされます。
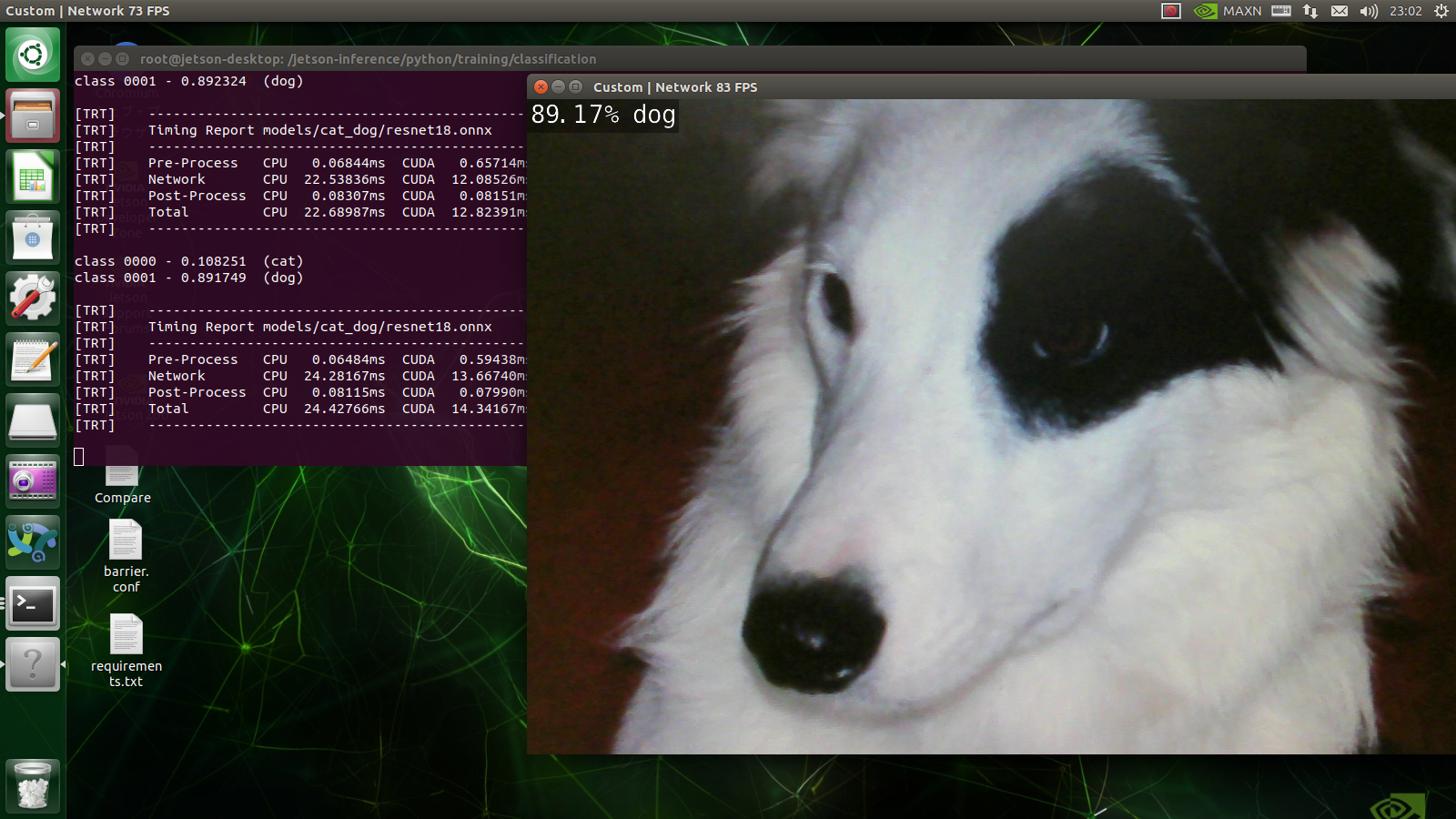
画像の左上に「91.70%の確からしさで猫」が表示されています。

Dogの画像はどうでしょう。
推論(コンテナで実行)
imagenet.py --model=models/cat_dog/resnet18.onnx --input_blob=input_0 --output_blob=output_0 --labels=data/cat_dog/labels.txt data/cat_dog/test/dog/02.jpg dog_02.jpg
結果をコピー(ホストで実行)
sudo docker cp 8be5ccad5b84:/jetson-inference/python/training/classification/dog_02.jpg ~/dog_02.jpg
「87.43%の確からしさで犬」

Processing all the Test Images
テスト画像(100枚)をすべて使って検証してみます。
出力用のフォルダーを作っておきます。
|
1 2 |
cd /jetson-inference/python/training/classification mkdir data/cat_dog/test_output_cat data/cat_dog/test_output_dog |
実行。
imagenet --model=models/cat_dog/resnet18.onnx --input_blob=input_0 --output_blob=output_0 --labels=data/cat_dog/labels.txt data/cat_dog/test/cat data/cat_dog/test_output_cat
imagenet --model=models/cat_dog/resnet18.onnx --input_blob=input_0 --output_blob=output_0 --labels=data/cat_dog/labels.txt data/cat_dog/test/dog data/cat_dog/test_output_dog
結果を確認しました、こんな感じ。
ネコ科の正解:61/100
イヌ科の正解:79/100
イヌ科はチュートリアルに近い正解率ですが、ネコ科が低いです。
テスト画像にイヌ科の動物(タヌキやキツネ)が居ないか少なかったから?
epoch を60にして再トレーニングしても結果は同じでしたね。
現在、ネコ科(2500)、イヌ科(2500)ですが画像を増やしてやってみる必要がある…..かも。
下記のGenerating More Data (Optional)にあるスクリプトを使って訓練画像5000枚/epoch 35で再トレーニングしてみましたが正解率はだいたいこんなものでした。テスト画像を再生成して5回ほど検証してみた結果では正解率はネコ科で60%程度に収まりました。
Running the Live Camera Program
カメラプログラムを実行して、それがどのように機能するかを確認できます。
ホスト側でX セッションへのアクセスを許可。
|
1 |
sudo xhost si:localuser:root |
ラズパイ用のカメラ(V2)
imagenet.py --model=models/cat_dog/resnet18.onnx --input_blob=input_0 --output_blob=output_0 --labels=data/cat_dog/labels.txt csi://0
USBカメラ(単体で接続している場合、カメラ番号は0)
imagenet.py --model=models/cat_dog/resnet18.onnx --input_blob=input_0 --output_blob=output_0 --labels=data/cat_dog/labels.txt /dev/video0
Generating More Data (Optional)
Cat / Dogデータセットの画像は、cat-dog-dataset.shスクリプトを使用して、ILSCRV12のより大きな22.5GBサブセットからランダムに取得されました。 この最初のCat / Dogデータセットは、トレーニング時間を短縮するために意図的に小さく保たれていますが、このスクリプトを使用すると、追加の画像を使用してデータセットを再生成し、より堅牢なモデルを作成できます。
Cat / Dogデータセットを拡張する場合は、最初にここからソースデータをダウンロードします。
データセットが大きいほどトレーニングに時間がかかります。
Next1
ここでは事前学習モデル(Pre trained Model)はResNet-18が使われています。
違うモデル(SSD-Mobilenet)を使ってみます。
Next2
自前の学習データを収集してやってみます。
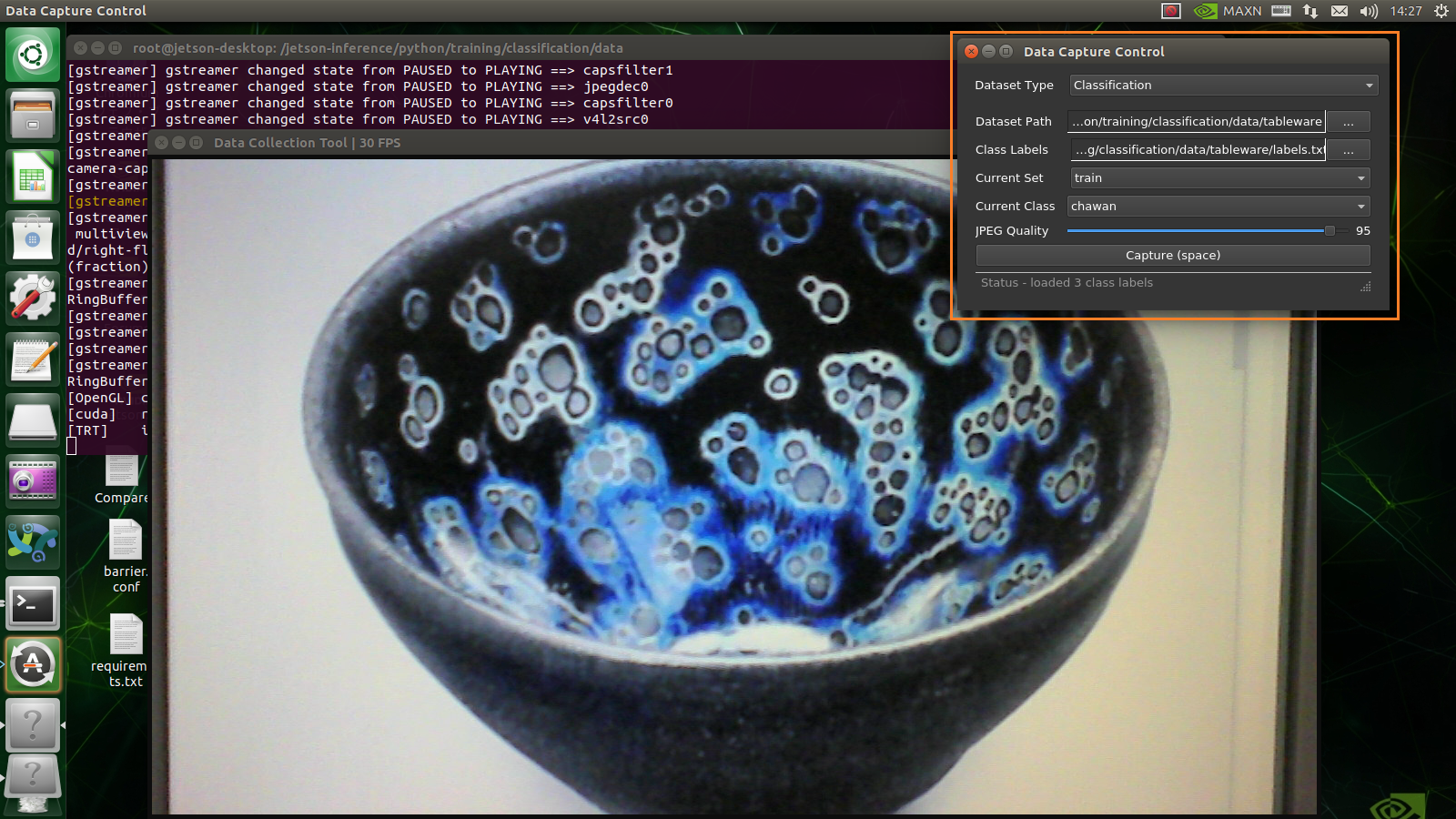
Collecting your own Classification Datasets
便利なツールをご用意しました…….とあるので使ってみます。
カメラ画面からデータを作成
Next3
Deep Learning Nodes for ROS/ROS2
ROS/ROS2(Robot Operating System)でディープラーニング処理(process/thread)
SLAMに続く
Jetson Nano(2GB)冷却ファン

Appendix
NVIDIAのTransfer Learing についてはここも参照
NVIDIA Transfer Learning Toolkit
注:TLT(Transfer Learning Toolkit)のコンテナーはx_86アーキテクチャーのプラットフォームでのみ実行できます。TLTでトレーニングされたモデルは、Jetsonを含むすべてのNVIDIAプラットフォームにデプロイできます。
Leave a Reply