
NVIDIA提供のコンテナーでいくつかのネットワークモデルを使って推論をやってみます。
Jetson Nanoでどんなことがやれるのか試してみましょう(もう少しパワーが欲しいという場合の次の選択肢はXavier NXになると思います)。
別途、転移学習もやってみます。
Jeyson Nano + Jetpack (4.4.1)のセットアップは済んでいるものとします。
以下のコンテンツをやってみましょう。
GithubにあるDustin Franklinさんのjetson-inferense 参照
Hello AI World
Classifying Images with ImageNet
をやってみましょう。
以下のバージョンのイメージをDocker Hub からpull。
|
1 |
sudo docker pull dustynv/jetson-inference:r32.4.4 |
Jetsonのパフォーマンスを最大化しておきましょう。
CPUやGPUのクロックを変更する前と後では全然違います。
|
1 |
sudo jetson_clocks |
走っているかどうかは、jetson-stats(jtop)で確認できます。走っていない場合はInactiveになっています。
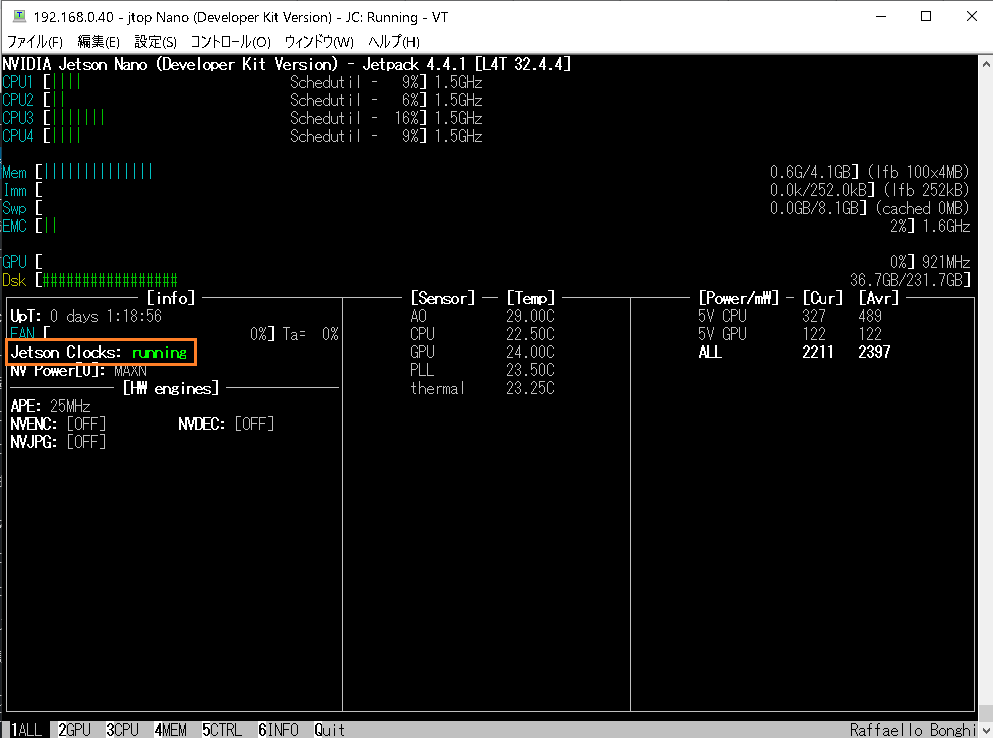
ちなみに解除する場合は以下を実行すればいいようです。
|
1 |
sudo nvpmodel -m 0 |
作業用のフォルダーを作っておきましょう。
|
1 2 |
mkdir work cd work |
Launching the Container
jetson-inferense をクローンして、
|
1 |
git clone --recursive https://github.com/dusty-nv/jetson-inference |
デフォルト設定ではrunとrmが指定されていて自動的にコンテナが起動します。コンテナーを永続化する場合はrun.shを編集します。この場合は、名前を指定して明示的に起動させます(sudo docker start -i my_cont)
|
1 2 |
cd jetson-inference docker/run.sh |
ダウンロードするネットワークモデルを聞いてきます。
とりあえずデフォルトのまま了解します。
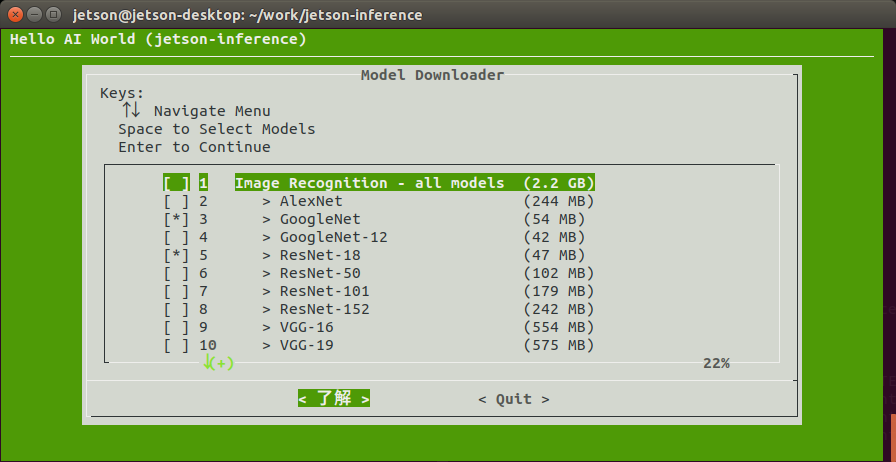
ダウンロード開始。
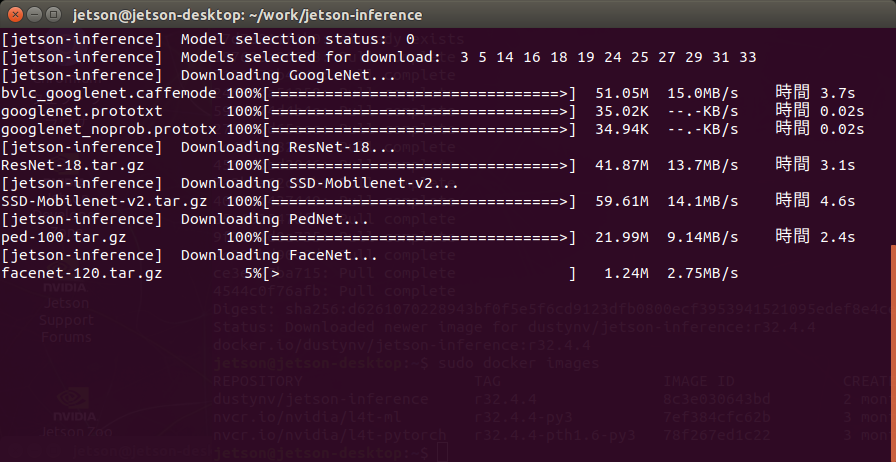
ホスト側に学習済のネットワークモデルがダウンロードされます(data/networks)。
|
1 2 3 4 5 6 |
DDetectNet-COCO-Dog FCN-ResNet18-SUN-RGBD-512x400 googlenet.prototxt FCN-ResNet18-Cityscapes-1024x512 ResNet-18 googlenet_noprob.prototxt FCN-ResNet18-Cityscapes-512x256 SSD-Mobilenet-v2 ped-100 FCN-ResNet18-DeepScene-576x320 bvlc_googlenet.caffemodel FCN-ResNet18-MHP-512x320 facenet-120 FCN-ResNet18-Pascal-VOC-320x320 |
その後、コンテナーが起動、ホスト側の画像データやネットワークモデルのディレクトリはコンテナからマウントされています。
コンテナーのバージョンはこんな感じ。
Ubuntu(18.04.5 LTS)
Python(3.6.9)
appdirs (1.4.4)
boto3 (1.16.3)
botocore (1.19.3)
Cython (0.29.21)
dataclasses (0.7)
decorator (4.4.2)
future (0.18.2)
jmespath (0.10.0)
Mako (1.1.3)
MarkupSafe (1.1.1)
numpy (1.19.2)
pandas (1.1.3)
Pillow (8.0.0)
pip (9.0.1)
pycuda (2020.1)
python-dateutil (2.8.1)
pytools (2020.4.3)
pytz (2020.1)
s3transfer (0.3.3)
setuptools (50.3.2)
six (1.15.0)
torch (1.6.0)
torchaudio (0.6.0a0+f17ae39)
torchvision (0.7.0a0+78ed10c)
urllib3 (1.25.11)
wheel (0.35.1)
CUDA(19.2.89)
cuDNN(8.0.0.0)
アップデート&アップグレードします。
|
1 2 3 4 |
apt update apt upgrade -y python3 -m pip install --upgrade pip |
Running Applications
アプリケーションを使ってみます。
|
1 |
cd build/aarch64/bin |
【inference(推論)を実行してみます】
TensorRTを使います。TensorRTを使うと何がうれしいのかはこのブログ参照。
TensorRT は、NVIDIA製の高性能ディープラーニング推論最適化・実行ライブラリです。TensorRT を用いるとネットワークが最適化され、低レイテンシ・高スループットの推論を実現することができる……そうです。
初回のネットワークモデルの読み込みとコンパイル、推論にはJetson Nano だと2~3分くらいかかります。
2回目以降の推論実行は、高速化されます。
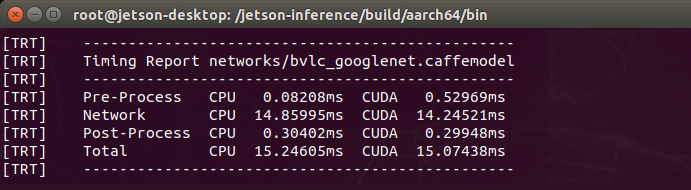
CPU・GPUのパフォーマンスのレポートはこんな感じ(Imagenetを使った場合)。
jetson_clocksでクロック変更前
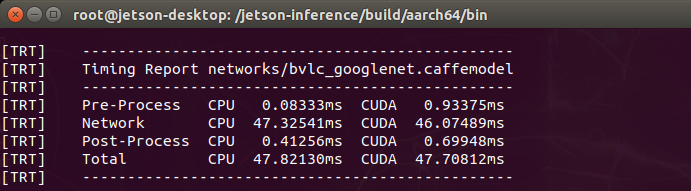
クロック変更後
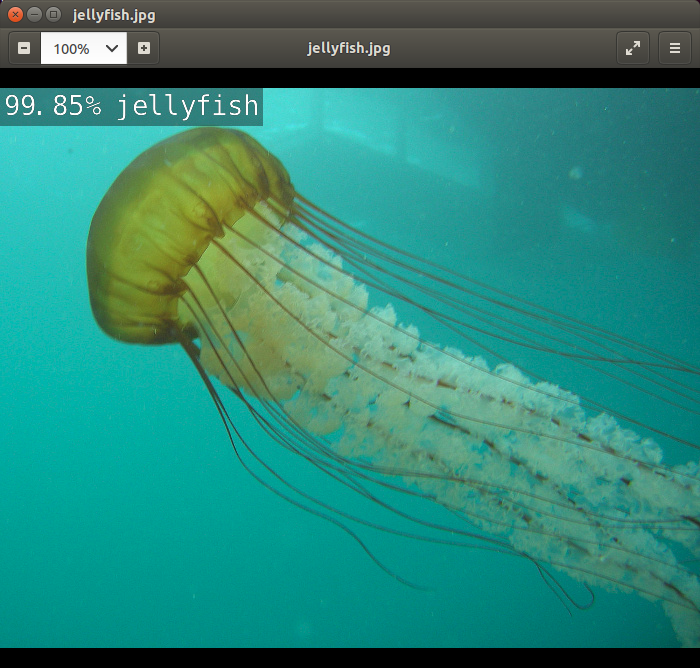
この画像が何なのか推論してみます。

|
1 |
./imagenet images/jellyfish.jpg images/test/jellyfish.jpg |
初回はコンパイルとモデルの読み込みと推論が実行されます。結構時間がかかります。
コンテナ作成に使われたrun.shの中では、コンテナ側のいろいろなディレクトリがホスト側にマウントされています。イメージ用のディレクトリでは以下のようになっています。
推論された結果をホストから確認できます。結果画像には左上に確からしさが%で示されています。
(コンテナ)/jetson-inference/build/aarch64/bin/images/test/jellyfish.jpg
(ホスト)~/work/jetson-inference/data/images/test/jellyfish.jpg
確認してみます。
99.85%の確からしさで「クラゲ」という結果が出力されています。
次にスイカをやってみます。
|
1 |
./imagenet images/fruit_6.jpg images/test/fruit_6.jpg |
2回目以降は画像の読み込みと推論のみ実行されるので、時間はさほどかかりません。
でもキャベツだと判断してます、間違ってますね。

|
1 |
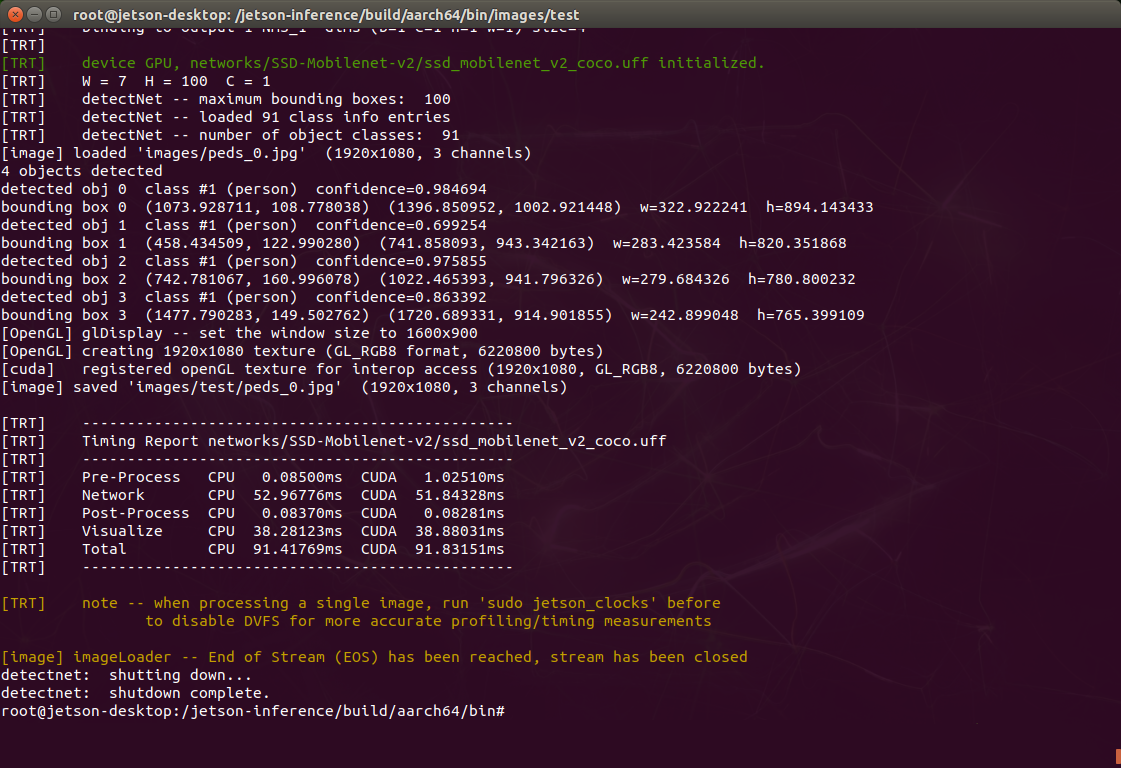
./detectnet images/peds_0.jpg images/test/peds_0.jpg |

画像内のオブジェクト検出


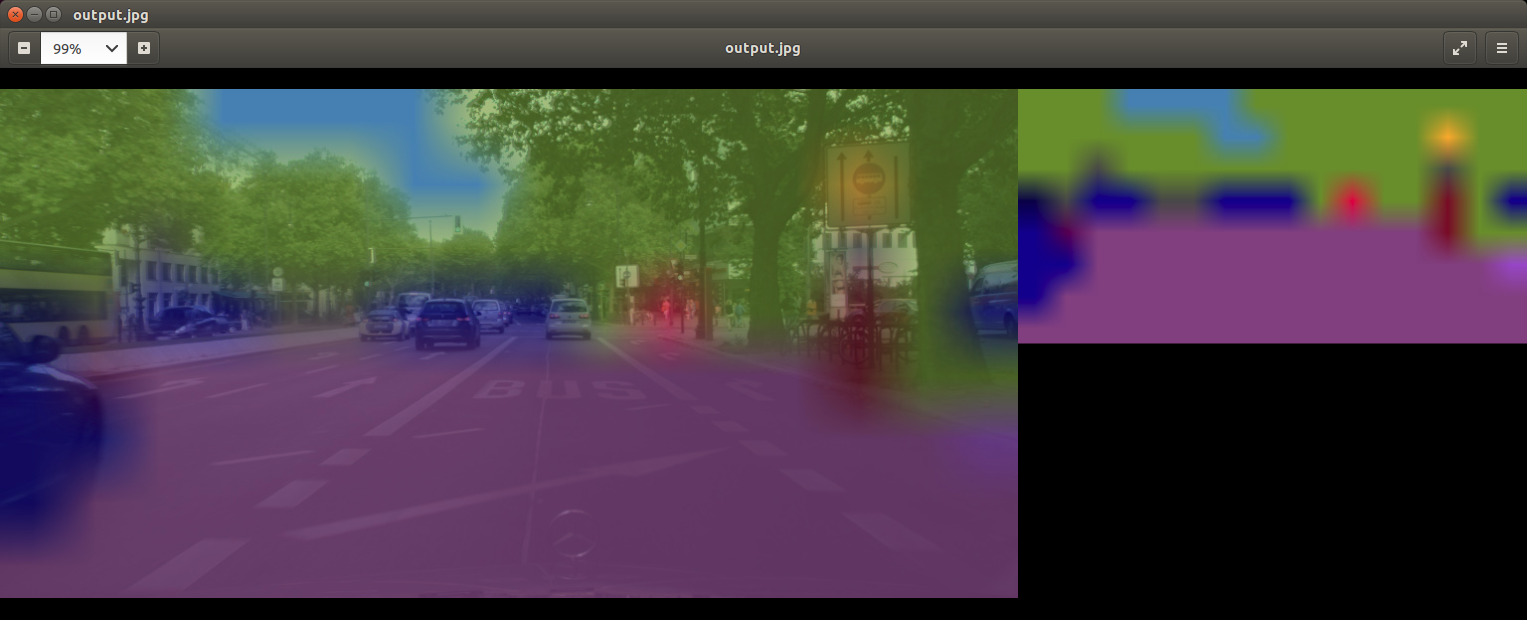
Segnetを使った画像分割(Semantic Segmentation)
以下のような画像からオブジェクトを分割・分離してみます。

|
1 |
./segnet.py --network=fcn-resnet18-cityscapes images/city_0.jpg images/test/output.jpg |
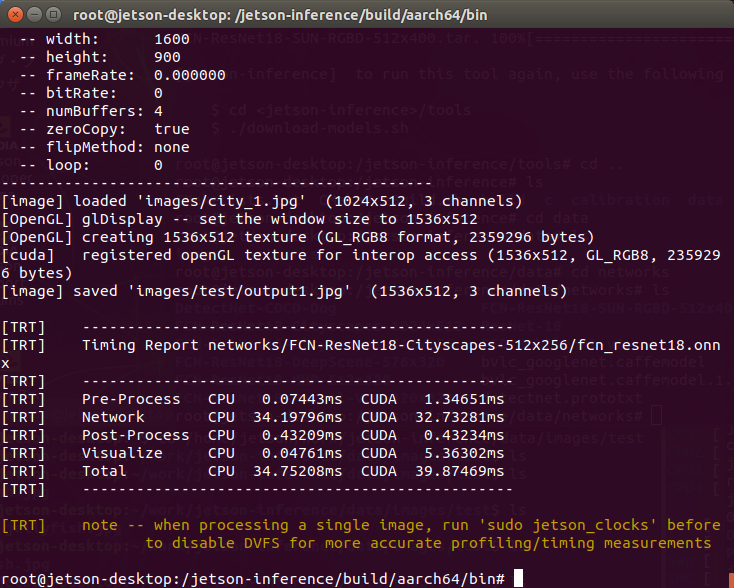
こんな感じ。

【カメラを使ってみます(video-viewer)】
カメラのタイプでオプションが変わります。
いろいろなカメラが使えますが、通常はこの2つのカメラが一般的です。
Jetsonは産業用途の使用も想定されているので、ネットワークカメラなどにも対応しています。
Camera Streaming and Multimedia
●ラズパイ用のカメラ(V2) ー> MIPI CSI camera

●USBカメラ -> V4L2 camera

2つ同時に使うと、カメラ番号は大概こんな感じになります。
ラズパイ用のカメラ(V2) ー> 0
./video-viewer csi://0
USBカメラ -> 1(V2カメラを使わない場合は1ではなく0にします)
./video-viewer /dev/video1
編集
|
1 |
sudo nano docker/run.sh |
run の代わりに create して名前も付けておきます
sudo docker run -> sudo docker create –name my_cont
rmオプションを削除
|
1 2 3 4 5 |
sudo docker run --runtime nvidia -it --rm --network host -e DISPLAY=$DISPLAY \ -v /tmp/.X11-unix/:/tmp/.X11-unix \ -v /tmp/argus_socket:/tmp/argus_socket \ $V4L2_DEVICES $DATA_VOLUME $USER_VOLUME \ $CONTAINER_IMAGE $USER_COMMAND |
↓
|
1 2 3 4 5 |
sudo docker create --name my_cont --runtime nvidia -it --network host -e DISPLAY=$DISPLAY \ -v /tmp/.X11-unix/:/tmp/.X11-unix \ -v /tmp/argus_socket:/tmp/argus_socket \ $V4L2_DEVICES $DATA_VOLUME $USER_VOLUME \ $CONTAINER_IMAGE $USER_COMMAND |
で、コンテナを作成して起動
|
1 2 |
docker/run.sh sudo docker start -i my_cont |
video-viewer だけ試してみる(メモ)
Docker Container をコマンドで作成
カメラー>/dev/video0
|
1 2 3 4 5 |
sudo docker create --name my_inference --gpus all -it --device /dev/video0:/dev/video0:mwr --network host -e DISPLAY=$DISPLAY \ -v /tmp/.X11-unix/:/tmp/.X11-unix \ -v /tmp/argus_socket:/tmp/argus_socket \ -v /etc/enctune.conf:/etc/enctune.conf \ dustynv/jetson-inference:r32.5.0 |
video viewer をPythonで実行
build/aarch64/bin/video-viewer.py のシンプル化
|
1 2 3 4 5 6 7 8 |
import jetson.utils input = jetson.utils.videoSource("/dev/video0") output = jetson.utils.videoOutput("") while output.IsStreaming(): image = input.Capture() output.Render(image) |
Leave a Reply