通常、画像生成AIで作成された画像で気に入ったものは「イメージデータ」として保存します。
Stable Diffusion ではプロンプトとseed値を使えば生成過程自体を再現できます。
tweak images via repeated Stable Diffusion seeds
seedは画像を微調整するのに使うそうですが、気に入った画像を後日再現するのに重宝します。
やってみましょう。
Colab にアクセス
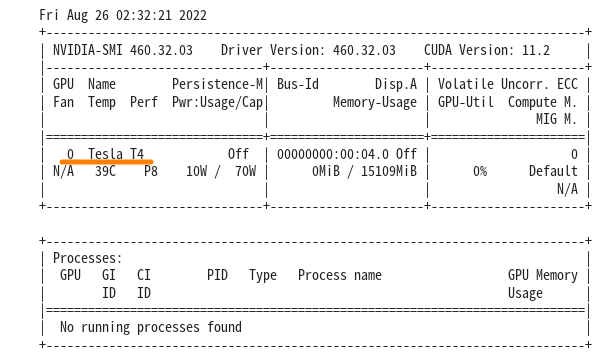
まずは、どんなGPU が使われているのか確認しましょう。
|
1 |
!nvidia-smi |
diffusersとライブラリをインストール
|
1 2 3 |
!pip install git+https://github.com/huggingface/diffusers.git !pip install transformers scipy ftfy !pip install "ipywidgets>=7,<8" |
アクセストークンでHugging Face にログイン
アカウント作成やアクセストークン取得に関してはこちらを参照
|
1 2 3 4 5 |
from google.colab import output output.enable_custom_widget_manager() from huggingface_hub import notebook_login notebook_login() |
無事ログインするとこんな感じ。

GPU メモリを節約するために、half-float 精度を使用します。 完全な精度で推論を実行したい場合は、 revision="fp16" と torch_dtype=torch.float16 を削除します。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import torch from diffusers import StableDiffusionPipeline device = "cuda" model_id = "CompVis/stable-diffusion-v1-4" pipe = StableDiffusionPipeline.from_pretrained( model_id, revision="fp16", torch_dtype=torch.float16, use_auth_token=True, ).to(device) |
最初にいくつかの画像を生成して、どの画像が最も気に入ったかを確認します。 結果をグリッドに表示します。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
from PIL import Image def image_grid(imgs, rows, cols): assert len(imgs) == rows*cols w, h = imgs[0].size grid = Image.new('RGB', size=(cols*w, rows*h)) grid_w, grid_h = grid.size for i, img in enumerate(imgs): grid.paste(img, box=(i%cols*w, i//cols*h)) return grid |
この例では、一度に 4 つの画像を生成します。 GPU の RAM の量に応じて、自由に更新してください。 また、目的の出力解像度を「512 × 512」に設定します。
|
1 2 3 4 |
num_images = 4 width = 512 height = 512 |
Latents Generation
シードを再利用するには、潜在変数を自分で生成する必要があります。 そうしないと、パイプラインが内部でそれを行い、それらを複製する方法がありません。
Latents は、拡散プロセス中に実際の画像に変換される初期ランダム ガウス ノイズです。
それらを生成するには、潜在変数ごとに異なる乱数シードを使用し、後で再利用できるように保存します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
generator = torch.Generator(device=device) latents = None seeds = [] for _ in range(num_images): # Get a new random seed, store it and use it as the generator state seed = generator.seed() seeds.append(seed) generator = generator.manual_seed(seed) image_latents = torch.randn( (1, pipe.unet.in_channels, height // 8, width // 8), generator = generator, device = device ) latents = image_latents if latents is None else torch.cat((latents, image_latents)) # latents should have shape (4, 4, 64, 64) in this case latents.shape |
これで、画像を生成する準備が整いました。 使用したいLatentsをパイプラインに送信します。 そうしないと、パイプラインが新しいセットを生成します。
|
1 2 3 4 5 6 7 8 |
prompt = "Labrador in the style of Vermeer" with torch.autocast("cuda"): images = pipe( [prompt] * num_images, guidance_scale=7.5, latents = latents, )["sample"] |
生成された画像をgridに表示
|
1 |
image_grid(images, 2, 2) |
サンプルでは以下のような画像が生成されていました。

で、お気に入りの画像として右上の画像のseed値を取得してみます。
|
1 2 |
seed = seeds[1] # Second one seed |
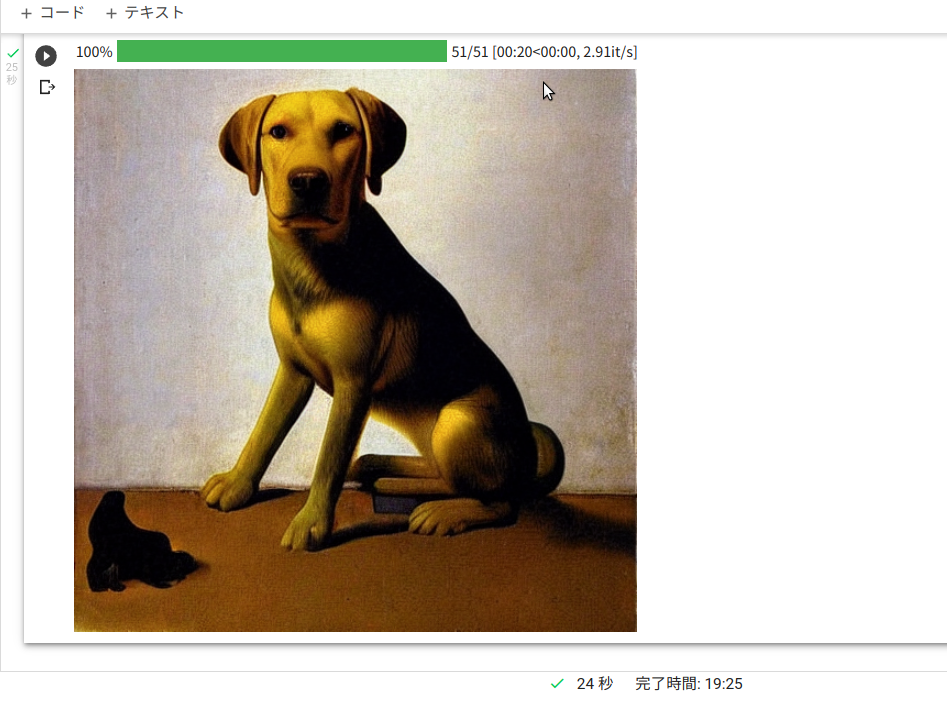
サンプル画像のseed値は以下のものだったそうです。
6363507785059417
このseed値を控えておいて、この値で画像を見てみます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
generator.manual_seed(seed) latents = torch.randn( (1, pipe.unet.in_channels, height // 8, width // 8), generator = generator, device = device ) with torch.autocast("cuda"): image = pipe( [prompt] * 1, guidance_scale=7.5, latents = latents, )["sample"] image[0] |

新しいセッションでColab を使って画像を再現してみましょう。
Colab にアクセス
ノートブックを新規作成した場合は、GPU をアサインしておきましょう。
色々インストールしてHugging Face にログインして、パイプラインを作ってgridを定義するまでは、同じです。
|
1 |
!nvidia-smi |
|
1 2 3 4 5 6 7 8 9 10 |
!pip install git+https://github.com/huggingface/diffusers.git !pip install transformers scipy ftfy !pip install "ipywidgets>=7,<8" from google.colab import output output.enable_custom_widget_manager() from huggingface_hub import notebook_login notebook_login() |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
import torch from diffusers import StableDiffusionPipeline device = "cuda" model_id = "CompVis/stable-diffusion-v1-4" pipe = StableDiffusionPipeline.from_pretrained( model_id, revision="fp16", torch_dtype=torch.float16, use_auth_token=True, ).to(device) from PIL import Image def image_grid(imgs, rows, cols): assert len(imgs) == rows*cols w, h = imgs[0].size grid = Image.new('RGB', size=(cols*w, rows*h)) grid_w, grid_h = grid.size for i, img in enumerate(imgs): grid.paste(img, box=(i%cols*w, i//cols*h)) return grid |
generatorとlatentsを設定
|
1 2 3 |
generator = torch.Generator(device=device) latents = None |
変数を設定、seed値は控えておいたお気に入りの画像ものを使い、プロンプトも同じです。
|
1 2 3 4 5 6 |
seed = 6363507785059417 width = 512 height = 512 prompt = "Labrador in the style of Vermeer" |
画像生成
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
generator.manual_seed(seed) latents = torch.randn( (1, pipe.unet.in_channels, height // 8, width // 8), generator = generator, device = device ) with torch.autocast("cuda"): image = pipe( [prompt] * 1, guidance_scale=7.5, latents = latents, )["sample"] image[0] |
以下の画像が再現されて表示されます。
Leave a Reply