
マイコンで機械学習と推論をやってみる、いわゆるTinyMLのレッスンです。
学習にGoogle Colab を使い、推論実行にRaspberry Pi Pico を使用します。
学習対象は「音」で、目的は「分類」、結果の確認には「LEDの輝度」を使います。
元ネタ End-to-end tinyML audio classification with the Raspberry Pi RP2040
Raspberry Pi RP2040 とはここでは具体的にはPico (RP2040 ボード)のことです。
Pico や PDM Microphone へのリンクは入手し易いように国内のサイトに変更しています。

序章
機械学習により、開発者やエンジニアはアプリケーションの新しい機能を利用できるようになります。 コンピューターが実行する命令やルールを明示的に定義する代わりに、アプリケーションで必要な分類タスクのために大量のデータを収集し、データ内のパターンから学習するように ML モデルをトレーニングできます。
トレーニングは通常、1 つ以上の GPU を搭載したコンピューター上のクラウドで行われます。 モデルがトレーニングされると、そのサイズに応じて、推論のためにさまざまなデバイスにデプロイできます。 これらのデバイスは、ギガバイトのメモリを備えたクラウド上の大型コンピュータから、通常わずか数キロバイトのメモリを備えた小型のマイクロコントローラ (MCU) まで多岐にわたります。
マイクロコントローラーは、電子レンジ、電動歯ブラシ、スマート ドア ロックなど、日常的に使用するデバイスに組み込まれている、低電力で自己完結型のコスト効率の高いコンピューター システムです。 マイクロコントローラーベースのシステムは通常、1 つまたは複数のセンサー (ボタン、マイク、モーションセンサーなど) を介して周囲の環境と対話し、1 つまたは複数のアクチュエーター (LED、モーター、スピーカーなど) を使用してアクションを実行します。
マイクロコントローラーにはプライバシー上の利点もあり、データをクラウドに送信することなく、デバイス上でローカルに推論を実行できます。 これは、バッテリーで動作するデバイスにとっても電力面での利点があります。
この記事では、Arm Cortex-M ベースのマイクロコントローラーをローカルのオンデバイス ML に使用して、周囲の環境からオーディオ イベントを検出する方法を示します。 これはチュートリアル形式の記事で、火災警報音を検出するために TensorFlow ベースの音声分類モデルをトレーニングする方法を説明します。
Arm CMSIS-NN アクセラレーション カーネルを備えたマイクロコントローラー用 TensorFlow Lite を使用して、ローカルのオンデバイス ML 推論のために ML モデルを Arm Cortex-M0+ ベースのマイクロコントローラー ボードにデプロイする方法を説明します。 Arm Cortex-Mプロセッサ向けに最適化されたデジタル信号処理(DSP)機能実装を提供するArmのCMSIS-DSPライブラリも、推論前にリアルタイムオーディオデータから特徴を抽出するために使用されます。
このガイドは火災警報音の検出に焦点を当てていますが、他の音分類タスクにも応用できます。 ユースケースに合わせて、特徴抽出段階を調整したり、ML モデル アーキテクチャを調整したりする必要がある場合もあります。
このチュートリアルのインタラクティブ バージョンは Google Colab で入手でき、このガイドのすべての技術資産は GitHub で見つけることができます。
What you need to to get started (始めるために必要なもの)
開発環境
Hardware
2021 年初めにリリースされた Raspberry Pi の RP2040 MCU チップをベースにした次の開発ボードが必要です。
Raspberry Pi Pico and PDM microphone board
このオプションは、はんだ付け方法を知っている (または学びたい) 場合に最適です。 はんだごてと、ブレッドボードに電子部品を配線する方法の知識が必要です。 あなたは必要になるでしょう:
●Raspberry Pi Pico
●Adafruit PDM MEMS マイク ブレークアウト
●ハーフサイズまたはフルサイズのブレッドボード
●ジャンパー線
●ボードをコンピューターに接続するための USB-B マイクロ ケーブル
●はんだごて
はんだごては、PDM マイク にピンヘッダーをつけるのに必要ですが、面倒だ(やりたくない)という方はスルーホールテストワイヤを使えばいいですし、この場合ブレッドボードは使わず直接ピンどうしをワイアリングします。

上記のオプションを使用すると、デジタル マイクからリアルタイム 16 kHz オーディオを収集し、125 MHz で動作する開発ボードの Arm Cortex-M0+ プロセッサでオーディオ信号を処理できます。 Arm Cortex-M0+ 上で実行されるアプリケーションには、オーディオ信号から特徴を抽出するためのデジタル信号処理 (DSP) ステージがあります。 抽出された特徴はニューラル ネットワークに入力され、分類タスクを実行して、ボードの環境内に火災警報音が存在するかどうかを判断します。
Dataset(データセット)
まず、ESC-50: 環境音分類用データセットを使用して、TensorFlow で音分類器 (多くのイベント用) をトレーニングします。 この広範なデータセットでトレーニングした後、転移学習を使用して、特定の音声分類タスクに合わせてデータセットを微調整します。
このモデルは、50 種類のサウンドを含む ESC-50 データセットでトレーニングされます。 各サウンド カテゴリには、それぞれ 5 秒の長さの 40 個のオーディオ ファイルがあります。 各オーディオ ファイルは 1 秒のサウンドバイトに分割され、純粋な沈黙を含むサウンドバイトは破棄されます。
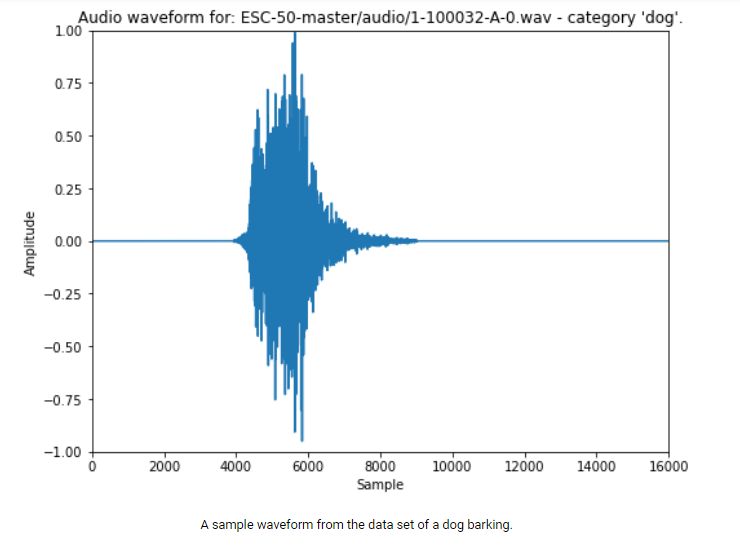
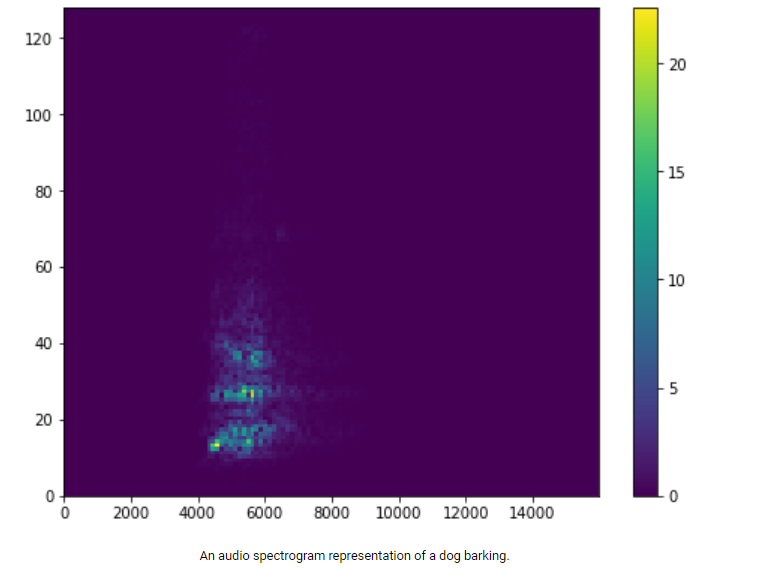
Spectrograms (音紋、声紋)
時系列データを TensorFlow モデルに直接渡すのではなく、オーディオ データをオーディオ スペクトログラム表現に変換します。 これにより、時間の経過に伴うオーディオ信号の周波数成分の 2D 表現が作成されます。
使用する入力オーディオ信号のサンプリング レートは 16kHz です。これは、1 秒のオーディオに 16,000 個のサンプルが含まれることを意味します。 TensorFlow の tf.signal.stft(…) 関数を使用すると、1 秒のオーディオ信号を 2D テンソル表現に変換できます。 フレーム長 256 とフレーム ステップ 128 を選択するため、この特徴抽出ステージの出力は (124, 129) の形状を持つテンソルになります。
The ML model (機械学習 モデル)
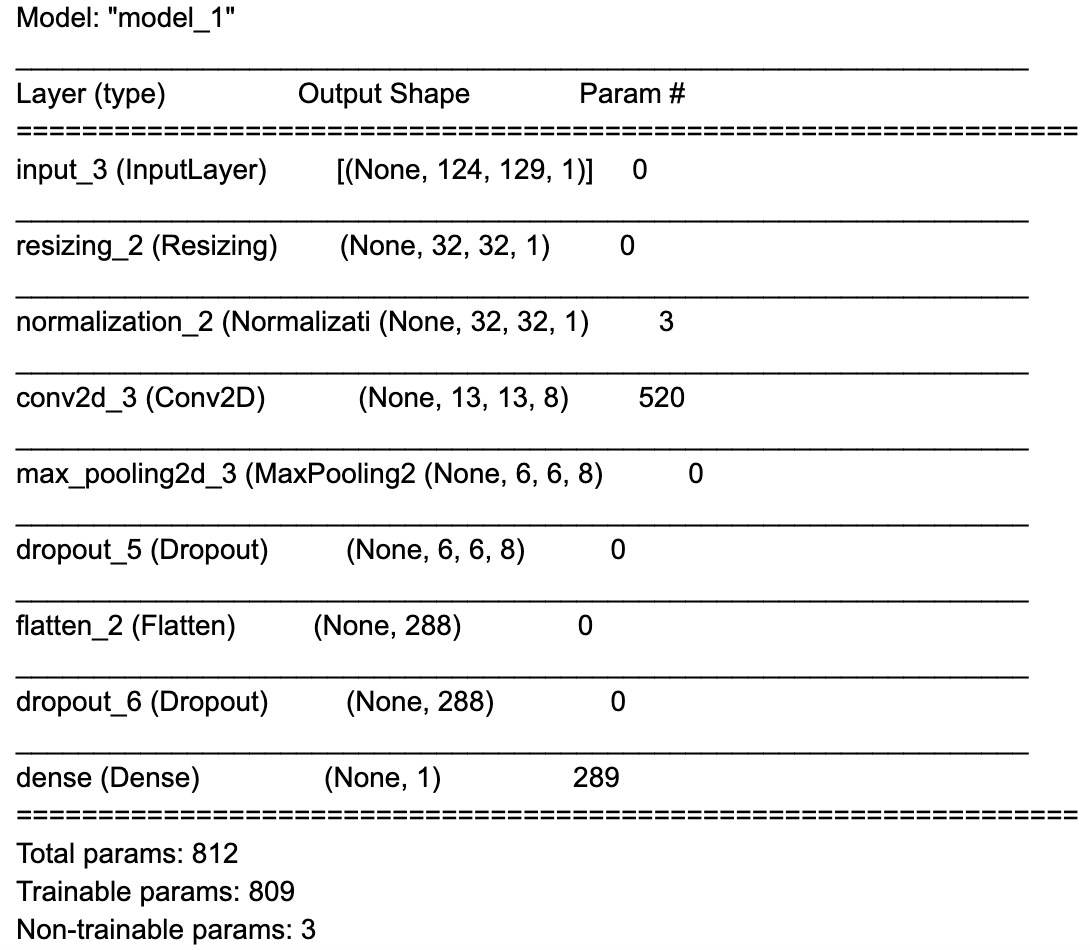
オーディオ信号から特徴を抽出したので、TensorFlow の Keras API を使用してモデルを作成できます。 完全なコードは上にリンクされています。 モデルは 8 つのレイヤーで構成されます。
1. 入力レイヤー
2. 入力テンソルのサイズを 124 x 129 x 1 から 32 x 32 x 1 に変更する前処理レイヤー
3. 入力値を -1 から 1 までの間でスケーリングする正規化レイヤー
4. 8 つのフィルター、8 x 8 のカーネル サイズ、2×2 のストライド、および ReLU アクティベーション関数を備えた 2D 畳み込みレイヤー
5. サイズが 2 x 2 の 2D Maxプーリングレイヤー
6. 2D データを 1D に平坦化する平坦化レイヤー
7. ドロップアウトレイヤー(トレーニング中のオーバーフィッティング(過学習)を軽減します)
8. 50 個の出力とsoftmax アクティベーション関数を備えた高密度レイヤー(サウンド カテゴリ (0 ~ 1) の尤度を出力します)
モデルの概要は以下にあります。

このモデルには約 15,000 個のパラメーターしかないことに注意してください (この値は非常に小さいです!)。
Fine tuning (微調整)
次に、転移学習を使用し、モデルの分類ヘッド (最後の密層) を変更して、火災警報音のバイナリ分類モデルをトレーニングします。 freesound.org と BigSoundBank.com から 10 個の火災警報クリップを集めました。 SpeechCommands データセットのバックグラウンド ノイズ クリップは、火災警報以外の音に使用されます。 このデータセットは小さいので、始めるには十分です。 データ拡張技術は、収集したトレーニング データを補足するために使用されます。
現実世界のアプリケーションの場合、より大規模なデータセットを収集することが重要です (ベスト プラクティスについて詳しくは、TensorFlow の Responsible AI Web サイトをご覧ください)。
Data Augmentation (データ拡張)
データ拡張は、データセットのサイズを増やすために使用される一連の手法です。 これは、データセットのサンプルをわずかに変更するか、合成データを作成することによって行われます。 この状況ではオーディオを使用しており、さまざまなサンプルを拡張するいくつかの関数を作成します。 次の 3 つのテクニックを使用します。
1.オーディオ サンプルにホワイト ノイズを追加します
2.オーディオにランダムな無音部分を追加します
3.2 つのオーディオ サンプルをミックスします
データ拡張は、データセットのサイズを増やすだけでなく、異なる (完璧ではない) データ サンプルでモデルをトレーニングすることにより、過学習を軽減するのにも役立ちます。 たとえば、マイクロコントローラーでは、完璧な高品質のオーディオが得られる可能性は低いため、ホワイト ノイズを追加するなどのテクニックは、マイクにノイズが頻繁に含まれる可能性がある状況でモデルが機能するのに役立ちます。
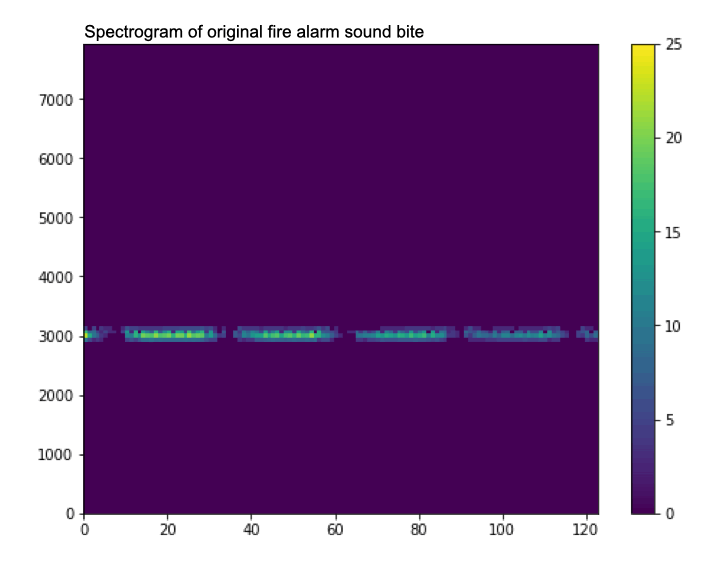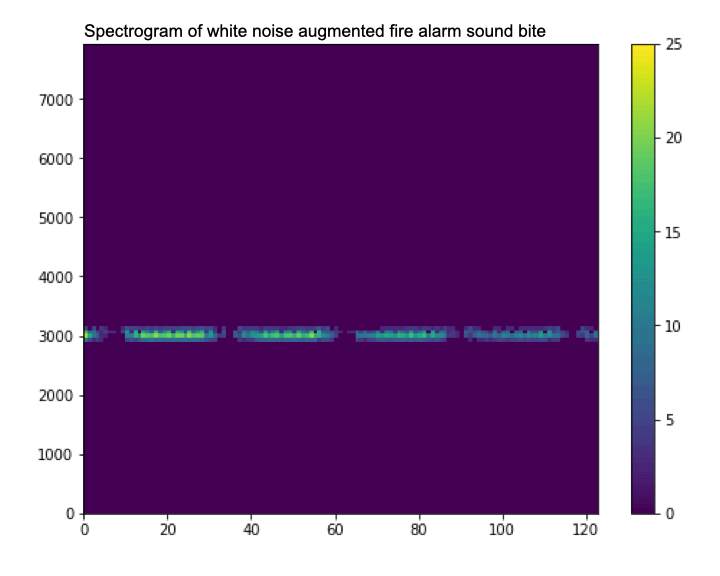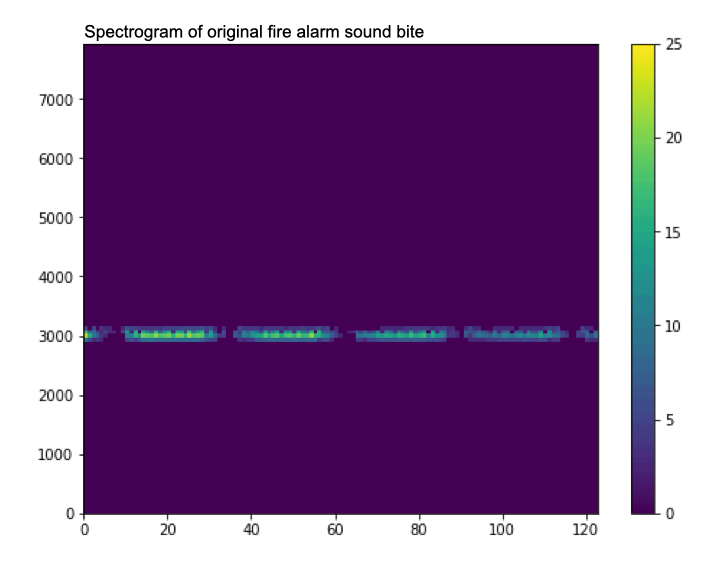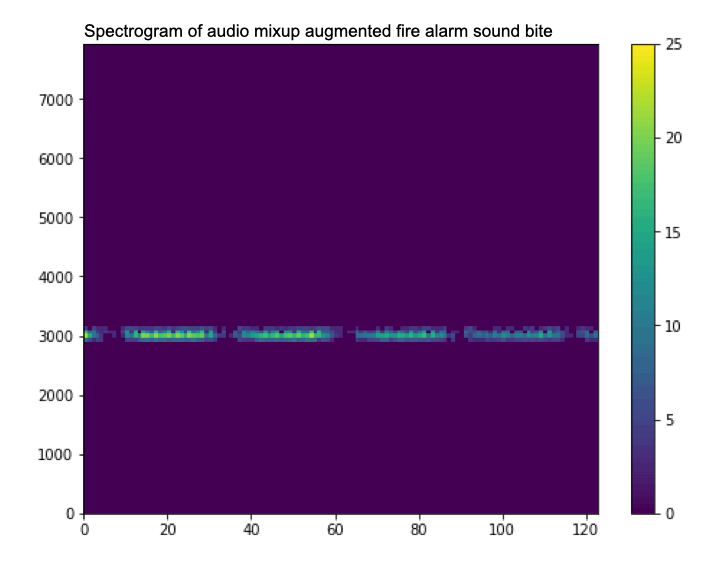
A gif showing how data augmentation slightly changes the spectrogram by adding noise (watch it closely, it can be a bit hard to see).
Feature Extraction(特徴抽出)
TensorFlow Lite for Microcontroller (TFLu) は TensorFlow 操作のサブセットを提供するため、MCU でベースライン モデルの特徴抽出に使用した tf.signal.sft(…) API を使用できません。 ただし、Arm の CMSIS-DSP ライブラリを利用して MCU 上でスペクトログラムを生成できます。 CMSIS-DSP には、ML モデルを展開する Arm Cortex-M0+ を含む Arm Cortex-M プロセッサ向けに最適化された浮動小数点と固定小数点の両方の DSP 操作のサポートが含まれています。 Arm Cortex-M0+ には浮動小数点ユニット (FPU) が含まれていないため、ボード上の 16 ビット固定小数点 DSP ベースの機能抽出パイプラインを活用することをお勧めします。
ノートブックで CMSIS-DSP の Python ラッパーを活用し、16 ビット固定小数点演算を使用してトレーニング パイプラインで同じ操作を実行できます。 高レベルでは、次の CMSIS-DSP ベースの操作を使用して TensorFlow SFT API を複製できます。
1.ハニング ウィンドウの式と CMSIS-DSP の arm_cos_f32 API を使用して、長さ 256 のハニング ウィンドウを手動で作成します。

2.CMSIS-DSP arm_rfft_instance_q15 インスタンスを作成し、CMSIS-DSP の arm_rfft_init_q15 API を使用して初期化します。
3.オーディオ データを一度に 256 サンプル、ストライド 128 でループします (これは、TF sft API に渡したパラメーターと一致します)
a.CMSIS-DSP の arm_mult_q15 API を使用して、256 サンプルをハニング ウィンドウで乗算します
b.CMSIS-DSP の arm_rfft_q15 API を使用した、前のステップの出力の FFT の計算
c.CMSIS-DSP の arm_cmplx_mag_q15 API を使用して、前のステップの大きさを計算する
4.各オーディオ サウンドバイトの FFT の大きさは、スペクトログラムの 1 列を表します
5.ベースラインモデルでは、これまで使用していた16ビットの量子化値ではなく、浮動小数点入力を想定しているため、CMSIS-DSP arm_q15_to_float APIを使用して、スペクトログラムデータを16ビットの固定小数点値からトレーニング用の浮動小数点値に変換することができます
この完全な Python コードは少し長いですが、Google Colab ノートブックの「Transfer Learning -> Load dataset」セクションにあります。

Waveform and audio spectrogram of a smoke alarm sound.
CMSIS-DSP で固定小数点演算を使用してオーディオ スペクトログラムを作成する方法の詳細については、データ サイエンス向けの「データ サイエンティスト向けの固定小数点 DSP」ガイドを参照してください。
Loading the baseline model and changing the classification head
(ベースラインモデルのロードと分類ヘッドの変更)
以前に ESC-50 データセットでトレーニングしたモデルは、50 種類の音の存在を予測し、その結果、モデルの最後の高密度層は 50 個の出力を持ちました。 作成したい新しいモデルはバイナリ分類器であり、単一の出力値を持つ必要があります。
ベースライン モデルをロードし、ニーズに合わせて最後の高密度レイヤーを交換します。
|
1 2 3 4 5 6 |
# We need a new head with one neuron. model_body = tf.keras.Model(inputs=model.input, outputs=model.layers[-2].output) classifier_head = tf.keras.layers.Dense(1, activation="sigmoid")(model_body.output) fine_tune_model = tf.keras.Model(model_body.input, classifier_head) |
これにより、次の model.summary() が生成されます。
Transfer Learning (転移学習)
転移学習は、タスク用に開発されたモデルを再トレーニングして、新しい同様のタスクを完了するプロセスです。 このアイデアは、モデルが移転可能な「スキル」を学習し、重みとバイアスを出発点として他のモデルで使用できるというものです。
私たち人間も転移学習を使用します。 歩くことを学ぶために培ったスキルは、後で走ることを学ぶためにも使用できます。
ニューラル ネットワークでは、モデルの最初の数層が、形状、エッジ、色の検索などの「特徴抽出」の実行を開始します。 レイヤーは後で分類子として使用されます。 抽出された特徴を取得して分類します。
このため、最初のいくつかのレイヤーは、同様のタスクに適用できる非常に一般的な特徴抽出テクニックを学習していると想定できるため、これらすべてのレイヤーをフリーズ(凍結)して、将来の新しいタスクで使用することができます。 分類子層は、新しいタスクに基づいてトレーニングする必要があります。
これを行うには、プロセスを 2 つのステップに分けます。
1.モデルの「バックボーン」を凍結し、かなり高い学習率でheadをトレーニングします。 学習率を徐々に下げていきます。
2.「バックボーン」の凍結を解除し、低い学習率でモデルを微調整します。
TensorFlow でレイヤーを凍結するには、layer.trainable=False を設定します。 すべてのレイヤーをループしてこれを実行してみましょう。
|
1 2 |
for layer in fine_tune_model.layers: layer.trainable = False |
そして最後のレイヤー (head) を解凍します。
|
1 |
fine_tune_model.layers[-1].trainable = True |
これで、バイナリ クロスエントロピー損失関数を使用してモデルをトレーニングできるようになりました。 早期停止のための Keras コールバック (過学習を避けるため) と動的学習率スケジューラも使用されます。
凍結したレイヤーでトレーニングした後、それらを解凍できます。
|
1 2 |
for layer in fine_tune_model.layers: layer.trainable = True |
そして、最大 10 エポックまで再度トレーニングします。 この完全なコードは、Colab ノートブックの「転移学習 -> モデルのトレーニング」セクションにあります。
Recording your own training data (自分のトレーニングデータを記録する)
火災警報音の有無を分類できる ML モデルが完成しました。 ただし、このモデルは公開されている音声録音でトレーニングされており、推論に使用するハードウェア マイクの音声特性と一致しない可能性があります。
Raspberry Pi RP2040 MCU には、カスタム USB デバイスのように動作できるネイティブ USB 機能があります。 アプリケーションをボードにフラッシュして、PC に対して USB マイクのように機能させることができます。 次に、Google Chrome などの最新の Web ブラウザ上の Web Audio API を使用して Google Colab の機能を拡張し、ライブ データ サンプルを収集できます (すべて Google Colab 内から!)。
Hardware Setup
Raspberry Pi Pico + PDM Mic
組み立て手順については、「Raspberry Pi Pico で USB マイクを作成する」ガイドの「ハードウェア セットアップ」セクションの手順に従ってください。


Top: Fritzing wiring diagram Bottom: Assembled breadboard
Setting up the firmware applications toolchains (ファームウェア アプリケーション ツールチェーンのセットアップ)
パソコンでRaspberry Pi PicoのSDKをセットアップするよりも、Colabの内蔵Linuxシェルコマンド機能を活用して、CMakeとGNU Arm Embedded Toolchainを使ってPico SDKの開発環境をセットアップする方が簡単です。CMakeとGNU Arm Embedded Toolchainを使ってPico SDKの開発環境をセットアップするために、Colabの内蔵Linuxシェルコマンド機能を活用することができます。
pico-sdkもgitを使ってColabインスタンスにダウンロードする必要があります:
|
1 2 3 4 5 6 |
%%shell git clone https://github.com/raspberrypi/pico-sdk.git cd pico-sdk git submodule init git submodule update |
Compiling and flashing the USB microphone application (USB マイク アプリケーションのコンパイルとフラッシュ)
これで、Pico のマイク ライブラリの USB マイクの例を使用できるようになりました。 サンプル アプリケーションは、cmake と make を使用してコンパイルできます。 次に、ボードを「ブート ROM モード」にして、サンプル アプリケーションを USB 経由でボードにフラッシュし、アプリケーションをボードにアップロードできるようにします。
Raspberry Pi Pico
●USB マイクロ ケーブルを PC に差し込みますが、Pico 側にはまだ差し込まないでください。
●白い BOOTSEL ボタンを押しながら、USB マイクロ ケーブルは ここでPico に接続します。

Google Chrome などの WebUSB API 対応ブラウザを使用している場合は、Google Collab 内からボードに画像を直接フラッシュできます。
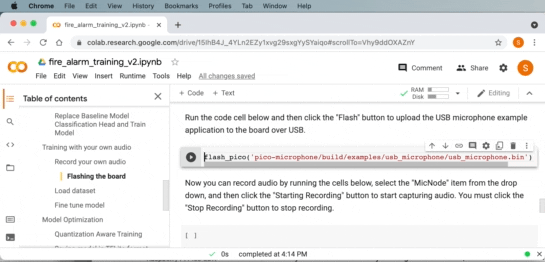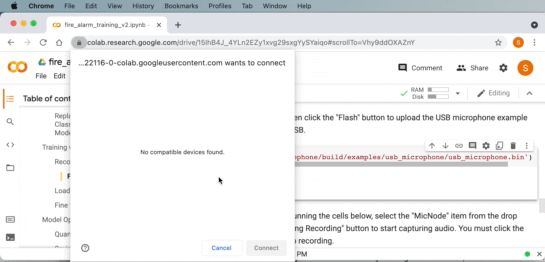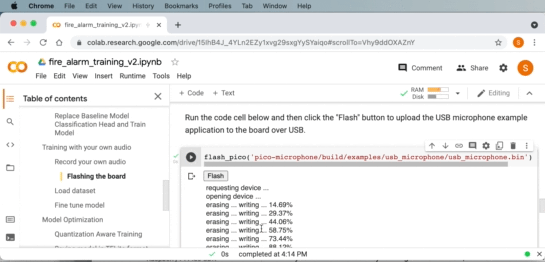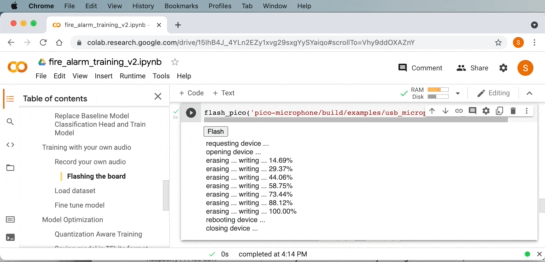
Downloading USB microphone application to the board from within Google Colab and WebUSB.
それ以外の場合は、.uf2 ファイルをコンピュータに手動でダウンロードし、それを RP2040 ボードの USB ディスク(フラッシュメモリー)にドラッグします。
Collecting training data (トレーニングデータの収集)
USB マイク アプリケーションをボードにフラッシュしたので、PC 上で USB オーディオ入力として表示されます。
Google Colab を使用して火災警報音を録音できるようになりました。ドロップダウンで音声入力ソースとして「MicNode 」を選択します。 次に、煙警報器のテスト ボタンを押しながら、Google Colab の録音ボタンをクリックして 1 秒の音声クリップを録音します。 このプロセスを数回繰り返します。
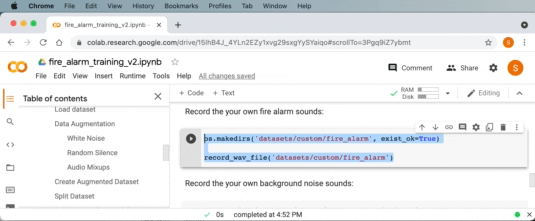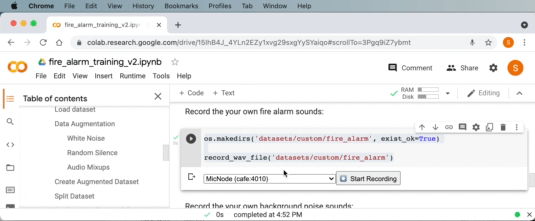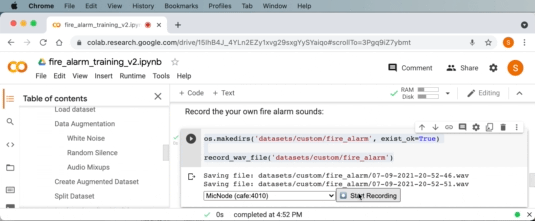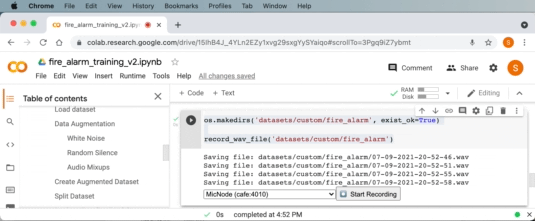
同様に、Google Colab の次のコード セルでバックグラウンド オーディオ サンプルを収集するために同じことを行うこともできます。 これを数回繰り返して、火災警報以外の音(沈黙、自分の話し声、その他周囲の通常の音)を鳴らします。
Final model training (最終モデルのトレーニング)
これで、推論中に使用される追加のサンプルをマイクで収集できました。 新しいデータを使用してモデルを再度調整できます。
Converting the Model to run on the MCU (MCU 上で実行できるようにモデルを変換する)
デバイス上の推論に使用できるように、使用した Keras モデルを TensorFlow Lite 形式に変換する必要があります。
Quantization (量子化)
Arm Cortex-M0+ プロセッサ上で実行するようにモデルを最適化するには、モデル量子化と呼ばれるプロセスを使用します。 モデルの量子化では、モデルの重みとバイアスを 32 ビット浮動小数点値から 8 ビット値に変換します。 RP2040 の Pico SDK 用の TFLu ポートである pico-tflmicro ライブラリには、Arm Cortex-M プロセッサ上の量子化された 8 ビット重みに対する最適化されたカーネル操作をサポートする Arm の CMSIS-NN ライブラリが含まれています。
TensorFlow の量子化対応トレーニング (QAT) 機能を使用すると、浮動小数点モデルを量子化モデルに簡単に変換できます。
Converting the model to TF Lite format (モデルを TF Lite 形式に変換する)
ここで、tf.lite.TFLiteConverter.from_keras_model(…) API を使用して、量子化された Keras モデルを TF Lite 形式に変換し、それを .tflite ファイルとしてディスクに保存します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
converter = tf.lite.TFLiteConverter.from_keras_model(quant_aware_model) converter.optimizations = [tf.lite.Optimize.DEFAULT] train_ds = train_ds.unbatch() def representative_data_gen(): for input_value, output_value in train_ds.batch(1).take(100): # Model has only one input so each data point has one element. yield [input_value] converter.representative_dataset = representative_data_gen # Ensure that if any ops can't be quantized, the converter throws an error converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] # Set the input and output tensors to uint8 (APIs added in r2.3) converter.inference_input_type = tf.int8 converter.inference_output_type = tf.int8 tflite_model_quant = converter.convert() with open("tflite_model.tflite", "wb") as f: f.write(tflite_model_quant) |
TensorFlow は tf.lite を使用した TF Lite モデルのロードもサポートしているため、量子化モデルの機能を検証し、その精度を Google Colab 内の通常の非量子化モデルと比較することもできます。
導入先のボード上の RP2040 MCU にはファイル システムが組み込まれていないため、ボード上で .tflite ファイルを直接使用することはできません。 ただし、Linux の「xxd」コマンドを使用して .tflite ファイルを .h ファイルに変換し、次のステップで推論アプリケーションでコンパイルすることができます。
|
1 2 3 4 5 |
%%shell echo "alignas(8) const unsigned char tflite_model[] = {" > tflite_model.h cat tflite_model.tflite | xxd -i >> tflite_model.h echo "};" |
Deploy the model to the device (モデルをデバイスにデプロイする)
これで、デバイスにデプロイする準備ができたモデルが完成しました。 モデル用に生成した .h ファイルを使用してコンパイルできる推論用のアプリケーション テンプレートを作成しました。
C++ アプリケーションは、CMSIS-DSP、pico-tflmicro、および Pico ライブラリ用のマイク ライブラリとともに、ベースとして pico-sdk を使用します。 一般的な構造は次のとおりです。
1.初期化
a.ボードの内蔵 LED を出力用に設定します。 アプリケーションは LED の明るさをモデルの出力にマッピングします。 ( 0.0 LED オフ、1.0 LED最大輝度で オン)
b.推論用に TF Lite ライブラリと TF Lite モデルをセットアップする
c.CMSIS-DSP ベースの DSP パイプラインをセットアップする
d.リアルタイムオーディオ用のマイクをセットアップして開始する
2.推論ループ
a.マイクからの 128 * 4 = 512 個の新しいオーディオ サンプルを待ちます
b.スペクトログラム配列を 4 列シフトします
c.オーディオ入力バッファを 128 * 4 = 512 サンプル分シフトし、新しいサンプルをコピーします。
d.更新された入力バッファーの 4 つの新しいスペクトログラム列を計算します。
e.スペクトログラム データの推論を実行する
f.推論出力値をオンボード LED の輝度にマッピングし、ステータスを USB ポートに出力します
リアルタイムで実行するには、推論ループの各サイクルにかかる時間が (512 / 16000) = 0.032 秒または 32 ミリ秒未満である必要があります。 私たちがトレーニングして変換したモデルの推論には 24 ミリ秒かかりますが、ループ内の他の操作には最大 8 ミリ秒かかります。
128 は、スペクトログラムのトレーニング パイプラインで使用された 128 のストライドと一致させるために使用されました。 リアルタイムの制約内に収まるように、スペクトログラムで 4 のシフトを使用しました。
Compiling the Firmware (ファームウェアのコンパイル)
これで、CMake を使用してコンパイルに必要なビルド ファイルを生成し、その後 make でコンパイルできるようになります。
「cmake ..」行は、使用しているボードに基づいて変更する必要があります。
Raspberry Pi Pico
● cmake .. -DPICO_BOARD=pico
Flashing the Inference Application to the board (推論アプリケーションをボードにフラッシュする)
新しいアプリケーションをボードにロードするには、ボードを再度「ブート ROM モード」にする必要があります。
Raspberry Pi Pico
●USB マイクロ ケーブルを PC に差し込みますが、Pico 側にはまだ差し込まないでください。
●白い BOOTSEL ボタンを押しながら、USB マイクロ ケーブルはここで Pico に接続します。
Google Chrome などの WebUSB API 対応ブラウザを使用している場合は、Google Colab 内からボードに画像を直接フラッシュできます。 それ以外の場合は、.uf2 ファイルをコンピュータに手動でダウンロードし、それを RP2040 ボードの USB ディスク(フラッシュメモリー)にドラッグします。
Monitoring the Inference on the board (ボード上の推論をモニターする)
推論アプリケーションがボード上で実行されるようになったので、次の 2 つの方法でその動作を観察できます。
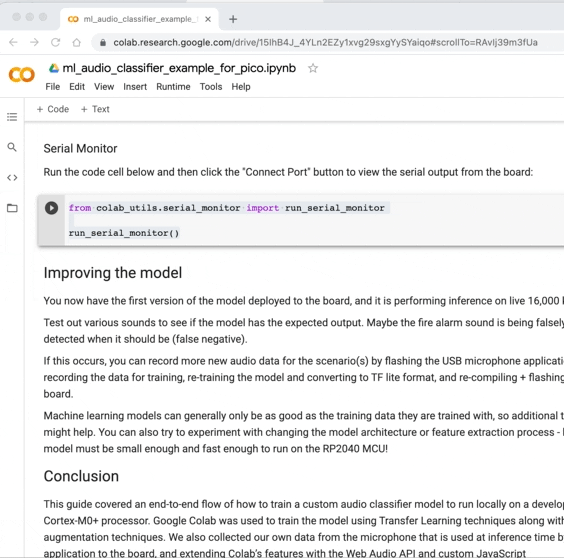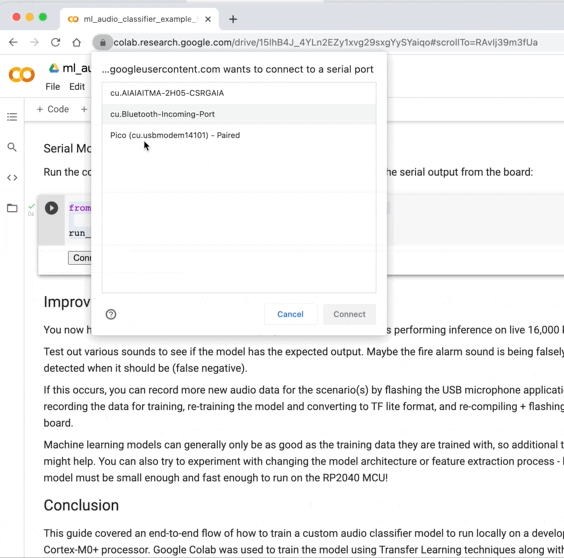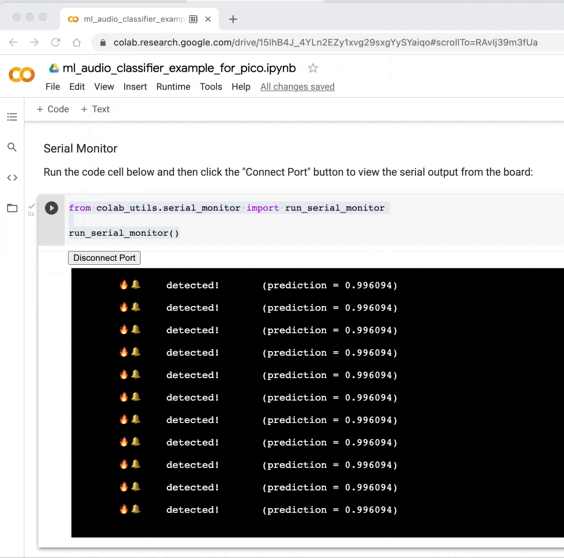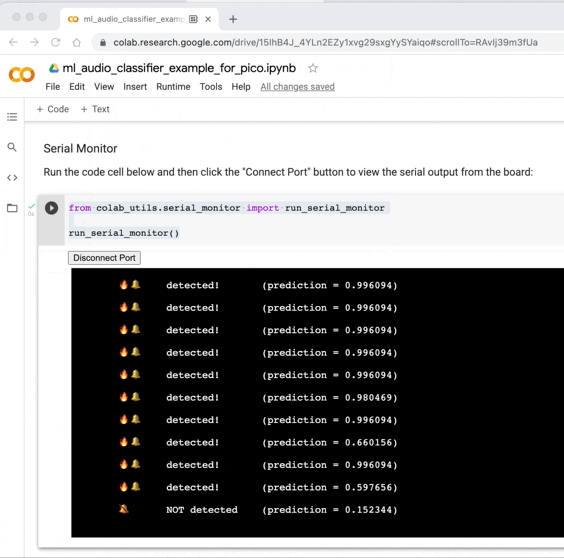
基板上の LED の明るさを視覚的に観察します。 火災警報音が鳴っていないときはオフまたは薄暗いままにし、火災警報音が鳴っているときはオンになる必要があります。
ボードの USB シリアル ポートに接続して、推論アプリケーションからの出力を表示します。 Google Chrome などの Web シリアル API 対応ブラウザを使用している場合は、Google Colab から直接実行できます。
Improving the model (モデルの改善)
これで、モデルの最初のバージョンがボードにデプロイされ、ライブ 16,000 kHz オーディオ データに対して推論が実行されています。
さまざまなサウンドをテストして、モデルに期待どおりの出力があるかどうかを確認します。 おそらく、火災警報音が誤って検出されている (偽陽性) か、本来あるべきときに検出されない (偽陰性) 可能性があります。
この問題が発生した場合は、USB マイク アプリケーション ファームウェアをボードにフラッシュし、トレーニング用のデータを記録し、モデルを再トレーニングして TF lite 形式に変換し、再コンパイルすることで、シナリオ用にさらに新しいオーディオ データを記録できます。 + 推論アプリケーションをボードにフラッシュします。
教師あり機械学習モデルは、通常、トレーニングに使用されたトレーニング データと同程度の性能しか発揮できないため、これらのシナリオ用の追加のトレーニング データが役立つ場合があります。 モデル アーキテクチャや特徴抽出プロセスを変更して実験してみることもできますが、モデルは RP2040 MCU で実行できるほど小さく、十分に高速である必要があることに注意してください。
Conclusion (結論)
この記事では、Arm Cortex-M0+プロセッサを使用する開発ボード上でローカルに動作するカスタムオーディオ分類器モデルをトレーニングする方法について、エンドツーエンドのフローを取り上げました。TensorFlowは、少ないデータセットとデータ増強技術とともに、転移学習技術を使用してモデルを訓練するために使用されました。また、USBマイクアプリケーションをボードにロードし、Web Audio APIとJavaScriptでColabの機能を拡張することで、推論時に使用されるマイクから独自のデータを収集しました。
学習側では、GoogleのColabサービスとChromeブラウザ、オープンソースのTensorFlowライブラリを組み合わせました。推論アプリケーションは、デジタルマイクからオーディオデータを取り込み、特徴抽出の段階でArmのCMSIS-DSPライブラリを使用し、Arm CMSIS-NNアクセラレーションカーネルを備えたマイクロコントローラ用のTensorFlow Liteを使用して、Arm Cortex-M0+プロセッサ上でリアルタイムの16 kHzオーディオ入力を分類する8ビット量子化モデルで推論を実行しました。
Google ChromeのWeb Audio API、Web USB API、およびWeb Serial API機能を使用して、Google Colabの機能を拡張し、開発ボードと対話しました。これにより、ウェブブラウザだけでアプリケーションを実験・開発し、制約のある開発ボードにデプロイしてオンデバイスで推論を行うことができました。
ML処理は開発ボードのRP2040 MCUで行われたため、推論時に音声データがデバイスから離れることはありませんでした。
Leave a Reply