
LLM が応答に使う情報は基本、学習した時点のデータから得られたもののみです。情報を増やすためには再度トレーニングするかファインチューニングする必要がありますが、LangChainやLlamaIndexを使う方法もあります。これは質問などを投げるプロンプトに新しい情報をインデックス化したものを埋め込んでおくやり方です。プロンプトエンジニアリングの一種(機能を盛るとRAGになる…?)。今回はこれをやってみます。
LLM として ELYZA-japanese-Llama-2-7b-fast-instruct-q4_0.gguf を使います。
実行プラットフォームはラズパイ5(8GB)。

ただ、LangChainもllamaIndexもアップデートが速いので、このやり方も一時的なものになります。まあ、やってみてどんなものか感触を得てみましょう。
環境設定
Raspberry Pi OS Desktop (Bookworm) 64-bit のPythonの現バージョンは3.11.2ですが、3.10.xバージョンを使います。
事前に必要なライブラリをインストールしておきます。
|
1 2 3 4 5 6 7 8 9 |
sudo apt-get update sudo apt-get upgrade -y sudo apt install \ build-essential libbz2-dev libdb-dev \ libffi-dev libgdbm-dev liblzma-dev \ libncursesw5-dev libreadline-dev libsqlite3-dev \ libssl-dev tk-dev uuid-dev \ zlib1g-dev |
Python-3.10.11のソースをダウンロードして解凍
|
1 2 3 |
wget https://www.python.org/ftp/python/3.10.11/Python-3.10.11.tgz tar zxvf Python-3.10.11.tgz |
コンパイル&インストール
|
1 2 3 4 |
cd Python-3.10.11 ./configure make sudo make install |
python3 で使えるようにリンクを張り直しておきます。
|
1 2 3 4 |
cd /usr/bin sudo rm python3 sudo ln -s /usr/local/bin/python3.10 python3 cd ~/ |
仮想環境設定(以前の環境も考慮してvenv2という名前にしておきます)
|
1 2 3 |
python3 -m venv venv2 source venv2/bin/activate |
LangChainやLlamaIndex、および他のライブラリをバージョン指定してインストールします。
LlamaIndexはバージョン0.6.24を使うので他もそれに合わせています
これらのバージョンが最適というわけではないですが、一応無難にマッチしてはいます。
まずpipをアップグレードしておきます。
|
1 |
pip install --upgrade pip |
必要なパッケージやライブラリをバージョン指定してインストール
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# accelerateのインストール pip install accelerate==0.19.0 # llama-cpp-pythonのインストール pip install llama-cpp-python==0.1.82 # transformersのインストール pip install sentence-transformers==2.2.2 # LangChainのインストール pip install langchain==0.0.206 # typing-extensionsのバージョン(4.5.0)に合わせてPytorchをバージョンダウン pip install torch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 --extra-index-url https://download.pytorch.org/whl/test/cpu # LlamaIndexのインストール pip install llama-index==0.6.24 # tiktokenのインストール pip install tiktoken # openaiのバージョンダウン pip install openai==0.28.1 |
ELYZAのダウンロード
以前に作成したディレクトリにダウンロードします。
未だ作成されてなければ作成しておきます。
mkdir -p ~/models/gguf
|
1 2 3 |
cd ~/models/gguf wget https://huggingface.co/mmnga/ELYZA-japanese-Llama-2-7b-fast-instruct-gguf/resolve/main/ELYZA-japanese-Llama-2-7b-fast-instruct-q4_0.gguf |
LLM に渡す、新しい情報や追加情報を記述したドキュメントを作成します。
ディレクトリーを作成し、ドキュメントを置いておきます。
ドキュメントは異なる種類が複数あってもいいようです。LLM が事前に学習したことないかもしれない内容の情報を記述しておきます。
ドキュメントはUTF-8でプレーンテキストにしておきます。
|
1 2 |
mkdir ~/docs cd ~/docs |
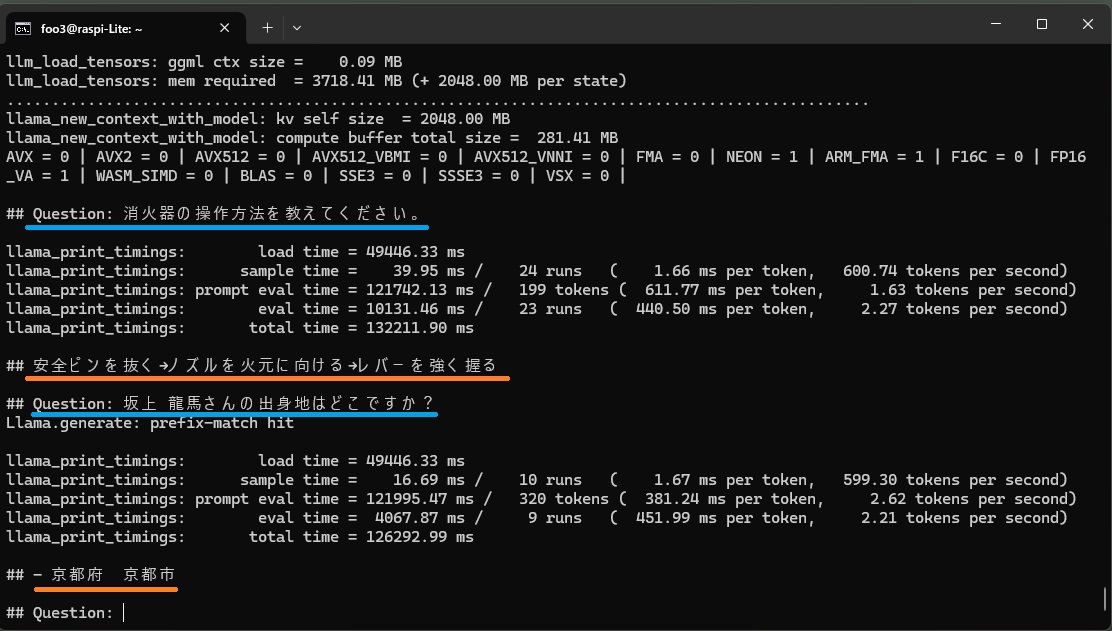
1つ目は消化器のマニュアル。
|
1 |
sudo nano fire_extinguisher.md |
### 消火器操作手順 ###
火災を発見したら、「火事だ!!」と大きな声で周囲に知らせ、近くの消火器を運び、火災現場到着したら消火器を火元へ向けて放射
### 消火器の使い方###
安全ピンを抜く、ノズルを火元に向ける、レバーを強く握る
2つ目は架空の人物の履歴です。
|
1 |
sudo nano personal_history.md |
履歴
坂上 龍馬は、日本の幕末の志士、経営者。
出生地: 京都府 京都市
生年月日: 1835年10月4日
暗殺: 1868年10月4日, 京都
配偶者: なし
埋葬地: 京都府 京都市 京都霊山護國神社
LlamaIndex の埋め込みモデルは Multilingual-E5-largeを使用します。
埋め込みモデルというのは、このモデルを用いることで、言語情報をベクトル化し、効果的に機械学習に利用できるようにするものです。
上記のドキュメントを読み込んだら、これをインデックス化します。
実行用のPythonコードをmain.pyに記述します.
|
1 2 3 |
cd ~/ sudo nano main.py |
以下を記述
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
from llama_index import LLMPredictor, LangchainEmbedding, ServiceContext, SimpleDirectoryReader, QuestionAnswerPrompt from llama_index import GPTVectorStoreIndex from langchain.llms import LlamaCpp from langchain.embeddings.huggingface import HuggingFaceEmbeddings llm = LlamaCpp(model_path=f'./models/gguf/ELYZA-japanese-Llama-2-7b-fast-instruct-q4_0.gguf', temperature=0, n_ctx=4096) llm_predictor = LLMPredictor(llm=llm) embed_model = LangchainEmbedding(HuggingFaceEmbeddings(model_name="intfloat/multilingual-e5-large")) service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor, embed_model=embed_model) # ドキュメントのインデックス化 documents = SimpleDirectoryReader('./docs').load_data() vector_store_index = GPTVectorStoreIndex.from_documents(documents, service_context=service_context) # 質問 temp = """あなたは先生です。 以下の「コンテキスト情報」と「制約条件」を元に「質問」に回答してください。 # コンテキスト情報 --------------------- {context_str} --------------------- # 制約条件 - コンテキスト情報はマークダウン形式で書かれています。 - コンテキスト情報に無い情報は絶対に回答に含めないでください。 # 質問 {query_str} # 回答""" query_engine = vector_store_index.as_query_engine(text_qa_template=QuestionAnswerPrompt(temp)) while True: req_msg = input('\n## Question: ') res_msg = query_engine.query(req_msg) print('\n##', str(res_msg).strip()) |
実行
>python3 main.py
初回は埋め込みモデルのダウンロードやドキュメントのインデックス化に少々時間を要します。
準備ができたら、入力フィールドが出るので、プロンプトを記述。
例によって「日本で一番高い山はどこですか?」をやってみましょう。
こんな感じ。回答が返ってくるのに3分近くかかりました。

では、ドキュメントに記述してインデックス化した新しい情報はどうでしょう?
2回目以降の質疑は、1分半を目安に回答が返ってきました。
Next
外部データソースにナレッジベースやナレッジグラフを使ってみます。
まずは数学演算をMathematica(Wolfram)にお願いしてみましょう。
ちなみに、ラズパイにWolframはFullのimageではプレセットされていますが、他のimageの場合セットされていません。
インストールするには……..
|
1 2 3 |
sudo apt update sudo apt upgrade -y sudo apt install wolfram-engine -y |
>wolfram
WolframGPT
賢いです。
Leave a Reply