
Appendix にラズパイ4での結果を追加しました。
今までは型落ちといえども一応PCを使ってきましたが、今回はSBC(シングルボードコンピュータ)です。

MicroSDカードは64GBは必要です。できれば128GBを使います。
OSイメージはRaspberry Pi OS 64-bit Bookworm (Debian 12) です。
Python は3.11.2 。
OSインストールと環境設定後は、メモリ節約のためCLIモードで再起動します。
CLI画面からデスクトップ画面を再表示する場合は
>startx
注:デスクトップを使わないという意味でOS Lite (64-bit) という選択もありますが、どっちにしろそんなに差はないようです。
8GBメモリに対して、Lite –> 7329.8 MiB Free , CLI –> 7453.3 MiB Free
前回同様にHuggingFaceにアップしてあるcyberagent/calm2-7b-chatをggufに変換後、今度はq4_0型に量子化してから使ってみます。
推論実行中は素のままだとCPU温度が85℃を超える場合もあるので冷却FAN(できればヒートシンクも)は必須です。
Raspberry Pi 5は5V/5A の電源が推奨されていますが、このようなタスクのみなら5V/3A でも問題ありませんでした。

また、同梱されているドキュメントにはオーバークロックはしないでね…..と明記されているので動作周波数は2.4GHzのままです。
やってみました、7B(70億)パラメータの量子化モデルがさほどのストレスもなく、何の問題もなしで動きました。
Python仮想空間(venv1)を作ってそこで実行してみます(pip は仮想空間でしか使えないようです)。
|
1 2 3 |
python3 -m venv venv1 source venv1/bin/activate |
必要なライブラリなどをインストール
|
1 2 3 |
sudo apt install build-essential pkg-config libopenblas-dev -y pip install transformers accelerate bitsandbytes sentencepiece |
llama.cpp をインストール
|
1 2 3 4 5 6 7 |
mkdir ~/llama.cpp curl -L https://github.com/ggerganov/llama.cpp/archive/refs/tags/b1620.tar.gz | tar zx -C llama.cpp --strip-components=1 cd ~/llama.cpp make -j4 LLAMA_OPENBLAS=1 |
ディレクトリを作ってモデルをHuggingFace からダウンロードします。CyberAgent のcalm2-7b-chat です。
|
1 2 3 4 5 6 |
cd ~/ mkdir -p models/hf models/gguf pip install --upgrade huggingface_hub python3 -c 'import huggingface_hub; huggingface_hub.snapshot_download(repo_id="cyberagent/calm2-7b-chat", cache_dir="./models/hf")' |
python でvocab.json(頻度の高いトークンのリスト)を作成します。
cd ~/models/hf/models--cyberagent--calm2-7b-chat/snapshots/3e110c7624ff7a940badebfd5f9a91569f98cc56
>python3
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
from transformers import AutoTokenizer import json with open("./config.json", "r") as config_file: config = json.load(config_file) tokenizer = AutoTokenizer.from_pretrained("./") vocab = tokenizer.vocab if config["vocab_size"] > tokenizer.vocab_size: META_TOKEN = "▁▁" for i in range(config["vocab_size"] - tokenizer.vocab_size): token = "{}{}".format(META_TOKEN, i) vocab[token] = tokenizer.vocab_size + i with open("vocab.json", "w") as vocab_file: json.dump(vocab, vocab_file) |
pythonコンソールを抜けてvocab.jsonファイルが作成されているのを確認。

llama.cppディレクトリのトップに移動
|
1 |
cd ~/llama.cpp |
GGUFファイルを作成します。
python3 convert.py --vocabtype bpe --outfile ~/models/gguf/calm2-7b-chat.gguf ~/models/hf/models--cyberagent--calm2-7b-chat/snapshots/3e110c7624ff7a940badebfd5f9a91569f98cc56
q4_0型で量子化。
|
1 |
./quantize ~/models/gguf/calm2-7b-chat.gguf ~/models/gguf/calm2-7b-chat-q4_0.gguf q4_0 |
いつもどおり「日本で一番高い山はどこですか?」と尋ねてみます。
|
1 2 |
./main -m ~/models/gguf/calm2-7b-chat-q4_0.gguf -n 500 -p "USER:日本で一番高い山はどこですか? ASSISTANT: " |
次いで、「雨降りの準備はどうしたらいいですか?」。
|
1 2 |
./main -m ~/models/gguf/calm2-7b-chat-q4_0.gguf -n 500 -p "USER:雨降りの準備はどうしたらいいですか? ASSISTANT: " |
LLMの7BパラメータモデルをWebで使ってみると同様にHTTPサーバーを建てることもできます。
|
1 2 3 |
cd ~/llama.cpp ./server -m ~/models/gguf/calm2-7b-chat-q4_0.gguf --host 0.0.0.0 -t 4 --port 8000 |
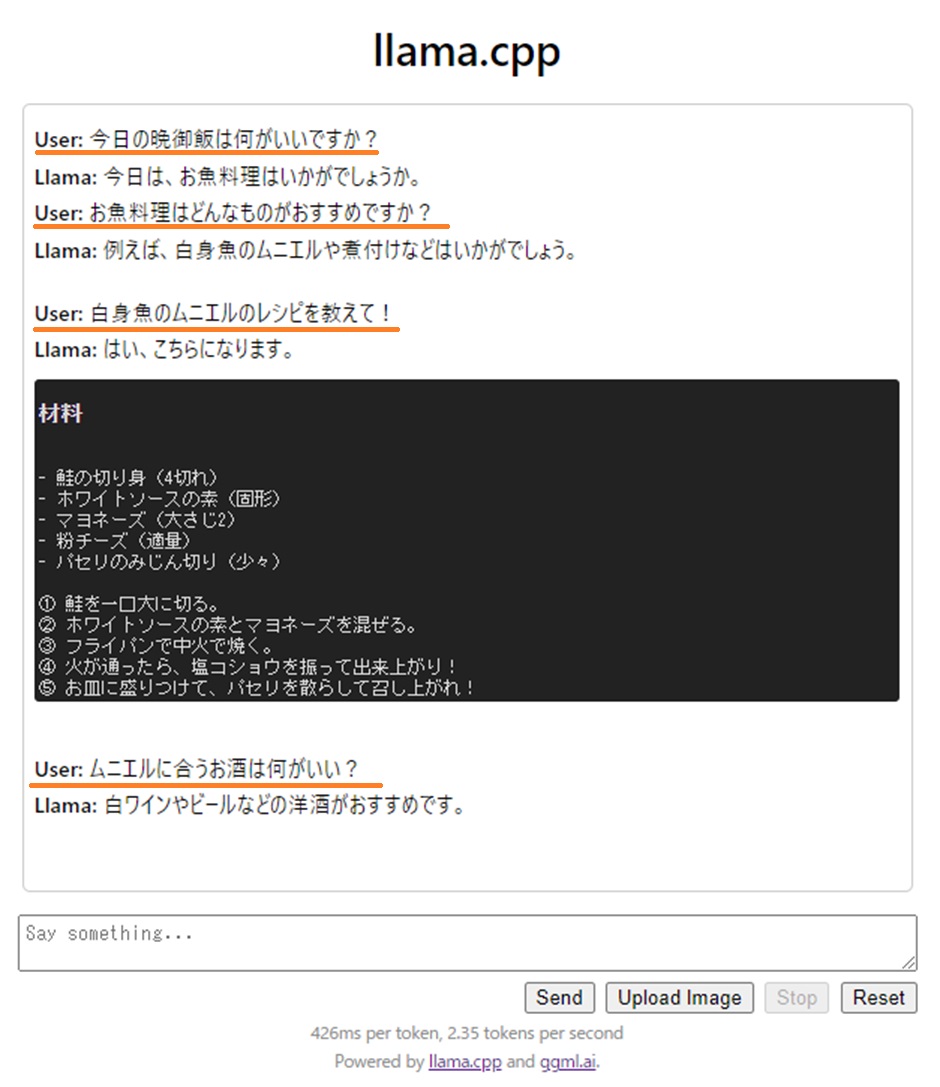
こんな感じ。
さほどのストレス無しで応答が返ってきましたが、最後の質問には何故か30秒以上応答が返ってきませんでした。
Appendix
ラズパイ4(8MG)でも実行可能でした。ただ、応答速度は少々遅いです(5との差は単純に動作周波数の差かも…2.4 : 2 )。
組み合わせはこんな感じ。
Raspberry Pi 4 (8GB) + Raspberry Pi OS Lite Bookworm (64-bit) + オーバークロック(2GHz)
以下のライブラリを追加
|
1 |
sudo apt-get install gcc python3-dev |
モデルの読み込みはだいぶ時間がかかりました。
推論に関しては、一瞬「あれ?まだかな?」というタイミングで応答が返ってくる感じです。
ラズパイのオーバークロックについては以下を参照
Appendix1
ラズパイ4(8MG)ではオーバークロックしても7Bサイズのモデルは少々苦しいです。サイズを落として3Bではどうでしょう。
日本語対応の3Bモデルでは、CyberAgent のOpenCalm がありました。HuggingFace のmmnga/cyberagent-open-calm-3b-ggufに量子化済のモデルがアップされています。
この中からcyberagent-open-calm-3b-q4_0.ggufを使ってみます。
ディレクトリを作成してダウンロードします。
|
1 2 3 4 |
mkdir -p ~/models/gguf cd ~/models/gguf wget https://huggingface.co/mmnga/cyberagent-open-calm-3b-gguf/resolve/main/cyberagent-open-calm-3b-q4_0.gguf |
llama.cpp をクローンしてビルドしますが、他のページで使ったllma.cppではモデルのロードで失敗します。
以下のllama.cppを使えということでした。
|
1 2 3 4 |
cd ~/ git clone --branch mmnga-dev https://github.com/mmnga/llama.cpp.git cd llama.cpp make -j |
このモデルはChatやInstruction のような使い方はできません。得意なのはセンテンスの続きを予測して文章を生成することです。OpenCalm を対話型にする場合はファインチューニングする必要があります。このページ参照。
以下のようなプロンプトを実行させてみます。
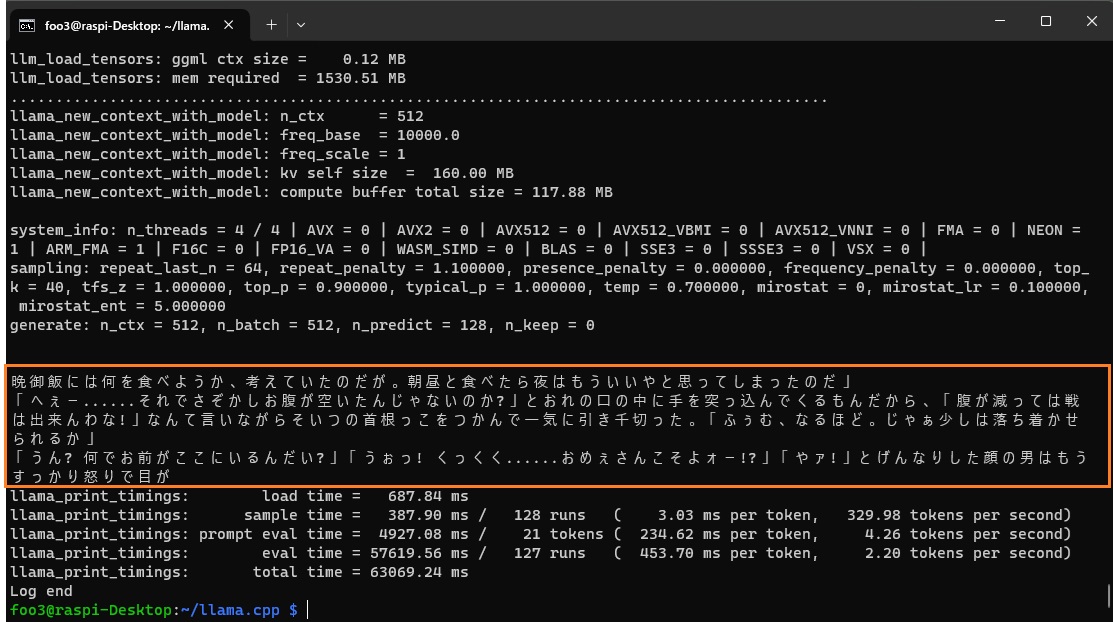
./main -m '/home/foo3/models/gguf/cyberagent-open-calm-3b-q4_0.gguf' -n 128 -p '晩御飯には何を食べようか、考えていたのだが' --top_p 0.9 --temp 0.7 --repeat-penalty 1.1
こんな感じ。文章の生成自体はスムーズでした。生成文はかなりシュールですが。基本的にOpenCalm-3Bの生成文はかなり変です。
Appendix2
試しに5もオーバークロックして、3GHzでやってみました。
軽快に応答してくれます。ただし、CPU温度は冷却対策してもMaxで84.8度まで上昇していました。
同梱のドキュメントには「オーバークロックをしてはなりませぬ…..」とか記載してますが、公式では否定してないみたいですね。
Appendix3
Swap も使われていますが、メモリは8GBギリ消費されています。
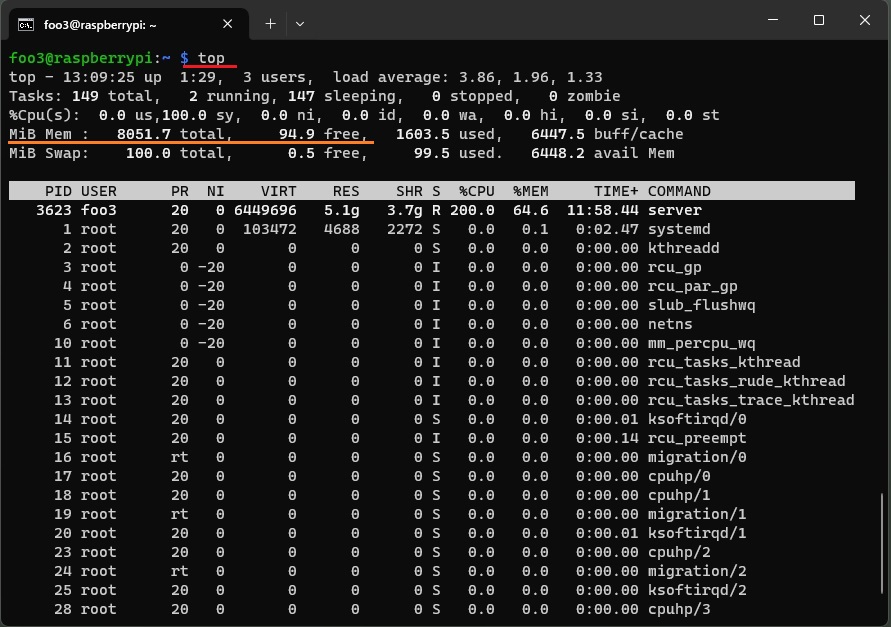
Appendix4
型落ちPCのCPUのみで、日本語対応の7B(70億)パラメータのLLMを量子化して使ってみる
Appendix5
HuggingFace Hub リンク
elyza/ELYZA-japanese-Llama-2-7b
量子化済み ELYZA-japanese-Llama-2-7b-fast-instruct
量子化済み rinna-youri-7b-chat
量子化済み cyberagent-open-calm-3b
Appendix6
ラズパイ5ではUbuntuをImager からインストールする場合、バージョンはServer 23.10です。
参考 ラズパイ4(4GB) にUbuntu Server 20.04 LTS をセットアップ、GUI追加
venvが入っていないので以下実行
|
1 |
sudo apt install python3.11-venv |
後は同様にやってみましょう。
Appendix7
量子化ってどういうことかの説明から、BitNet b1.58って何?まで。
Next
エッジでLLM が使えるかも….となったら、次はLangChain + LlamaIndex でプライベート情報を読み込んでインデックス化して使ってみます。
クラウドのLLMではプライベート情報を載せるわけにはいきませんが、オフラインのエッジデバイスなら問題は起きません。
ただ、結果からいいますと、ラズパイ5(8GB)でELYZA やRinnaの7Bモデルを3GHzにオーバークロックして実行させても応答が返ってくるのに1分30秒弱かかってしまいました。まあ、使えないことはないですが、あまり使いたくないパフォーマンスでした。
BitNet b1.58 が使えるようになるまで待った方がいいのかも….(Jetson Orin NX 16GB は高価すぎるし)。
各種パッケージやライブラリのバージョン合わせが面倒で、動いているllama-index のバージョンは0.6.24です。
Leave a Reply