
M5Stack のLLM モジュールを使って、大規模言語モデルを動かしてみます。
M5Stack LLM モジュールとはオフライン環境でLLMの活用を可能にするモジュールです。
処理能力はAxera AX630Cプロセッサ搭載で3.2 TOPS@INT8です。
またM5Stack LLM モジュールとデバッグボードのM5Stack LLM Mate モジュールがセットになったものがキット販売されています。
M5Stack LLM Mate モジュールとはType-CのUSBポートとイーサーネットポート(RJ45)を持ったデバッグ用ボードです。FPCケーブルで接続して使います。
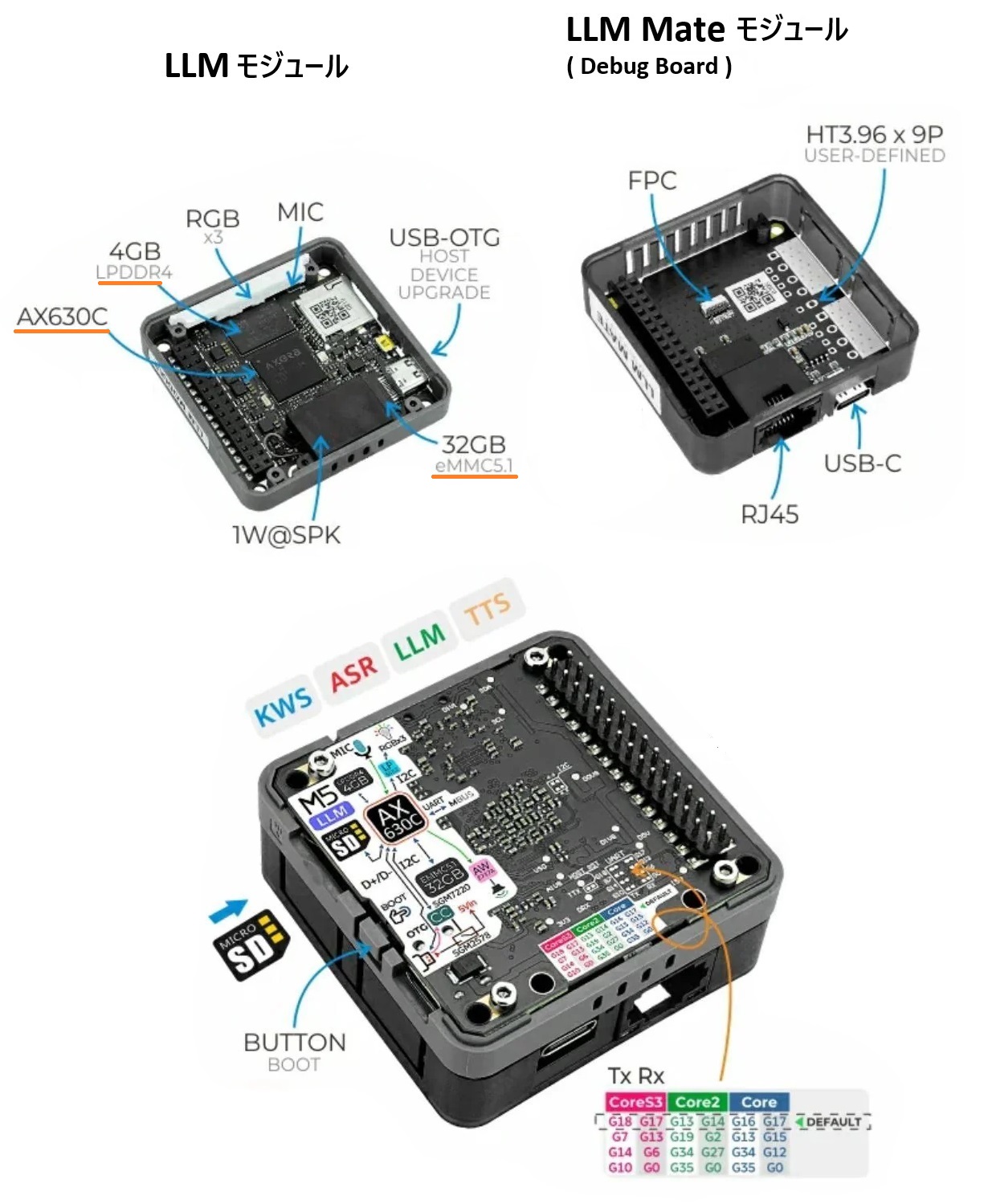
具体的には出荷時状態で以下のような処理に対応しています。
KWS(ウェイクワード)、ASR (音声認識)、LLM(大規模言語モデル)、 TTS (テキスト音声合成)
ここではWindows11 をプラットフォームにしてモジュールを覗いてみます。
Windows11 Pro (24H2)64ビット環境です。
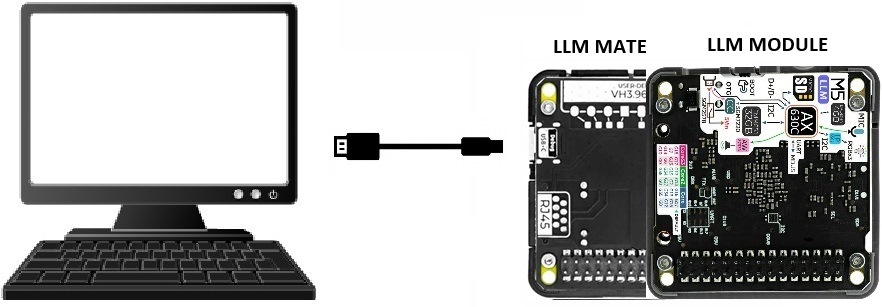
LLM モジュールとPC(Windows11)とはUSBでシリアル接続します。PCからはCOMポート経由でモジュールを覗いてみるので、事前にTera Term(5.4.1) などをインストールしておきます。
また、LLM モジュールにはUbuntu 22.04 LTS が組み込みインストールされているので、ip address でアドレスを確認したらSSHで規定ユーザーのroot@アドレスに入ることができます。パスワードは123456です。
WindowsからLLM モジュールにアクセス
① LLM モジュールとLLM Mate モジュール(Debug Board)をFPCケーブルで接続します。
FPCの結節部は非常に小さいので慎重に作業します。結節の基本作業は、UPー>挿入ー>DOWNです。
作業はピンセットなどを使わないと指と爪では無理でした。

② LLM Mate モジュール(Debug Board)のType C USBポート(A)とPCを接続し、イーサーネット(B)でネットワークに有線接続しておきます。
ネットワーク接続はファームウェアやソフトウェアアップグレードに必須ですが、それ以外には外していても可です。Wi-Fiドングル(TL-Wn725N)も使えるようです。

③ PC側でデバイスマネージャを開き、接続したCOMポートを確認します(CH340と表示されているポート)。
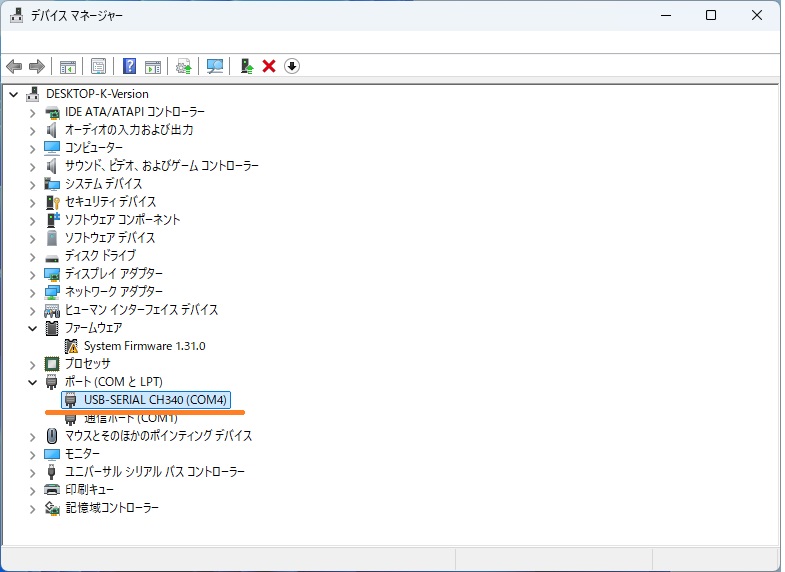
CH340はUART – USB変換チップのことだそうです。
うまく表示されていない場合、PC側にドライバがインストールされていない可能性があるためインストールします。
④ Tera Termなどのターミナルソフトを使って、ターゲットのCOMポートを開きます。
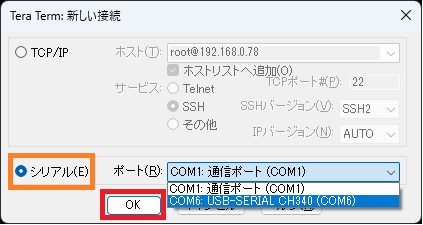
メニュー>設定ー>端末で開きます。
通信速度は115200bpsに設定
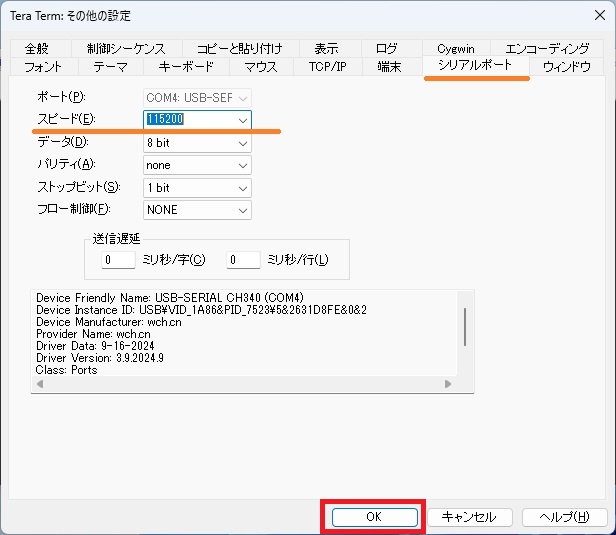
この時点ではモジュールが起動していないので、Tera Term が起動しても何も表示されていません。
では、モジュールに通電します。
⑤ LLM モジュールに電源を供給します。
LLM モジュール のType C USBポートとモバイルバッテリーを接続、側面のライトが点灯します。

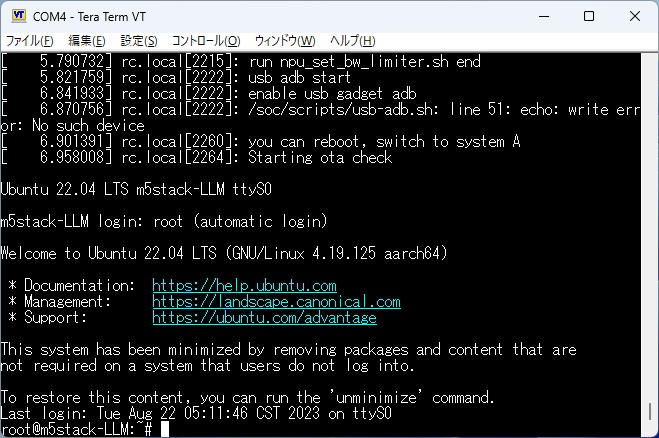
赤から緑に変わることでモジュールの起動が確認できます。

Tera Term に、LLM モジュールの組み込みOSのUbuntu 22.04が表示されています。
LLM モジュールのファームウェアをアップグレード
M5Stack 公式では2つの方法が示されています(日本語)。
1つはファームウェアフラッシュ(システムアップグレード、デバイスパッケージ全体のフラッシュに使用)。
もう1つはソフトウェアアップグレード(アプリケーションアップグレード、aptパッケージ管理ツールを使用して機能ユニットをダウンロードおよびアップデート)です。
●ファームウェアフラッシュ
システムのフルアップグレードや、システムの損傷からの回復に使用します。書き込みツールは現在Windowsでのみサポートされています。
eMMCストレージにファームウェアを書き込んでアップグレードします。
上記のリンク先から必要なファイルをダウンロードします。
1.ファームウェアパッケージ(axpファイル)

2.フラッシュツールとドライバープログラムをダウンロードし、ドライバープログラムのインストール
ドライバーはWin10用となっていますがWin11でも必須です。セットアップしておきます。

3.フラッシュツールを開き、左上の load ボタンをクリックしてファームウェアパッケージをロード
AXDL_V1.24.13.1 ー> Bin ー> AXDL.exeを起動
起動したら、左上のアイコンをクリックして、先にダウンロードしておいたファームウェアパッケージ (.axp)をロードします。
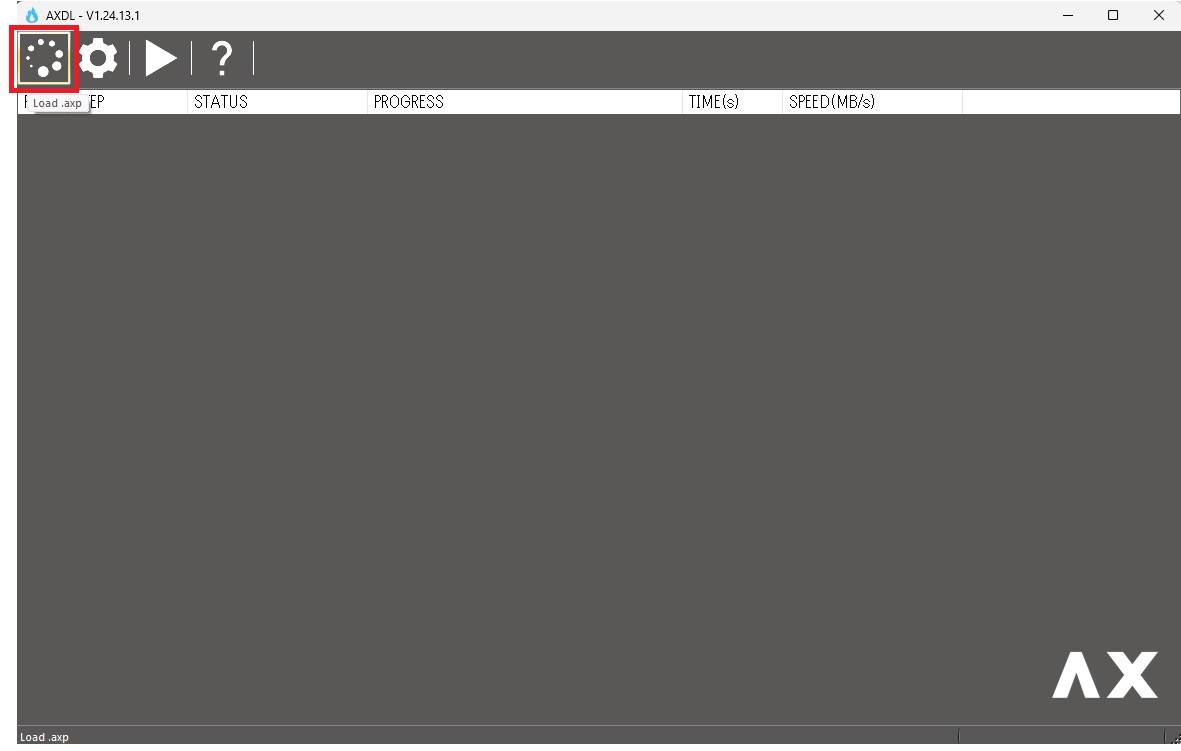
展開して読み込まれます。

完了したら先にLLMモジュールの電源を切っておきましょう。
それから、△のアイコンをクリックして書き込み準備状態にしておきます。
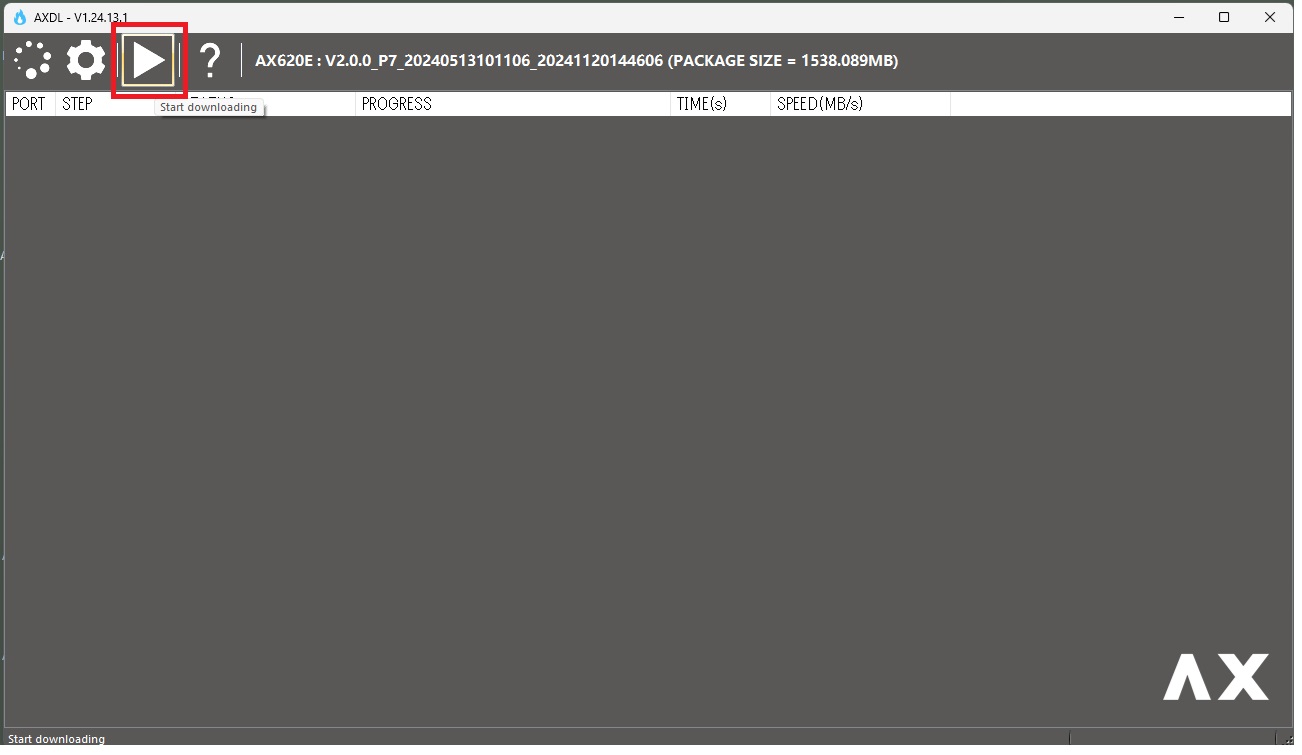
待機中
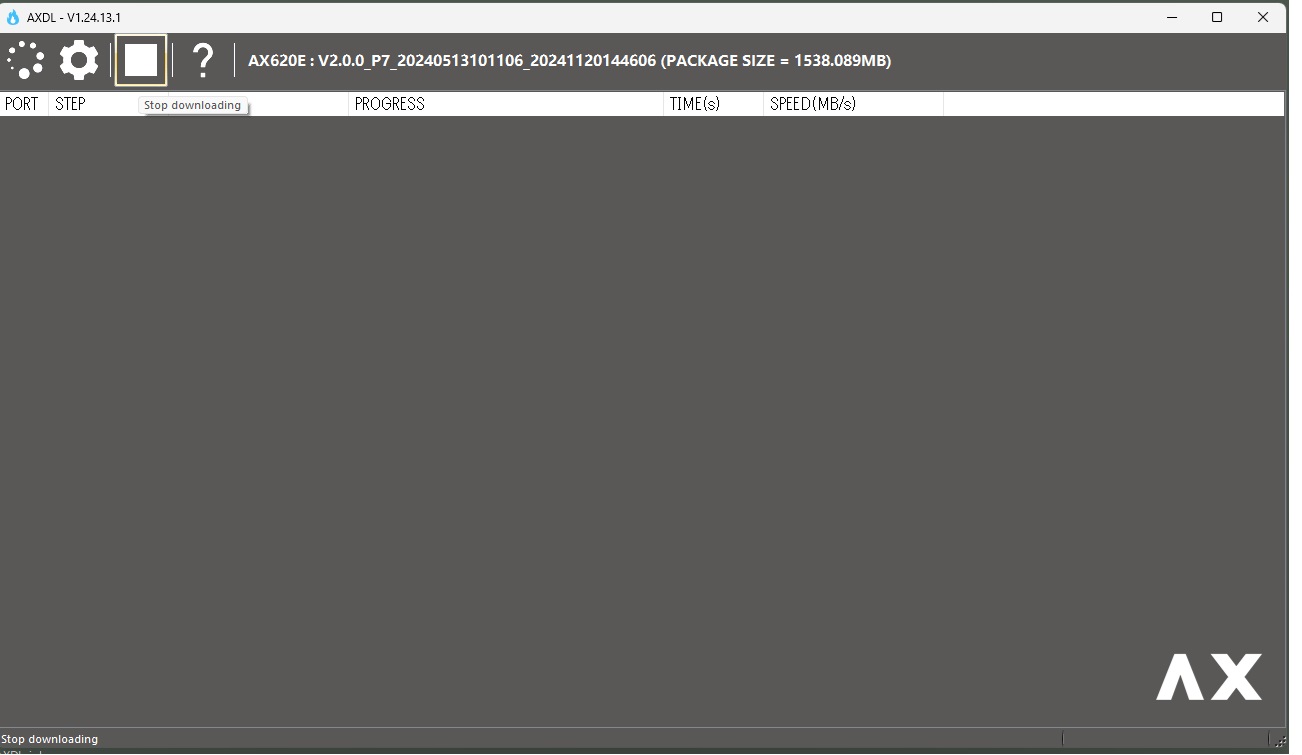
4.ファームウェアのフラッシュ
LLMモジュールのBOOT BUTTON を押しながら、USB Type-CポートでPCと接続します。

速攻で書き込みが開始されます。BOOT BUTTON から指を離してもOKです。
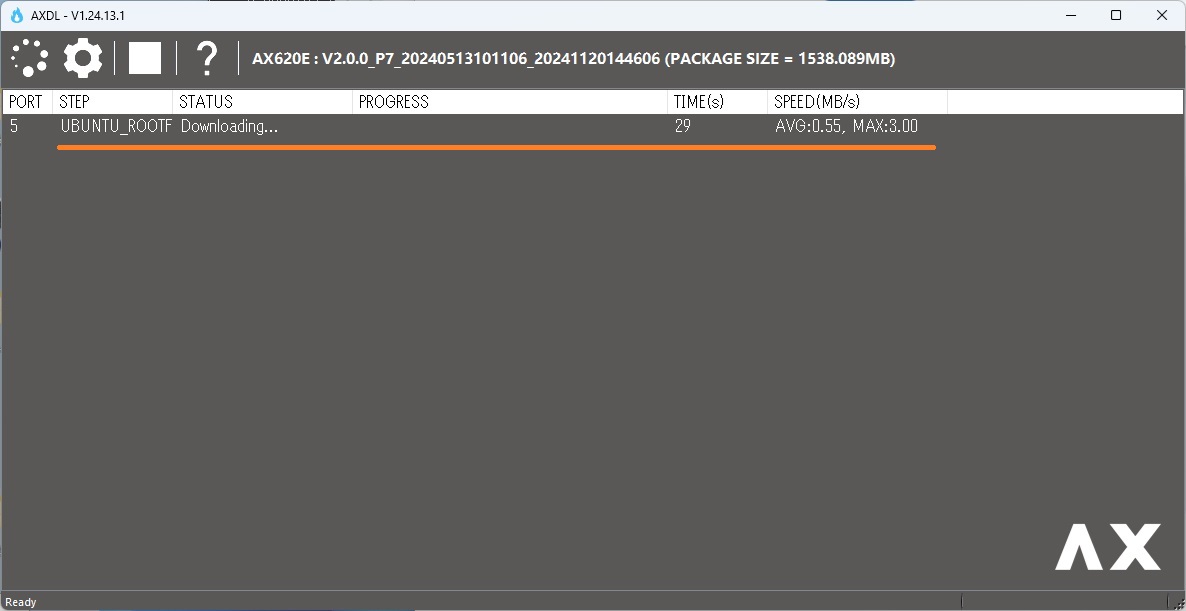
やや時間を要した後、終了。
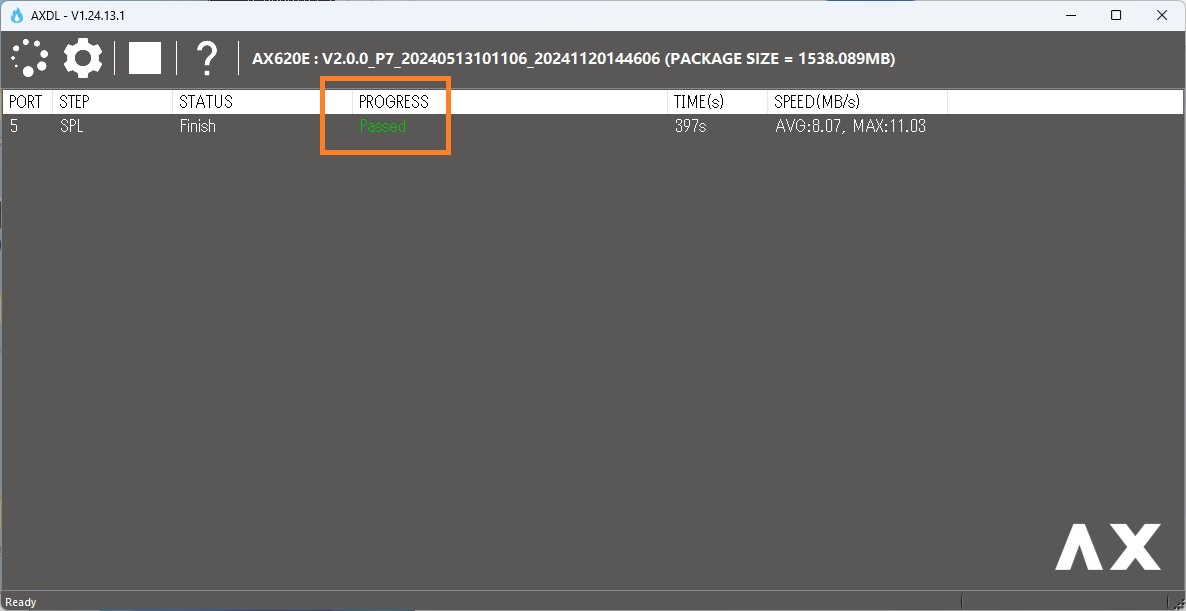
●ソフトウェアアップグレード
通常Linuxのアップグレードはaptコマンドを使いますが、モジュールのOSは組み込みLinuxなのでaptを使ったupgradeはやらない方がいいそうです。
1. Tera Term のコンソールから以下のコマンドでGPGキーを追加し、M5Stackソフトウェアソース情報をシステムのソフトウェアソースリストに含めます。
wget -qO /etc/apt/keyrings/StackFlow.gpg https://repo.llm.m5stack.com/m5stack-apt-repo/key/StackFlow.gpgecho 'deb [arch=arm64 signed-by=/etc/apt/keyrings/StackFlow.gpg] https://repo.llm.m5stack.com/m5stack-apt-repo jammy ax630c' > /etc/apt/sources.list.d/StackFlow.list
2. apt updateコマンドを実行してパッケージインデックスを更新します。
|
1 |
apt update |
3.利用可能なLLM Debianパッケージのリストを表示します。llm-model-nameという形式で名前が付けられているものはモデルパッケージ、llm-nameという名前が付けられているものは機能ユニットパッケージです。
|
1 |
apt list | grep llm |
4.必要に応じてaptコマンドを使用してソフトウェアパッケージをインストールします。
たとえば、llm-whisperパッケージをインストールします。注:モデルは大量のディスク容量を占有します。必要に応じてインストールすることをお勧めします。
|
1 |
apt install llm-whisper |
* aptリポジトリに存在しなくなっている場合は.debをダウンロードして、aptでローカルからインストールします。
ソフトウェアパッケージの詳細については、StackFlow Githubのパッケージリストをご覧ください。モデル構成JSONファイルが含まれており、モデルのソース(ホームページ)、機能、データ形式を確認できます。
〇依存パッケージ
lib-llm : ソフトウェア動作に必要な環境を提供
https://repo.llm.m5stack.com/m5stack-apt-repo/pool/jammy/ax630c/v1.8/lib-llm_1.8-m5stack1_arm64.deb
llm-sys : StackFlowの基本機能を提供
https://repo.llm.m5stack.com/m5stack-apt-repo/pool/jammy/ax630c/v1.6/llm-sys_1.6-m5stack1_arm64.deb
〇機能モジュール (ユニットパッケージ)
llm-audio : 統一的なサウンドカード管理を提供
https://repo.llm.m5stack.com/m5stack-apt-repo/pool/jammy/ax630c/v1.6/llm-audio_1.6-m5stack1_arm64.deb
llm-camera : 統一的なカメラ管理を提供
https://repo.llm.m5stack.com/m5stack-apt-repo/pool/jammy/ax630c/v1.9/llm-camera_1.9-m5stack1_arm64.deb
llm-kws : キーワード検出機能を提供(ウェイクワード)
https://repo.llm.m5stack.com/m5stack-apt-repo/pool/jammy/ax630c/v1.9/llm-kws_1.9-m5stack1_arm64.deb
llm-vad : 音声活動検出機能を提供
https://repo.llm.m5stack.com/m5stack-apt-repo/pool/jammy/ax630c/v1.8/llm-vad_1.8-m5stack1_arm64.deb
llm-asr : 自動音声認識機能を提供
https://repo.llm.m5stack.com/m5stack-apt-repo/pool/jammy/ax630c/v1.7/llm-asr_1.7-m5stack1_arm64.deb
llm-whisper : 音声をテキストに変換する機能を提供
https://repo.llm.m5stack.com/m5stack-apt-repo/pool/jammy/ax630c/v1.8/llm-whisper_1.8-m5stack1_arm64.deb
llm-llm : テキスト生成機能を提供
https://repo.llm.m5stack.com/m5stack-apt-repo/pool/jammy/ax630c/v1.9/llm-llm_1.9-m5stack1_arm64.deb
llm-vlm : マルチモーダルテキスト生成機能を提供
https://repo.llm.m5stack.com/m5stack-apt-repo/pool/jammy/ax630c/v1.9/llm-vlm_1.9-m5stack1_arm64.deb
llm-tts : テキストを音声に変換する機能を提供
https://repo.llm.m5stack.com/m5stack-apt-repo/pool/jammy/ax630c/v1.6/llm-tts_1.6-m5stack1_arm64.deb
llm-melotts : テキストを音声に変換する機能を提供
https://repo.llm.m5stack.com/m5stack-apt-repo/pool/jammy/ax630c/v1.9/llm-melotts_1.9-m5stack1_arm64.deb
LLM モジュールを使ってみる
M5Stack の製品ですので、画面表示や電源供給などでM5コントローラーにスタックして利用することが想定されているようですが、モジュールにはマイクとスピーカーが最初からついているので素のままで使うこともできます。

上記のTera Term のコンソール画面からKWS(ウェイクワード)機能を使ってみます。
ウェイクワードというのはApple のSiri やAmazon のAlexa のように何かを起動させる「きっかけになる言葉、掛け声」のことです。
恰好のサイトがあります、参考にさせていただきました。
上記機能モジュールはLLM モジュールにインストールされて提供されています。
これらの初期化の方法なども含めてKWS実行用のPythonサンプルコードがあります。
やってみましょう。
まずtelnetlib3ライブラリを使うのでpipでインストールしておきます。
「venvの仮想環境でインストールしたほうがいいですよ」という警告が出ますが、そのままインストールしてしまいます。
|
1 |
pip install telnetlib3 |
【kws-test.py】
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 |
#!/usr/bin/env python3 import asyncio import telnetlib3 import json import os DEFAULT_TIMEOUT = 120 async def send_command_and_wait(reader, writer, command, timeout=DEFAULT_TIMEOUT): command_str = json.dumps(command) full_command = command_str + "\n" writer.write(full_command) await writer.drain() print("送信:", command_str) try: response_line = await asyncio.wait_for(reader.readline(), timeout=timeout) except asyncio.TimeoutError: raise TimeoutError(f"タイムアウト({timeout}秒): 応答がありません。") response_line = response_line.strip() try: response_json = json.loads(response_line) except Exception as e: raise ValueError(f"応答のパースに失敗しました: {e}") print("受信:", response_json) return response_json async def send_command_and_wait(reader, writer, command, timeout=DEFAULT_TIMEOUT): command_str = json.dumps(command) full_command = command_str + "\n" writer.write(full_command) await writer.drain() print("送信:", command_str) try: response_line = await asyncio.wait_for(reader.readline(), timeout=timeout) except asyncio.TimeoutError: raise TimeoutError(f"タイムアウト({timeout}秒): 応答がありません。") response_line = response_line.strip() try: response_json = json.loads(response_line) except Exception as e: raise ValueError(f"応答のパースに失敗しました: {e}") print("受信:", response_json) return response_json async def receiver_loop(reader): print("受信ループ開始:常時メッセージ待機中...") while True: try: line = await reader.readline() if not line: print("リモート側が接続を閉じました。") break line = line.strip() if not line: continue try: msg = json.loads(line) print("非同期受信:", msg) except Exception as e: print("JSONパースエラー:", e, "受信データ:", line) except Exception as e: print("受信ループで例外発生:", e) break async def main(): host = '127.0.0.1' port = 10001 try: reader, writer = await telnetlib3.open_connection(host, port) print(f"Telnet接続確立: {host}:{port}") except Exception as e: print("Telnet接続に失敗:", e) return # 初期化・セットアップ用コマンドのリスト commands = [ { "request_id": "1", "work_id": "audio", "action": "setup", "object": "audio.setup", "data": { "capcard": 0, "capdevice": 0, "capVolume": 0.5, "playcard": 0, "playdevice": 1, "playVolume": 0.5 } }, { "request_id": "2", "work_id": "kws", "action": "setup", "object": "kws.setup", "data": { "model": "sherpa-onnx-kws-zipformer-gigaspeech-3.3M-2024-01-01", "response_format": "kws.bool", "input": "sys.pcm", "enoutput": True, "kws": "ECHO" } }, { "request_id": "asr_setup", "work_id": "asr", "action": "setup", "object": "asr.setup", "data": { "model": "sherpa-ncnn-streaming-zipformer-20M-2023-02-17", "response_format": "asr.utf-8.stream", "enoutput": True, "enkws": True, "rule1": 2.4, "rule2": 1.2, "rule3": 30, "input": ["sys.pcm", "kws.1001"] } }, { "request_id": "llm_setup", "work_id": "llm", "action": "setup", "object": "llm.setup", "data": { "model": "qwen2.5-0.5B-prefill-20e", "response_format": "llm.utf-8.stream", "enoutput": True, "enkws": True, "max_token_len": 127, "prompt": "", "input": ["asr.1002", "kws.1001"] } }, { "request_id": "tts_setup", "work_id": "melotts", "action": "setup", "object": "melotts.setup", "data": { "model": "melotts_zh-cn", "response_format": "sys.pcm", "input": ["llm.1003", "kws.1001"], "enoutput": False, "enaudio": True } } ] # 各コマンドを順次送信して応答を待つ for cmd in commands: try: response = await send_command_and_wait(reader, writer, cmd, timeout=DEFAULT_TIMEOUT) error_code = response.get("error", {}).get("code") if error_code != 0: print("エラー応答:", response) break except Exception as e: print("コマンド送信中に例外発生:", e) break await asyncio.sleep(0.5) print("初期化完了。セッションは維持し、受信待ち状態に入ります。") os.system("echo 0 > /sys/class/leds/R/brightness; echo 0 > /sys/class/leds/G/brightness; echo 255 > /sys/class/leds/B/brightness") try: # 初期化後も接続を維持して常時受信待ち await receiver_loop(reader) except KeyboardInterrupt: print("KeyboardInterruptを受信、受信ループ終了。") finally: writer.close() print("Telnet接続をクローズしました。") if __name__ == "__main__": asyncio.run(main()) |
起動します。
|
1 |
python3 kws-test.py |
待機状態になるまでに少々時間がかかりました 。初回は5個のユニット初期化のためかな?2回目以降の起動は速いです。
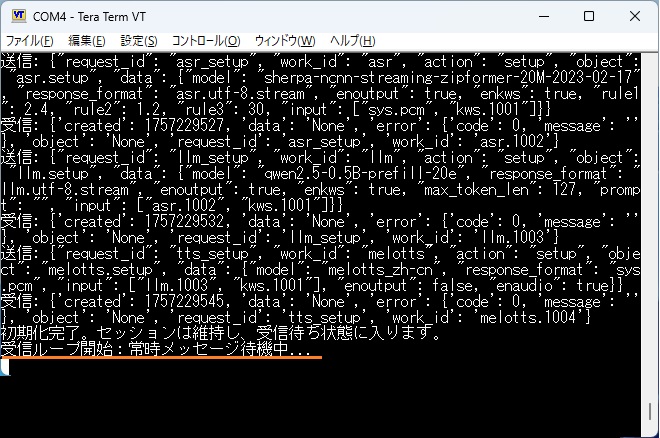
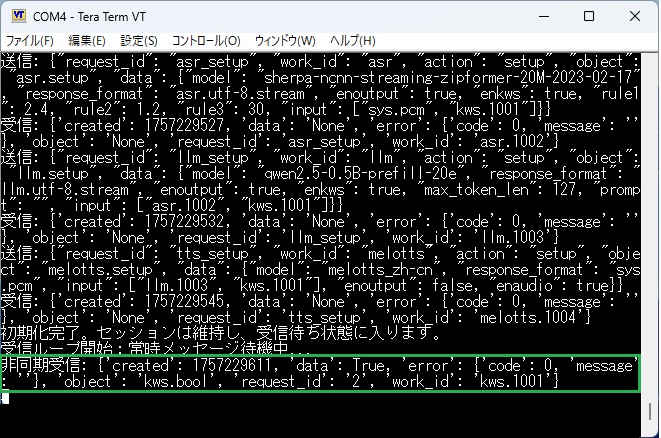
この状態でマイクに向かって「エコー」と声かけします。
この場合、かなり高い確率で認識してくれて、スピーカーを通じて「Hi」という返答が返されました。
●ウェイクワードを変更する場合
試しに「ALEXA」でやってみました。Pythonコードの初期化・セットアップ用コマンドのリストにある「ECHO」を書き換えてLLM モジュールから再起動をかけます(上記ソースコードの111行目)。
認識率は悪いですが「Hi」という返事を返してくれます。また以前の「ECHO」で声掛けすると女性の声で何やらアナウンスを返してきました(小さい声なので何を言ってるのか分かりませんでしたが….)。
他に認識率の高いワードを探してみてもいいかもしれません。
●自動起動のやり方は上記のサイト内でsystemdでの方法が紹介されていますが、rc.localでも可です。
nano /etc/rc.local
最後尾に以下を記述します。Pythonコードは/rootに置かれているとして、
python3 /root/kws-test.py &
再起動
reboot
LLM モジュールが起動すると側面のライトが赤から緑に変わり、kws-test.pyが起動完了すると、緑から青に変わるので確認できます(体感的には2分弱)。

これで、LLM モジュール単体でKWSを実行できます。
Appendix
SSHで入る場合
まずはIPアドレスを確認しておきます。
>ip address
例:eth0 ー> 192.168.0.50
既定のユーザー名でログイン
>ssh root@192.168.0.50
パスワードは、123456
●固定IP設定
デフォルトはDHCPでアドレス取得しているので、起動ごとにIPアドレスは変わっています。
固定しておくと便利です。
interfacesを編集
nano /etc/network/interfaces
コメントアウト
#iface eth0 inet dhcp
適宜の部分を書き換えて新規追加
iface eth0 inet static
address 192.168.0.50 #<-適宜
netmask 255.255.255.0
gateway 192.168.0.1 #<-適宜
dns-nameservers 122.197.254.137 #<-適宜
再起動
reboot
Appendix2
lllm モジュールはデフォルトで32GBのeMMCストレージを持っています。
でも、追加で新しいモデルを使うような場合、自身の上でいろいろコンパイルやビルドする必要がありますが、既存のストレージ上でやるのは少々危険という話があるようです。
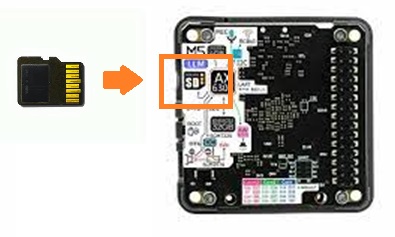
MicroSD カードでストレージを追加しておきます。
exFATでフォーマットした8GB以上のSDカードならOKなようです。
スロットに挿入したら即、/mnt/mmcblk1p1にマウントされます。
なんでもいいですが、ワーキング用のディレクトリを作っておきます。
>cd /mnt/mmcblk1p1
>mkdir MyWork
Appendix3
マイコンレベルでエッジAIをやってみる場合、Arducam社のPico4MLを使う手もあります。
TinyML というフレームワークを使っていて、名前からも察しがつくようにラズパイ財団のRP2040というチップで動いています。
Arducam のPico4ML でエッジAI を試してみる
Next
M5Stack CoreS3 をスタックして、結果をディスプレイに表示してみます。
開発環境にはArduino IDE を使ってみます。
画像認識(YOLO)とかLLM 推論とか……
Windows 11からM5Stack LLM モジュール に触ってみる(2)環境設定とアプリケーション
関連ページ
Windows 11からM5Stack LLM モジュール に触ってみる(1)アクセス編
Windows 11からM5Stack LLM モジュール に触ってみる(2)環境設定とアプリケーション
Windows11からM5Stack LLM モジュール に触ってみる(3)アプリケーション(TTS)
Windows11からM5Stack LLM モジュール に触ってみる(4)アプリケーション(SerialTextAssistant + TTS)
LLM モジュール のSerialTextAssistant + TTS のシリアルモニタにPythonを使ってみる
Leave a Reply