
ここではチュートリアルとは少し趣向を変えてやってみます。
●Jupyter Notebookは使わずに、Pythonファイルで実行できるようにする
●PythonのカメラインターフェースはJetCam ではなくOpenCVのVideoCaptureクラスを使う
●ビデオ表示にはtkinter + canvas を使う
Jetsonコーディングの流儀からはちょい外れてるかも^^
JetsonのカメラインターフェースはJetCam以外にもVideo-Viewerというのもあります。
trt_pose_hand は trt_pose の手の形推定バージョンです。
こういう推定をします。

trt_pose_handには5つのNotebookが用意されています。
1.live_hand_pose.ipynb
カメラを通して上図ような手の形(gesture)にpose画像(線と丸)を表示するだけのシンプルなNotebook
2.mini_paint_live_demo.ipynb
カメラを通して手の形(gesture)を5つのパターンで認識して、カメラ画面の上に点で動きをトレースして描画したり消去したりするNotebook
3.cursor_control_live_demo.ipynb
カメラを通して手の形(gesture)を5つのパターンで認識して、マウスカーソルをコントロールするNotebook
4.gesture_data_collection_pose.ipynb
独自の手の形(gesture)を学習して分類するためのデータセットを作成するNotebook
5.gesture_classification_live_demo.ipynb
独自に手の形(gesture)を分類するための学習を実行するNotebook
今回は1と2の中間にあるようなものを作ってみましょう。
ただしNotebookは使いません。
カメラを通して手の形(gesture)を5つのパターンで認識して、どんなパターンかを画面に文字表示してみます。
パターンはこんな感じ(panとstopの違いがよく分かりませんでした)。
手がフレームアウトすると「no hand」と表示されます。

こんな感じ。

以下の記述で/home/jetsonのユーザー名は適宜ご自分の環境のユーザー名で置き換えてください。
1.実行環境作成
Jetson Nano、jetpack(4.5.1)、NVIDIAコンテナーを使います。
実行環境はtrt_pose がベースになっています。
作業用ディレクトリはwork-hand、コンテナ名はmy_handとしておきます。
|
1 2 3 |
mkdir work-hand sudo docker pull nvcr.io/nvidia/l4t-ml:r32.5.0-py3 sudo docker create -it --name my_hand --gpus all --network host -e DISPLAY=$DISPLAY -v /tmp/.X11-unix/:/tmp/.X11-unix --device /dev/video0:/dev/video0:mwr -v /home/jetson/work-hand:/work nvcr.io/nvidia/l4t-ml:r32.5.0-py3 |
コンテナの設定や起動まではこのページを参照してください。ただし、JetCamやJupyterの拡張機能のインストールは不要です。trt_poseのインストールまでをやっておきます。
Pythonファイルの実行にはscikit-learn が使われている箇所があります。SVMを使った分類です。
コンテナのscikit-learnのバージョンは0.24.1なので0.23.2にダウングレードする必要があります。
必須というわけではないですが、しないと以下のような物騒なメッセージが表示されます。
UserWarning: Trying to unpickle estimator StandardScaler from version 0.23.2 when using version 0.24.1. This might lead to breaking code or invalid results. Use at your own risk.
まぁ、やっておきます(小一時間ほどかかります….)
|
1 2 |
pip3 uninstall scikit-learn pip3 install scikit-learn==0.23.2 |
tkinterをインストール
|
1 |
apt -y install python3-tk |
2.trt_pose_hand 用の環境作成
まず、以下のようにGithub からtrt_pose_hand 用の環境をダウンロードしておきます。

次に、重みファイルをダウンロード
| Model | Weight |
|---|---|
| hand_pose_resnet18_baseline_att_224x224_A | download model |
解凍したディレクトリファイル内のmodelディレクトリにこの重みファイルをコピーしておきます。
最後にディレクトリファイルをまるごと、1.で作成したコンテナのマウントフォルダー(/home/jetson/work-hand/torch2trt/trt_pose/tasks)にコピーします。
例えば、こんなコマンドを使います(ディレクトリ名などが違っていたら修正)
sudo cp -r /home/jetson/Downloads/trt_pose_hand-main /home/jetson/work-hand/torch2trt/trt_pose/tasks
3.TensorRTで重みファイル(hand_pose_resnet18_baseline_att_224x224_A)を最適化しておく
torch2trtで最適化します。
コンテナで以下を実行
ディレクトリを移動してPythonコンソールに入ります。
|
1 2 3 |
cd /work/torch2trt/trt_pose/tasks/trt_pose_hand-main python3 |
最適化を実行
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
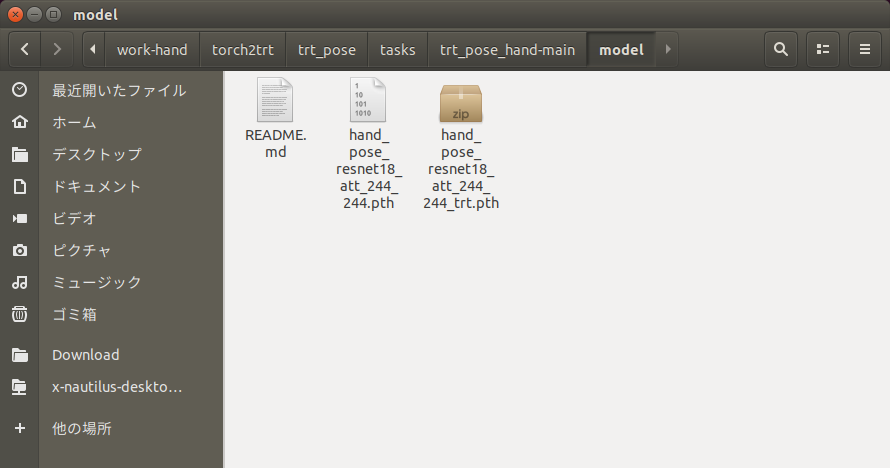
import os import json import trt_pose.coco import torch #+++++++++++++++++++++++++++++++++++++++++++++++++++++++++ with open('preprocess/hand_pose.json', 'r') as f: hand_pose = json.load(f) topology = trt_pose.coco.coco_category_to_topology(hand_pose) import trt_pose.models #+++++++++++++++++++++++++++++++++++++++++++++++++++++++++ num_parts = len(hand_pose['keypoints']) num_links = len(hand_pose['skeleton']) model = trt_pose.models.resnet18_baseline_att(num_parts, 2 * num_links).cuda().eval() #+++++++++++++++++++++++++++++++++++++++++++++++++++++++++ WIDTH = 224 HEIGHT = 224 data = torch.zeros((1, 3, HEIGHT, WIDTH)).cuda() MODEL_WEIGHTS = 'model/hand_pose_resnet18_att_244_244.pth' model.load_state_dict(torch.load(MODEL_WEIGHTS)) import torch2trt model_trt = torch2trt.torch2trt(model, [data], fp16_mode=True, max_workspace_size=1<<25) OPTIMIZED_MODEL = 'model/hand_pose_resnet18_att_244_244_trt.pth' torch.save(model_trt.state_dict(), OPTIMIZED_MODEL) |
hand_pose_resnet18_att_244_244.pthがtorch2trtで最適化されて、hand_pose_resnet18_att_244_244_trt.pthが作成されます。
4.Pythonファイルを作っておく
JetsonではUSBカメラが1台のみ繋がっている前提で。

コンテナでPythonファイルを作っておきます。エディターはnano を使っていますが、なんでもいいです。
|
1 2 3 |
cd /work/torch2trt/trt_pose/tasks/trt_pose_hand-main nano pose_view.py |
【pose_view.py】
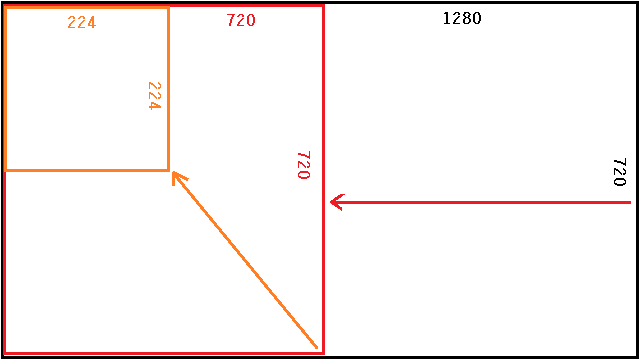
カメラインターフェースはOpenCVです。CVでキャプチャーした画面のサイズは1280x720、アスペクト比は16:9なので、clipとresizeで224x224にして使っています。
#—————-で挟まれたコードはlive_hand_pose.ipynbとmini_paint_live_demo.ipynbから抽出した部分
#—————-の外側がカメラ画像をOpenCVでキャプチャしてcanvasに転送している部分
キャプチャしたフレームごとにexecuteに送って、解析して文字合成した画像をcanvasに表示しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 |
# -*- coding: utf-8 -*- print("preparing...") import tkinter as tk import cv2 from PIL import Image,ImageTk import numpy as np root=tk.Tk() root.title("camera") root.geometry("224x224") root.resizable(width=False, height=False) canvas=tk.Canvas(root, width=224, height=224, bg="white") canvas.pack() #------------------------------------- import os os.environ['MPLCONFIGDIR'] = "/tmp" import json import matplotlib.pyplot as plt import matplotlib.image as mpimg import trt_pose.coco import math import traitlets import pickle import torch with open('preprocess/hand_pose.json', 'r') as f: hand_pose = json.load(f) topology = trt_pose.coco.coco_category_to_topology(hand_pose) num_parts = len(hand_pose['keypoints']) WIDTH = 224 HEIGHT = 224 data = torch.zeros((1, 3, HEIGHT, WIDTH)).cuda() print("weight loading...") OPTIMIZED_MODEL = 'model/hand_pose_resnet18_att_244_244_trt.pth' from torch2trt import TRTModule model_trt = TRTModule() model_trt.load_state_dict(torch.load(OPTIMIZED_MODEL)) from trt_pose.draw_objects import DrawObjects from trt_pose.parse_objects import ParseObjects parse_objects = ParseObjects(topology,cmap_threshold=0.15, link_threshold=0.15) draw_objects = DrawObjects(topology) import torchvision.transforms as transforms import PIL.Image mean = torch.Tensor([0.485, 0.456, 0.406]).cuda() std = torch.Tensor([0.229, 0.224, 0.225]).cuda() device = torch.device('cuda') def preprocess(image): global device device = torch.device('cuda') image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) image = PIL.Image.fromarray(image) image = transforms.functional.to_tensor(image).to(device) image.sub_(mean[:, None, None]).div_(std[:, None, None]) return image[None, ...] from preprocessdata import preprocessdata preprocessdata = preprocessdata(topology, num_parts) print("svm model loading...") from sklearn.pipeline import make_pipeline from sklearn.preprocessing import StandardScaler from sklearn.svm import SVC clf = make_pipeline(StandardScaler(), SVC(gamma='auto', kernel='rbf')) filename = 'svmmodel.sav' clf = pickle.load(open(filename, 'rb')) with open('preprocess/gesture.json', 'r') as f: gesture = json.load(f) gesture_type = gesture["classes"] def draw_joints(image, joints): count = 0 for i in joints: if i==[0,0]: count+=1 if count>= 7: return for i in joints: cv2.circle(image, (i[0],i[1]), 2, (0,0,255), 1) cv2.circle(image, (joints[0][0],joints[0][1]), 2, (255,0,255), 1) for i in hand_pose['skeleton']: if joints[i[0]-1][0]==0 or joints[i[1]-1][0] == 0: break cv2.line(image, (joints[i[0]-1][0],joints[i[0]-1][1]), (joints[i[1]-1][0],joints[i[1]-1][1]), (0,255,0), 1) def execute(change): image = change['new'] image = cv2.flip(image,1) data = preprocess(image) cmap, paf = model_trt(data) cmap, paf = cmap.detach().cpu(), paf.detach().cpu() counts, objects, peaks = parse_objects(cmap, paf) joints = preprocessdata.joints_inference(image, counts, objects, peaks) draw_joints(image, joints) dist_bn_joints = preprocessdata.find_distance(joints) gesture = clf.predict([dist_bn_joints,[0]*num_parts*num_parts]) gesture_joints = gesture[0] preprocessdata.prev_queue.append(gesture_joints) preprocessdata.prev_queue.pop(0) preprocessdata.print_label(image, preprocessdata.prev_queue, gesture_type) return image #------------------------------------- def capStart(): print('camera-start') try: global c, w, h, img c=cv2.VideoCapture(0) w, h= c.get(cv2.CAP_PROP_FRAME_WIDTH), c.get(cv2.CAP_PROP_FRAME_HEIGHT) print('width:'+str(w)+'px/height:'+str(h)+'px') except: import sys print("error") print(sys.exec_info()[0]) print(sys.exec_info()[1]) c.release() cv2.destroyAllWindows() def up():#change update global img ret, frame = c.read() if ret: frame = frame[0:720, 0:720] size = (224,224) frame = cv2.resize(frame,size) frame = execute({'new': frame}) img = ImageTk.PhotoImage(Image.fromarray(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))) canvas.create_image(0,0,image=img,anchor="nw") else: print("up failed") root.after(1,up) capStart() up() root.mainloop() |
ファイルを閉じて、コンテナも閉じます。
5.実行
ホスト側でxhostを実行しておきます。
|
1 |
sudo xhost si:localuser:root |
コンテナを起動
|
1 |
sudo docker start -i my_hand |
ディレクトリを移動して実行
|
1 2 3 |
cd /work/torch2trt/trt_pose/tasks/trt_pose_hand-main python3 pose_view.py |
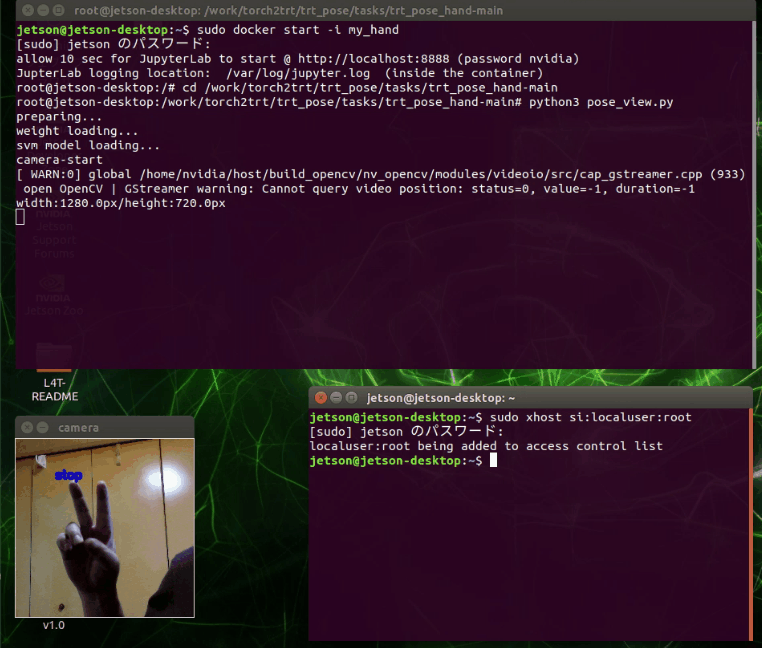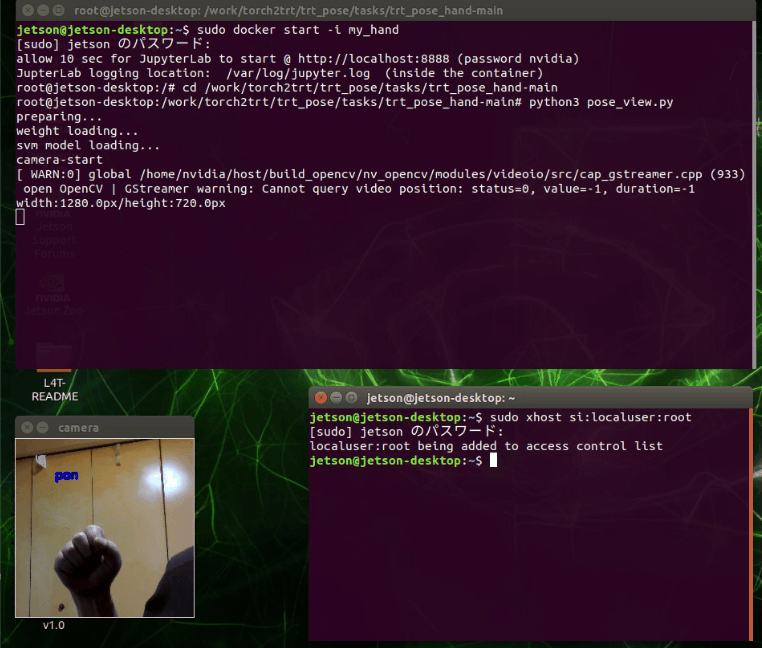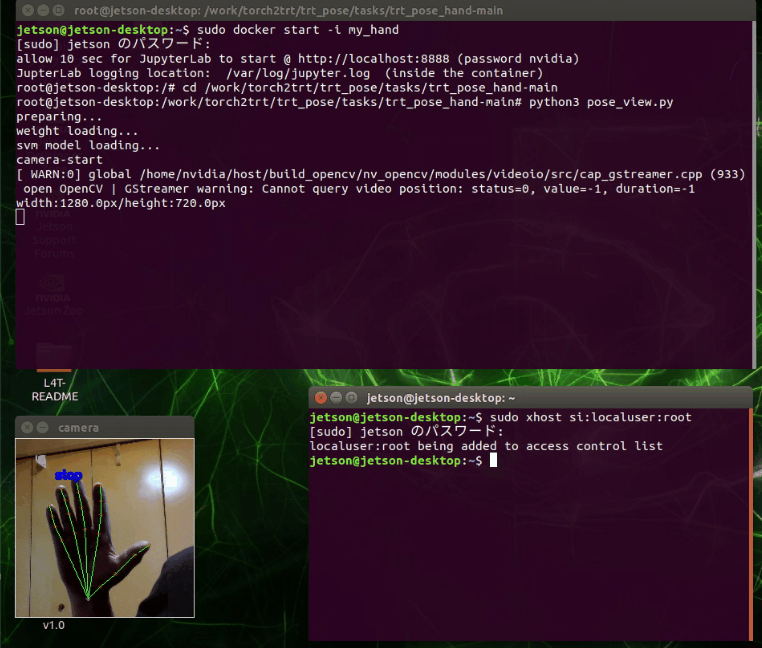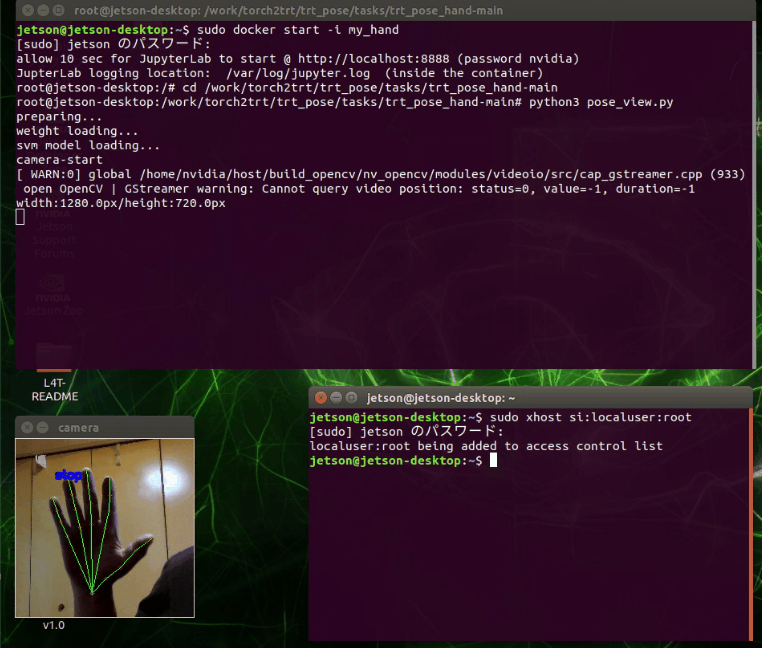
終了処理は入れていません、強制終了します。
ウィンドウを閉じて、Ctrl + Zで終了
文字表示などは、preprocessdata.pyを参照。
panやstopなどのクラスはpreprocess/gesture.json に記述されています。
OpenCVは日本語化していません。
日本語化などはラズベリーパイ3で顔認識のページの下段などを参考してみてください。
カメラ画像をOpenCVでキャプチャしてcanvasに転送している部分を別スレッドにすれば、コードもすっきりするかも….。 たいしてすっきりはしませんです。キャプチャ部分をスレッド化する場合はこんな感じ?、参考までに。
分類の検出がうまくいってません。自前で再学習が必要かもしれません。あるいは照明が暗かった?
スレッドを使った場合
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 |
# -*- Coding:utf-8 -*- print("preparing...") import threading import tkinter as tk import cv2 from PIL import Image,ImageTk import numpy as np import os os.environ['MPLCONFIGDIR'] = "/tmp" import json import matplotlib.pyplot as plt import matplotlib.image as mpimg import trt_pose.coco import math import traitlets import pickle import torch def view_image(): root=tk.Tk() root.title("camera") root.geometry("224x224") root.resizable(width=False, height=False) canvas=tk.Canvas(root, width=224, height=224, bg="white") canvas.pack() def capStart(): print('camera-start') try: global c, w, h, img c=cv2.VideoCapture(0) w, h= c.get(cv2.CAP_PROP_FRAME_WIDTH), c.get(cv2.CAP_PROP_FRAME_HEIGHT) print('width:'+str(w)+'px/height:'+str(h)+'px') except: import sys print("error") print(sys.exec_info()[0]) print(sys.exec_info()[1]) c.release() cv2.destroyAllWindows() def up():#change update global img ret, frame = c.read() if ret: frame = frame[0:720, 0:720] size = (224,224) frame = cv2.resize(frame,size) frame = execute({'new': frame}) img = ImageTk.PhotoImage(Image.fromarray(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))) canvas.create_image(0,0,image=img,anchor="nw") else: print("up failed") root.after(1,up) capStart() up() root.mainloop() #------------------------------------------------------------- with open('preprocess/hand_pose.json', 'r') as f: hand_pose = json.load(f) topology = trt_pose.coco.coco_category_to_topology(hand_pose) num_parts = len(hand_pose['keypoints']) WIDTH = 224 HEIGHT = 224 data = torch.zeros((1, 3, HEIGHT, WIDTH)).cuda() print("weight loading...") OPTIMIZED_MODEL = 'model/hand_pose_resnet18_att_244_244_trt.pth' from torch2trt import TRTModule model_trt = TRTModule() model_trt.load_state_dict(torch.load(OPTIMIZED_MODEL)) from trt_pose.draw_objects import DrawObjects from trt_pose.parse_objects import ParseObjects parse_objects = ParseObjects(topology,cmap_threshold=0.15, link_threshold=0.15) draw_objects = DrawObjects(topology) import torchvision.transforms as transforms import PIL.Image mean = torch.Tensor([0.485, 0.456, 0.406]).cuda() std = torch.Tensor([0.229, 0.224, 0.225]).cuda() device = torch.device('cuda') def preprocess(image): global device device = torch.device('cuda') image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) image = PIL.Image.fromarray(image) image = transforms.functional.to_tensor(image).to(device) image.sub_(mean[:, None, None]).div_(std[:, None, None]) return image[None, ...] from preprocessdata import preprocessdata preprocessdata = preprocessdata(topology, num_parts) print("svm model loading...") from sklearn.pipeline import make_pipeline from sklearn.preprocessing import StandardScaler from sklearn.svm import SVC clf = make_pipeline(StandardScaler(), SVC(gamma='auto', kernel='rbf')) filename = 'svmmodel.sav' clf = pickle.load(open(filename, 'rb')) with open('preprocess/gesture.json', 'r') as f: gesture = json.load(f) gesture_type = gesture["classes"] def draw_joints(image, joints): count = 0 for i in joints: if i==[0,0]: count+=1 if count>= 7: return for i in joints: cv2.circle(image, (i[0],i[1]), 2, (0,0,255), 1) cv2.circle(image, (joints[0][0],joints[0][1]), 2, (255,0,255), 1) for i in hand_pose['skeleton']: if joints[i[0]-1][0]==0 or joints[i[1]-1][0] == 0: break cv2.line(image, (joints[i[0]-1][0],joints[i[0]-1][1]), (joints[i[1]-1][0],joints[i[1]-1][1]), (0,255,0), 1) def execute(change): image = change['new'] image = cv2.flip(image,1) data = preprocess(image) cmap, paf = model_trt(data) cmap, paf = cmap.detach().cpu(), paf.detach().cpu() counts, objects, peaks = parse_objects(cmap, paf) joints = preprocessdata.joints_inference(image, counts, objects, peaks) draw_joints(image, joints) dist_bn_joints = preprocessdata.find_distance(joints) gesture = clf.predict([dist_bn_joints,[0]*num_parts*num_parts]) gesture_joints = gesture[0] preprocessdata.prev_queue.append(gesture_joints) preprocessdata.prev_queue.pop(0) preprocessdata.print_label(image, preprocessdata.prev_queue, gesture_type) return image #------------------------------------------------------------- thread1 = threading.Thread(target=view_image) thread1.start() |
Leave a Reply