
前回やったラズパイ3+Julius で音声認識の続編
前回ではオフラインでの日本語音声認識はJulius一択と言ってましたが、ここにきてVoskという選択肢が増えました。やってみます。
今回はVoskを使い、インストールしてローカル・オフラインで稼働させてみます。
ラズパイは5(8GB)を使用。
OSイメージはRaspberry Pi OS Desktop (64-bit)Bookworm
注:Lite ではうまくいった試しがないです。使っているPython のALSA系のライブラリが違う?

まず仮想環境を作成。
|
1 2 3 |
python3 -m venv venv_vosk source venv_vosk/bin/activate |
pipをアップグレードしてモジュール・ライブラリをインストールします。
|
1 2 3 4 |
pip install --upgrade pip pip install vosk pip install pyaudio |
pyaudioのインストールで以下のようなエラーになった場合
ERROR: Failed building wheel for pyaudio
ERROR: Could not build wheels for pyaudio, which is required to install pyproject.toml-based projects
少し上の行で以下のようなメッセージを見つけた時
「fatal error: ‘portaudio.h’ file not found」の場合
>sudo apt-get install portaudio19-dev
「fatal error: Python.h: そのようなファイルやディレクトリはありません」の場合
>sudo apt install python3-dev
で、
>pip install pyaudio
作業環境を作成。
|
1 2 |
mkdir ~/vosk cd ~/vosk |
日本語モデルのダウンロード・解凍
2パターンあります。軽量な48MBと精度の高い1GB、1GBは精度が高い分50MBに比べてタイムラグは若干長めです。
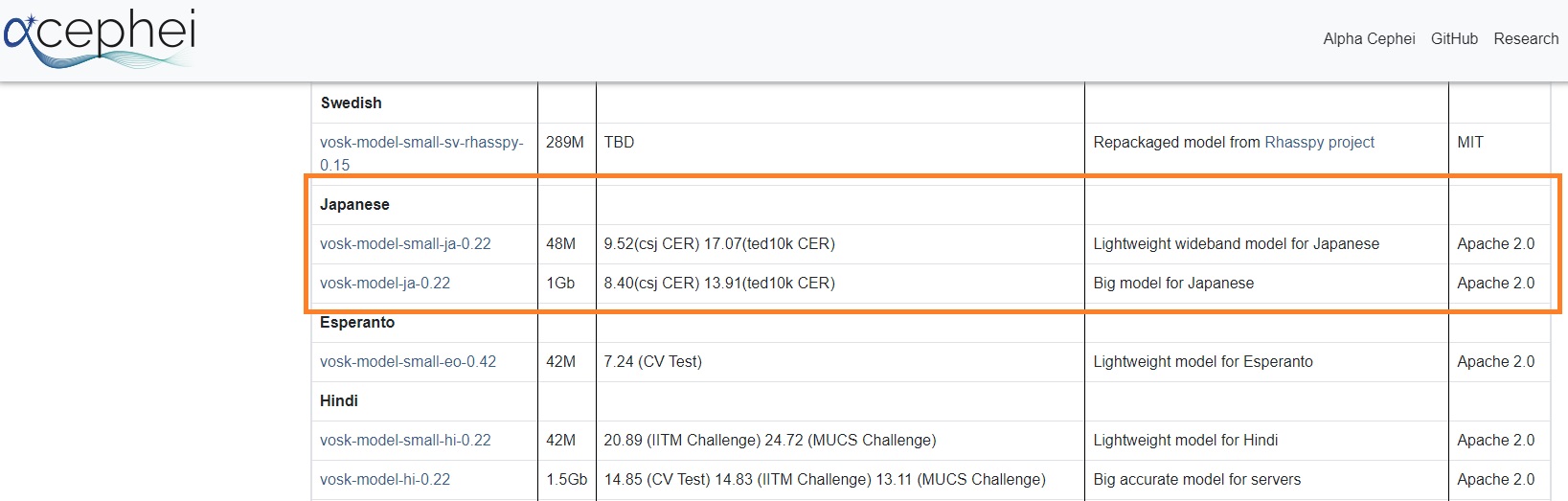
48MBの場合
|
1 2 3 |
wget https://alphacephei.com/vosk/models/vosk-model-small-ja-0.22.zip unzip vosk-model-small-ja-0.22.zip rm vosk-model-small-ja-0.22.zip |
1GBの場合
|
1 2 3 |
wget https://alphacephei.com/vosk/models/vosk-model-ja-0.22.zip unzip vosk-model-ja-0.22.zip rm vosk-model-ja-0.22.zip |
実行コードのサンプル
>sudo nano listener.py
モデルのパスは1GB版(vosk-model-ja-0.22)で設定しています、48MBの場合は vosk-model-small-ja-0.22 に変更してください。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
import json from pathlib import Path from vosk import Model, KaldiRecognizer import pyaudio model = Model(str(Path("vosk-model-ja-0.22").resolve())) # MIC initilize recognizer = KaldiRecognizer(model, 16000) mic = pyaudio.PyAudio() # voskの設定 def engine(): stream = mic.open(format=pyaudio.paInt16, channels=1, rate=16000, input=True, frames_per_buffer=8192) # ストリーミングデータを読み取る while True: stream.start_stream() try: data = stream.read(4096) if recognizer.AcceptWaveform(data): result = recognizer.Result() # jsonに変換 response_json = json.loads(result) print("SYSTEM: ", response_json) response = response_json["text"].replace(" ","") return response else: pass except OSError: pass listening = True # listeningをループして音声認識 def bot_listen_hear(): global listening # listeningループ while listening: response = engine() print("SYSTEM: ","-"*22, "なにか話しかけてください","-"*22) # 空白の場合はループを途中で抜ける if response.strip() == "": continue else: pass return response if __name__ == "__main__": try: while True: # bot_listen_hear関数を実施してレスポンスを得る user_input = bot_listen_hear() print("USER: ",user_input) except KeyboardInterrupt: # ctrl+c でループ終了 print("SYSTEM: Vosk終了") |
>python3 listener.py
Ctrl-C で終了します。
サウンド・ライブラリにpyaudioを使っているので読み込み時に盛大にWarningやErrorが表示されますが実行には問題ないので無視してください。
最初に「えーと」という音声が認識されていますが、これは無音のノイズ(?)を拾ったものです。
ラズパイ5でもタイムラグは1~2秒くらいあります。
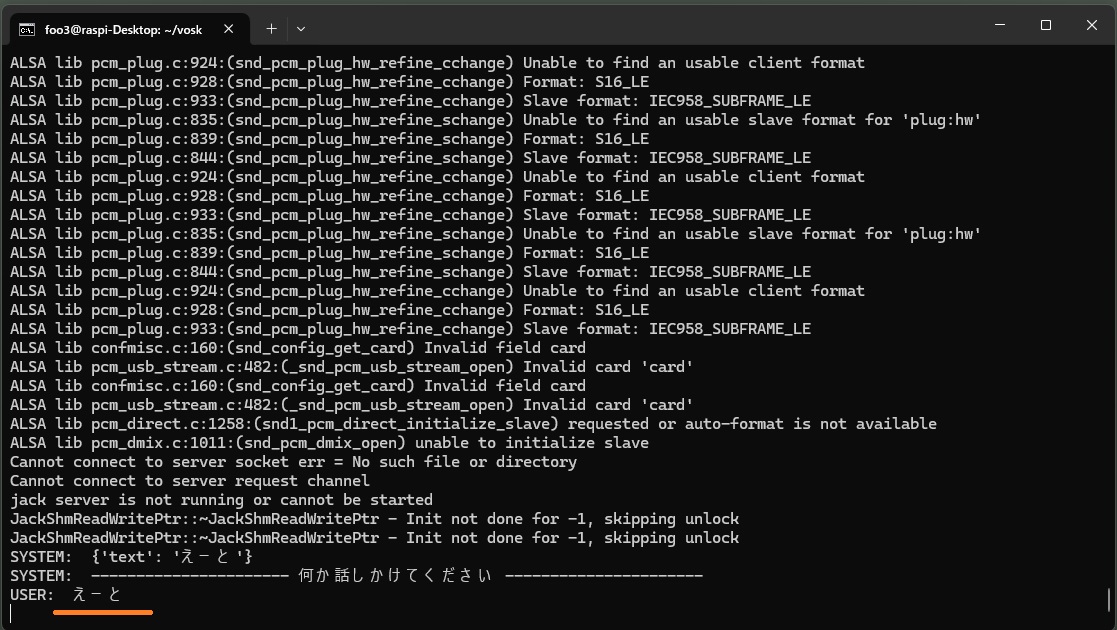
1GB版はかなり認識精度は高いです。
基本的に起動後拾った音はすべて認識し続けていますが、ウェイクワードを設定することで途中で何かの作業をさせることができます。AlexaやSiri のような掛け声のようなものです。ご自分の声で認識精度の高いものを探すといいです。
では仮想環境を抜けます。
|
1 |
deactivate |
起動時実行
source venv_vosk/bin/activate
cd ~/vosk
python3 listener.py
Appendix
音声合成に関しては以下を参照
ラズパイで音声合成(2)AquestTalk・VoiceVox
Appendix2
voskをLLMなどでの推論実行時のウェイクワードの検出器として使うというのが現実的?
ウェイクワードに関してはこれも参照
Leave a Reply