
ラズパイ単体で顔認識をする場合
ここではストリーミングしたカメラ画像を使って、ネットワーク越しに顔認識してみます。
こんな感じ。
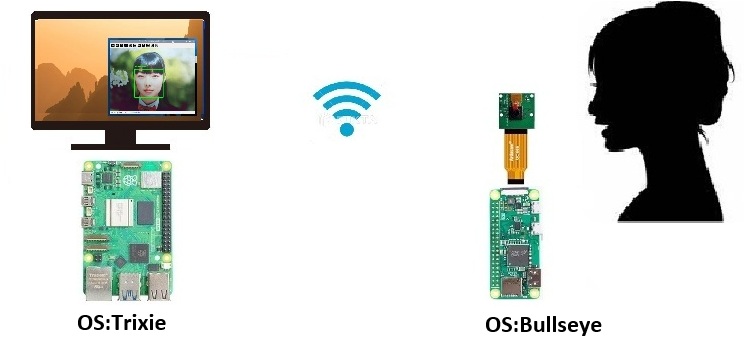
ストリーミング側
CSIカメラモジュール + ラズパイZero 2 W

ストリーミングは軽量なMjpg-Streamerを使います。
ラズパイ Zero W とCSIカメラモジュールでライブ・ストリーミング(メモ)参照
また、カメラとZeroのハウジングには100均のダミーカメラがよさげです。これを使えばダミーカメラが本物の監視カメラになります。ただしZeroの電源は外部から取る必要があります。カメラには単三電池3個用の電池ボックスが取られていますが、Zeroは5v起動です。5vの昇圧回路を挟んで使ってみましたが起動できませんでした。乾電池ボックスを1個増やして(3+1)x 1.5 vならOKでした。工作には工夫が必要です。ただ監視カメラを乾電池駆動させること自体がまちがっているような….。
顔認識側
(改-1)で使ったラズパイ5

ストリーミング側
Mjpg-Streamer はラズパイで使う場合、最新のOSでは動かないようです。
で、Zero 2 W のOSにはBullseye Lite を使います。
以下にOLDバージョンのイメージがあります。
2022-01-28-raspios-bullseye-armhf-lite.zipをダウンロードします。
また、このイメージを焼く場合、最新のRaspberry Pi OS Imager を使うとユーザやSSHの設定ができません。
少し古いバージョン1.8.5 のImagerを使ってUse custom で焼くとユーザやSSHの設定もできます。
まずBullseyeが焼けたらImagerで設定したユーザー名とパスワードでログインします。
以下実行
|
1 |
sudo apt update |
Lite版の各種設定画面を起動します。
|
1 |
sudo raspi-config |
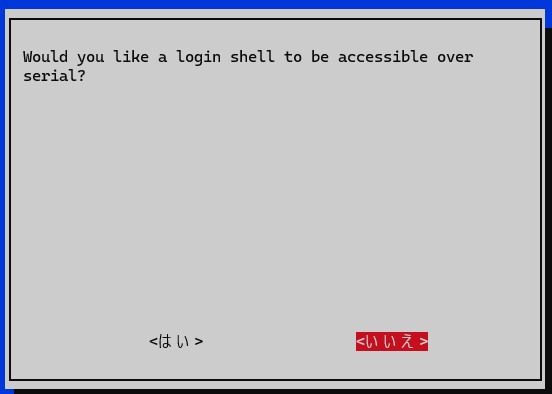
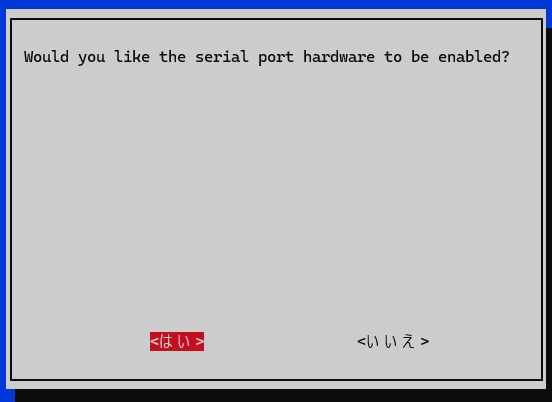
Interface Optionsで以下を設定
Localisation Optionsで以下を設定
最後にFinishしてrebootします。
次にIPアドレスを固定します。
|
1 |
sudo nano /etc/dhcpcd.conf |
最後尾に以下を追加
interface wlan0
static ip_address=<IPアドレス>
static routers=192.168.0.1
static domain_name_servers=<DNSのアドレス>
最後にrebootします。
ついでにSAMBAも設定しておきましょう。
|
1 2 |
sudo apt update sudo apt install samba |
共有用のディレクトリを作っておきます。
|
1 |
sudo mkdir ~/Public |
編集
|
1 |
sudo nano /etc/samba/smb.conf |
最後尾に以下を追加
[Public]
path = /home/<ユーザー名>/Public
read only = no
guest ok = yes
public = yes
writable = Yes
browsable = yes
force user = <ユーザー名>
directory mode = 0774
create mode = 0774
パスワード設定
|
1 |
sudo pdbedit -a <ユーザー名> |
サービスを起動
|
1 2 |
sudo service smbd restart sudo service nmbd restart |
Mjpg-streamerをインストール
ツールやライブラリをインストール
|
1 2 3 |
sudo apt update sudo apt install -y git cmake libjpeg-dev |
ユーザールートに戻って Mjpg-streamerをクローンしておきます。
|
1 2 3 |
cd ~/ git clone https://github.com/neuralassembly/mjpg-streamer.git |
ビルド実行
|
1 2 3 4 5 |
cd mjpg-streamer/mjpg-streamer-experimental make sudo make install |
カメラの番号をチェック
CSIカメラが装着されていれば0番のvideoにアサインされていると思います。
|
1 |
ls /dev/video* |
ポート:8080でキャストしてみます。
|
1 |
~/mjpg-streamer/mjpg-streamer-experimental/mjpg_streamer -i "./input_uvc.so -d /dev/video0 -rot 0 -r 640x480 -f 10 -y -n" -o "./output_http.so -w ./www -p 8080" |
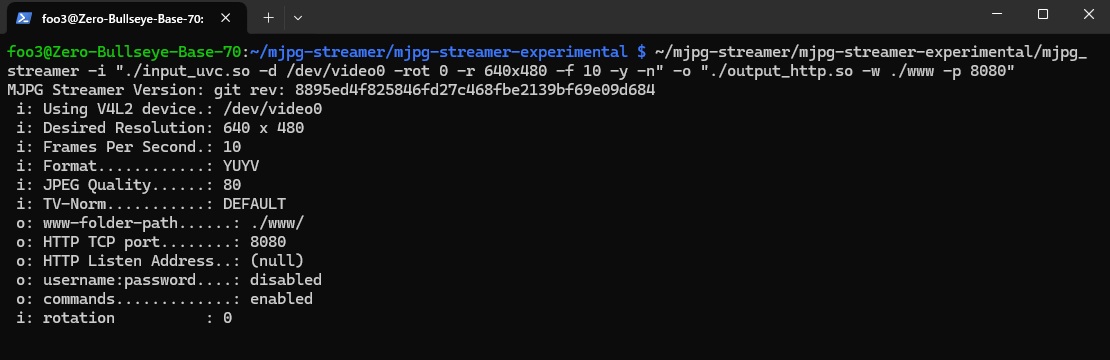
ストリームされている画像を外部ブラウザーで見てみます。
http://<IPアドレス>:8080
自動起動用のスクリプトを作っておきます。
|
1 2 3 |
cd ~/ sudo nano stream.sh |
シェルスクリプトコード
|
1 2 3 4 5 |
#!/bin/bash cd /home/foo3/mjpg-streamer/mjpg-streamer-experimental ./mjpg_streamer -i "./input_uvc.so -d /dev/video0 -rot 0 -r 640x480 -f 10 -y -n" -o "./output_http.so -w ./www -p 8080" |
カメラの傾きはrot (回転) オプションで設定(0 ~ 360)。
/etc/rc.localに以下を追加して再起動
|
1 |
sh /home/foo3/stream.sh |
顔認識側
ストリームされている画像をキャプチャして、顔認識(識別)をやってみます。
基本的な動作は(改-1)でやった単体用のコードを少し変更するだけです。仮想環境を作ってface_recognitionをインストールしておきます。
単体動作の場合のコードはfaceディレクトリにあるfacial_recognition.pyです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 |
#! /usr/bin/python """ 2025/03/08 Bullseyeへ変換 終了はesc 2025/03/11 画像サイズをconfigで設定 2025/03/12 toleranceパラメータを設定 2025/03/14 ・multiprocessingによる高速化 倍近いスピードアップした マルチプロセスを使う関係上 if __name__ == "__main__":に プログラムを書く必要があり、改造がしにくい感がある ・検出する顔の大きさを設定できるようにする これにより小さい顔は検出しない ひとりで大きく映る場合はちょうど良い 2025/03/25 日本人の精度を上げるため田口モデルを適用 データ置き場を整理 処理軽減のパラメータをconfig化 2025/03/30 モデルを選択できるようにした 2025/03/31 コメント整理 2025/04/17 プログラム名を顔識別 face_recognitionとした 2025/07/25 カメラタイプ対応 *1 2025/09/08 取説とプログラム名が違っているので、facial_recognitionとした facial_recognition.py 01 """ import config # tolerance_parameterの取得 精度調整用 tolerance_para = config.tolerance_parameter() print("tolerance_parameter=",tolerance_para) print("ウォームアップ中ちょっと待って") print() import dlib import cv2 import time from imutils.video import FPS import pickle import multiprocessing from picamera2 import Picamera2 from scipy.spatial.distance import euclidean # Euclidean distanceを使用 # *1 from libcamera import controls # 設定の取得 # カメラタイプの取り込み *1 camera_type = config.camera_type() # カメラから取り込む画像の大きさの設定 camera_width_x, camera_width_y = config.camera_width() # 処理用の画像の大きさの設定 disp_width_x, disp_width_y = config.disp_width() # 現在使っていない # 検出する顔の最小大きさ face_size_para = config.face_size() # 必要な連続検出回数 necessary_count = config.necessary_count() # 現在使っていない # 処理性能軽減のための画像サイズ縮小 speed_size = config.speed_size() # Dlibの顔検出器 face_detector = dlib.get_frontal_face_detector() # model_choice = config.model_choice() # 汎用モデル face_rec_model_path = "./face_dat/dlib_face_recognition_resnet_model_v1.dat" # 田口モデル if model_choice == 1: face_rec_model_path = "./face_dat/taguchi_face_recognition_resnet_model_v1.dat" face_rec_model = dlib.face_recognition_model_v1(face_rec_model_path) # 顔検出器 特徴量を取得 shape_predictor = dlib.shape_predictor("./face_dat/shape_predictor_68_face_landmarks.dat") # 初期化 currentname = "unknown" # encodingsP = "./face_dat/encodings_taguchi.pickle" encodingsP = "./face_dat/encodings.pickle" print("[INFO] loading encodings + face detector...") # pickleの読み込み data = pickle.loads(open(encodingsP, "rb").read()) def process_faces(rgb_frame, gray_frame, tolerance, face_size): """顔検出と顔認識を並列処理""" # 顔検出 faces = face_detector(gray_frame, 1) encodings = [] names = [] for face in faces: # 顔の領域の幅と高さを取得 width = face.right() - face.left() height = face.bottom() - face.top() # 最小顔サイズより小さい顔を無視 if width < face_size or height < face_size: continue # 顔を検出 shape = shape_predictor(gray_frame, face) encoding = face_rec_model.compute_face_descriptor(rgb_frame, shape) encodings.append(encoding) # 顔識別 distances = [] for known_encoding in data["encodings"]: # Euclidean距離を計算 distance = euclidean(encoding, known_encoding) distances.append(distance) # 最も近い顔を選択 min_distance = min(distances) if min_distance < tolerance: name = data["names"][distances.index(min_distance)] else: name = "Unknown" names.append(name) return faces, names if __name__ == "__main__": # カメラ設定 picam2 = Picamera2() cam_config = picam2.create_preview_configuration(main={"size": (camera_width_x, camera_width_y), "format": "RGB888"}) picam2.configure(cam_config) if camera_type == 3: # オートフォーカスを有効にする *1 picam2.set_controls({"AfMode": controls.AfModeEnum.Continuous}) picam2.start() time.sleep(2.0) # Camera warm-up # FPS計測開始 fps = FPS().start() # 並列処理用プールを作成 num_processes = multiprocessing.cpu_count() pool = multiprocessing.Pool(processes=num_processes) # 処理負荷を下げるため縮小 # デフォルトでは、640*480の画像だが、処理時にリサイズして処理 # 小さい値にするとスピードアップになるが、やりすぎると精度が落ちる proces_width_x = int(640 * speed_size) proces_width_y = int(480 * speed_size) # face_sizeとの関係があるので調整 face_size_para = face_size_para * speed_size while True: frame = picam2.capture_array() # small_frame = cv2.resize(frame, (320, 240)) # 処理負荷を下げるため縮小 small_frame = cv2.resize(frame, (proces_width_x, proces_width_y)) # 処理負荷を下げるため縮小 gray = cv2.cvtColor(small_frame, cv2.COLOR_BGR2GRAY) rgb = cv2.cvtColor(small_frame, cv2.COLOR_BGR2RGB) # 並列処理で顔を検出・認識 result_async = pool.apply_async(process_faces, (rgb, gray, tolerance_para, face_size_para)) faces, names = result_async.get() for (face, name) in zip(faces, names): (top, right, bottom, left) = (face.top(), face.right(), face.bottom(), face.left()) # 座標を元のサイズにスケールアップ # top, right, bottom, left = [int(val * (camera_width_x / 320)) for val in [top, right, bottom, left]] top, right, bottom, left = [int(val * (camera_width_x / proces_width_x)) for val in [top, right, bottom, left]] y = top - 15 if top - 15 > 15 else top + 15 if name != "Unknown":# 名前が判別できた時は 緑の枠 cv2.rectangle(frame, (left, top), (right, bottom), (0, 255, 0), 4) cv2.putText(frame, name, (left, y), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 255, 0), 2) else: # Unknown の場合は 赤の枠 cv2.rectangle(frame, (left, top), (right, bottom), (0, 0, 225), 6) cv2.putText(frame, name, (left, y), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 0, 255), 2) if name != currentname: currentname = name print(currentname) """ """ """ """ """ """ """ """ """ """ """ """ """ ここで、名前を確定した場合の処理を入れることが可能 """ if name == currentname and name != "Unknown":# 2回 連続して同じ名前ならokとプリントする print("ok") """ """ """ """ """ """ """ """ """ """ """ """ """ """ """ """ """ """ """ """ """ """ """ """ cv2.imshow("Facial Recognition is Running", frame) # q or ESCキーが押されたら終了 key = cv2.waitKey(1) & 0xFF if key == ord("q") or key == 27: break # 'p' キーが押されたら画像保存 if key == ord("p"): cv2.imwrite("face_" + name +".jpg", frame) fps.update() # FPS計測終了 fps.stop() print("[INFO] elapsed time: {:.2f}".format(fps.elapsed())) print("[INFO] approx. FPS: {:.2f}".format(fps.fps())) cv2.destroyAllWindows() pool.close() pool.join() |
ここにはCSIカメラモジュールからの画像を得るのに以下のコードを使っています。
picam2 = Picamera2()
さらに、ここからフレームを切り出すのは以下のコードです。
frame = picam2.capture_array()
変更をかけるのはこの2か所ということになります。
こんな感じです。
オリジナルのコメントは外していますが、改変部分のみStreamingというコメントを入れています。
IPアドレスの部分は各自の環境で書き換えてください。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 |
#! /usr/bin/python import config tolerance_para = config.tolerance_parameter() print("tolerance_parameter=",tolerance_para) print("ウォームアップ中ちょっと待って") print() import dlib import cv2 import time from imutils.video import FPS import pickle import multiprocessing from scipy.spatial.distance import euclidean camera_width_x, camera_width_y = config.camera_width() disp_width_x, disp_width_y = config.disp_width() face_size_para = config.face_size() necessary_count = config.necessary_count() speed_size = config.speed_size() face_detector = dlib.get_frontal_face_detector() model_choice = config.model_choice() face_rec_model_path = "./face_dat/dlib_face_recognition_resnet_model_v1.dat" if model_choice == 1: face_rec_model_path = "./face_dat/taguchi_face_recognition_resnet_model_v1.dat" face_rec_model = dlib.face_recognition_model_v1(face_rec_model_path) shape_predictor = dlib.shape_predictor("./face_dat/shape_predictor_68_face_landmarks.dat") currentname = "unknown" encodingsP = "./face_dat/encodings.pickle" print("[INFO] loading encodings + face detector...") data = pickle.loads(open(encodingsP, "rb").read()) def process_faces(rgb_frame, gray_frame, tolerance, face_size): faces = face_detector(gray_frame, 1) encodings = [] names = [] for face in faces: width = face.right() - face.left() height = face.bottom() - face.top() if width < face_size or height < face_size: continue shape = shape_predictor(gray_frame, face) encoding = face_rec_model.compute_face_descriptor(rgb_frame, shape) encodings.append(encoding) distances = [] for known_encoding in data["encodings"]: distance = euclidean(encoding, known_encoding) distances.append(distance) min_distance = min(distances) if min_distance < tolerance: name = data["names"][distances.index(min_distance)] else: name = "Unknown" names.append(name) return faces, names if __name__ == "__main__": # Streamingされた画像をキャプチャ URL = "http://<IPアドレス>:8080/?action=stream" s_cap = cv2.VideoCapture(URL) time.sleep(2.0) fps = FPS().start() num_processes = multiprocessing.cpu_count() pool = multiprocessing.Pool(processes=num_processes) proces_width_x = int(640 * speed_size) proces_width_y = int(480 * speed_size) face_size_para = face_size_para * speed_size while True: # Streamingされた画像をフレームに切り出す ret,frame = s_cap.read() # 時計回りに90度回転 #frame = cv2.rotate(frame,cv2.ROTATE_90_CLOCKWISE) # 180度回転 #frame = cv2.rotate(frame,cv2.ROTATE_180) # 反時計回りに90度回転 #frame = cv2.rotate(frame,cv2.ROTATE_90_COUNTERCLOCKWISE) small_frame = cv2.resize(frame, (proces_width_x, proces_width_y)) gray = cv2.cvtColor(small_frame, cv2.COLOR_BGR2GRAY) rgb = cv2.cvtColor(small_frame, cv2.COLOR_BGR2RGB) result_async = pool.apply_async(process_faces, (rgb, gray, tolerance_para, face_size_para)) faces, names = result_async.get() for (face, name) in zip(faces, names): (top, right, bottom, left) = (face.top(), face.right(), face.bottom(), face.left()) top, right, bottom, left = [int(val * (camera_width_x / proces_width_x)) for val in [top, right, bottom, left]] y = top - 15 if top - 15 > 15 else top + 15 if name != "Unknown": cv2.rectangle(frame, (left, top), (right, bottom), (0, 255, 0), 4) cv2.putText(frame, name, (left, y), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 255, 0), 2) else: cv2.rectangle(frame, (left, top), (right, bottom), (0, 0, 225), 6) cv2.putText(frame, name, (left, y), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 0, 255), 2) if name != currentname: currentname = name print(currentname) if name == currentname and name != "Unknown": print("ok") cv2.imshow("Facial Recognition is Running", frame) key = cv2.waitKey(1) & 0xFF if key == ord("q") or key == 27: break if key == ord("p"): cv2.imwrite("face_" + name +".jpg", frame) fps.update() fps.stop() print("[INFO] elapsed time: {:.2f}".format(fps.elapsed())) print("[INFO] approx. FPS: {:.2f}".format(fps.fps())) cv2.destroyAllWindows() pool.close() pool.join() |
実行手順は(改-1)と同じです。
source V_face/bin/activate
cd face
python3 facial_recognition.py
Appendix
ストリーミング・サーバーを立てる場合の問題点
Mjpg-streamerやRTSPサーバーで問題になるのはセキュリティです。
要はストリームされているコンテンツが暗号化されていないのです。で、暗号化対策が未だの場合、特に今回のような場合エクステリアで使うのはいいとして、インテリアで使わないようにしましょう。
つまり見守りやペット監視などは止めときましょう….ということですね。
暗号化が必要な場合、以下の方のブログを参考にしてみてはいかがでしょう。
プロキシサーバーを立てて通信を暗号化されています。
ただし途中で未知のディレクトリーなどが突然登場するので、リンクされているページは見ておいたほうがいいです。
Leave a Reply