
llamafile を使って言語モデル(LLM/SLM/LMM)を実行してみましょう。
LLM :大規模言語モデル
SLM :小規模言語モデル
LMM :大規模マルチモーダルモデル
今まで言語モデルを使う場合、llama.cpp やllama-cpp-python はプラットフォームに合わせてビルド・インストールしていましたが、llamafile はそういう作業が必要ありません。Java のようにプラットフォームを気にせずにバイナリをダウンロードすれば、そのまま使えます。
また、llamafileは様々な言語モデルをオフラインで実行するために作られたものです。
プラットフォームはLinux(Ubuntu,Debian)、Windows、Mac、FreeBSD、OpenBSD、NetBSD に対応しています。
これはllama.cpp にCosmopolitan LibC を適応したもので、単体で言語モデルを呼び出して使ったり、モデルとllamafileを統合することでローカルでもそのまま推論実行したりできます。
これは「大規模言語モデルを単一ファイルで実行する」という風に表現されています。
ちょっとイメージしづらいところがありますが、使ってみれば「ああ、そいうこと!」と納得できます。
さらにどうしたことか、llamafile はllama.cpp単体 より高速だったりします。
やってみましょう。
Windows(AMD64)
こういう環境で試してみました。
win11 Pro 22H2
Core(TM) i5-4590T CPU @ 2.00GHz
RAM 8.00 GB
llamafile公式を参照します。
まずllamafile から言語モデルを読み込んで推論実行してみます(Using llamafile with external weights)。
コマンドプロンプトターミナルを開いて実行します(PowerShellターミナルでexeを実行する場合、先頭に.\を置きます)。
適当なフォルダーを作ってそこで作業します。
|
1 2 3 |
mkdir temp cd temp |
llamafile-0.6をダウンロードして、Windows なのでllamafile.exe にリネームしておきます(30MB程度の実行ファイルです)。
LLMファイルはmistral-7b-instruct-v0.1 の4bit量子化版をダウンロードしてmistral.ggufにリネームしておきます。
|
1 2 3 |
curl -L -o llamafile.exe https://github.com/Mozilla-Ocho/llamafile/releases/download/0.6/llamafile-0.6 curl -L -o mistral.gguf https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.1-GGUF/resolve/main/mistral-7b-instruct-v0.1.Q4_K_M.gguf |
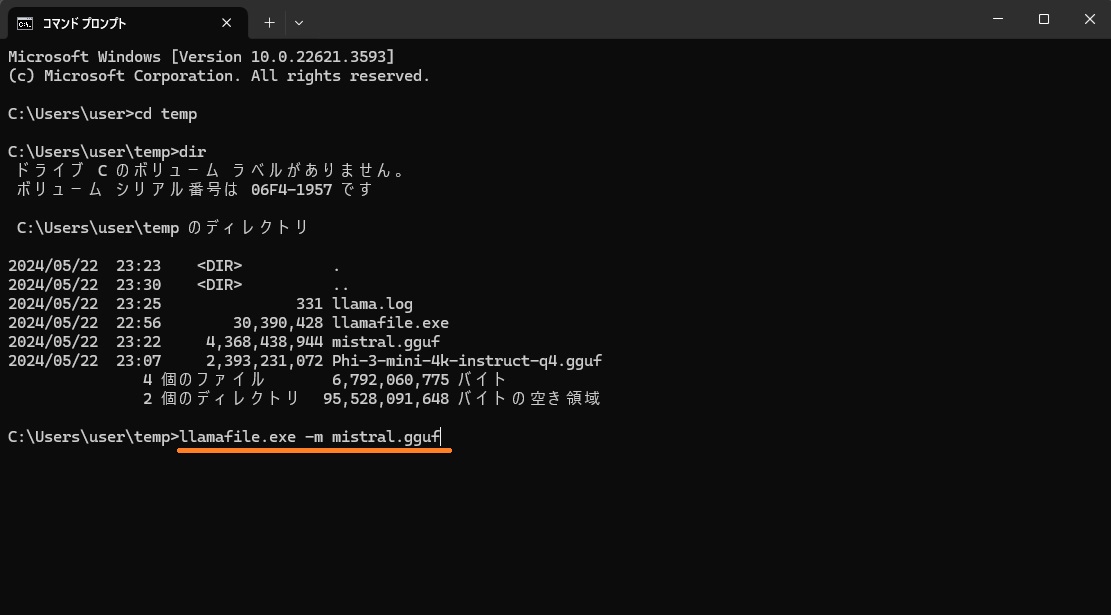
で、実行(mオプションで外部からモデルを読んできます)。
>llamafile.exe -m mistral.gguf
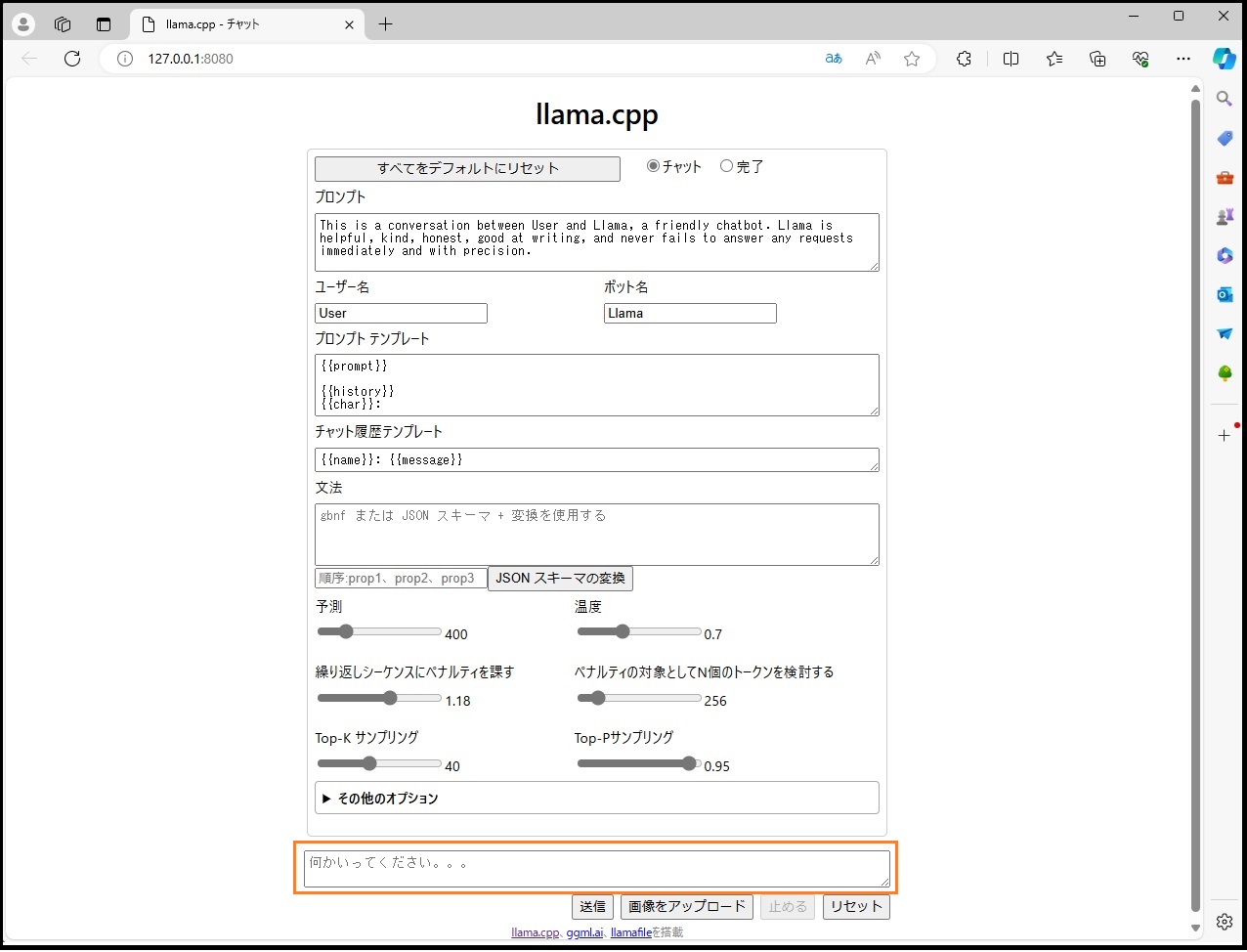
ブラウザが開いてllama.cppの画面になりました。
自動でブラウザが開かない場合はhttp://127.0.0.1:8080/にアクセスしてみてください。
では、次に言語モデルとllamafileを統合したものを使ってみます。
<モデル名>.llamafile という名称になっています。
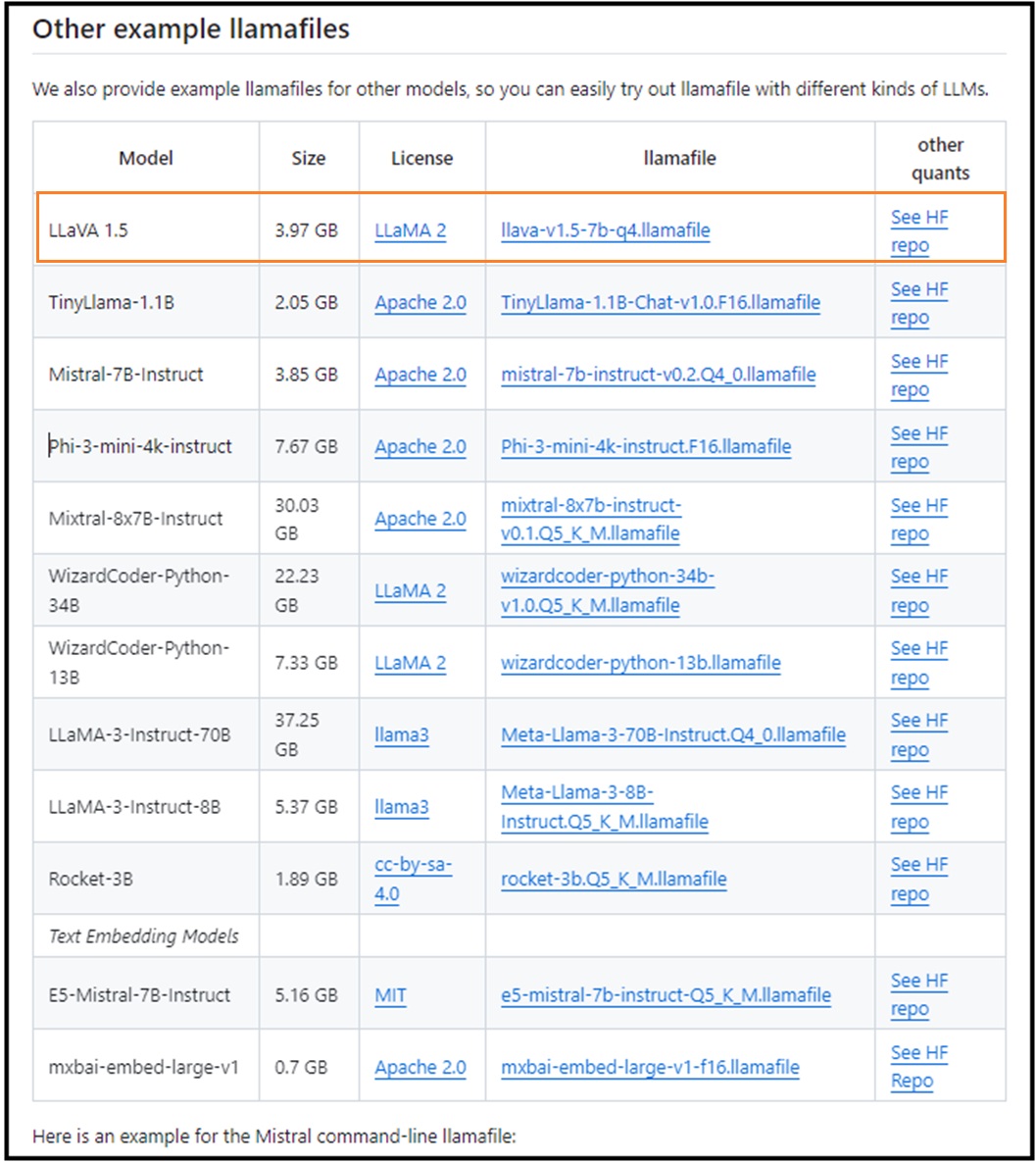
llamafile公式のページからダウンロードできます。ただWindows の場合4GBの壁があるようで、このサイズ以下のファイルに限定されます。4GB以上のllamafileについては下記のラズパイ5の項を参照してください。
LLaVA-1.5という大規模マルチモーダルモデル(LMM)の4bit量子化版のllamafileがギリ使えますね。
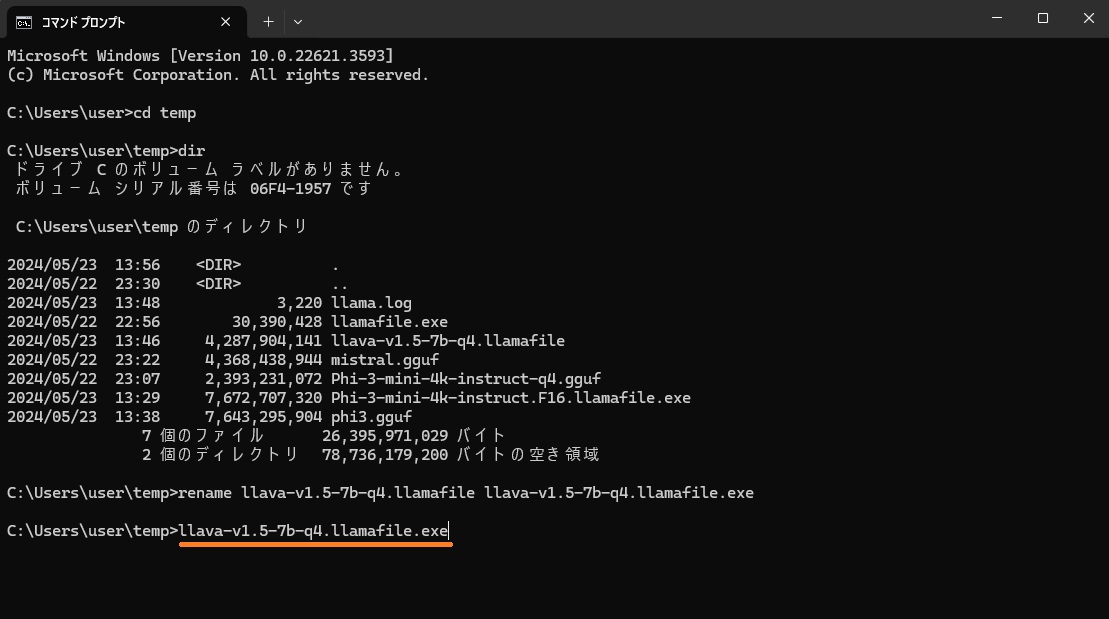
ダウンロードして、Windowsなので拡張子にexeを付けて実行してみます。
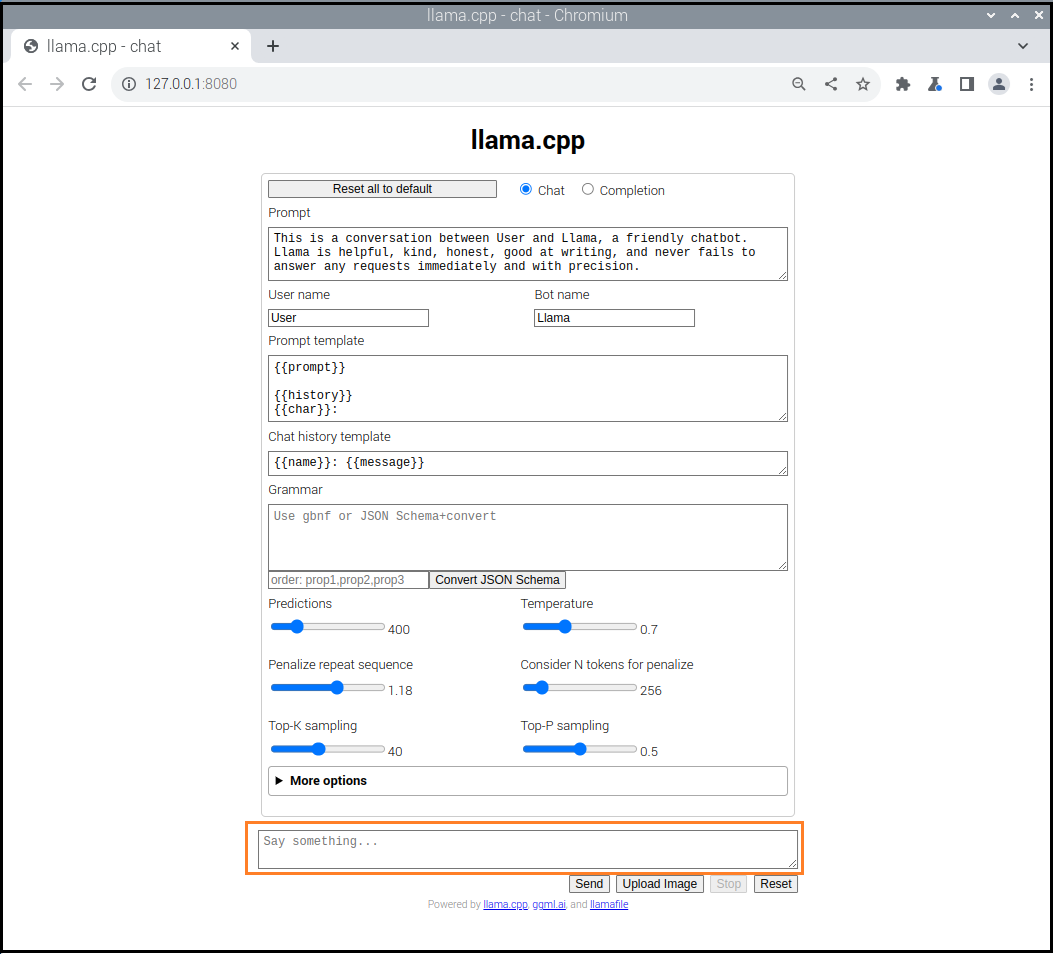
ブラウザーが起動して入力画面になります。
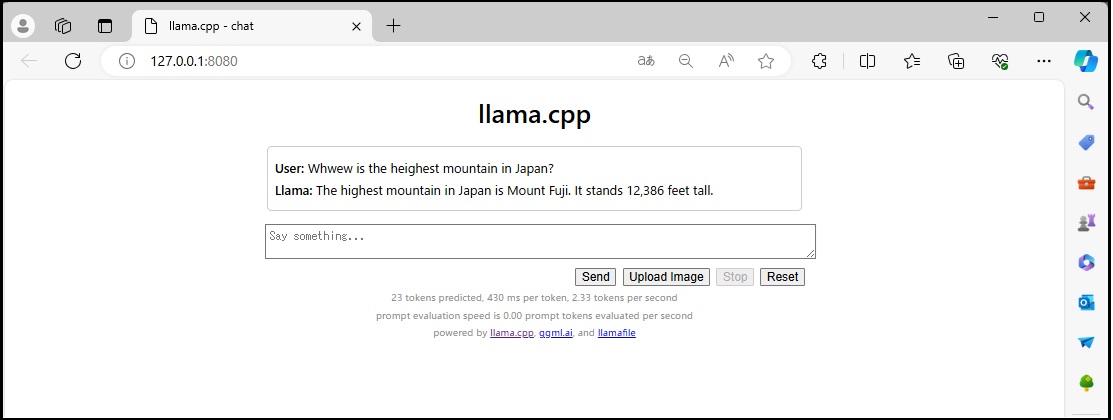
プロンプトは「Where is the heighest mountain in Japan ?」でやってみます。
Core(TM) i5-4590T CPU @ 2.00GHzのマシンで20秒くらいで結果が返ってきました。
LLaVA-1.5というモデルは画像と言語のマルチモーダルなので、画像も認識できます。
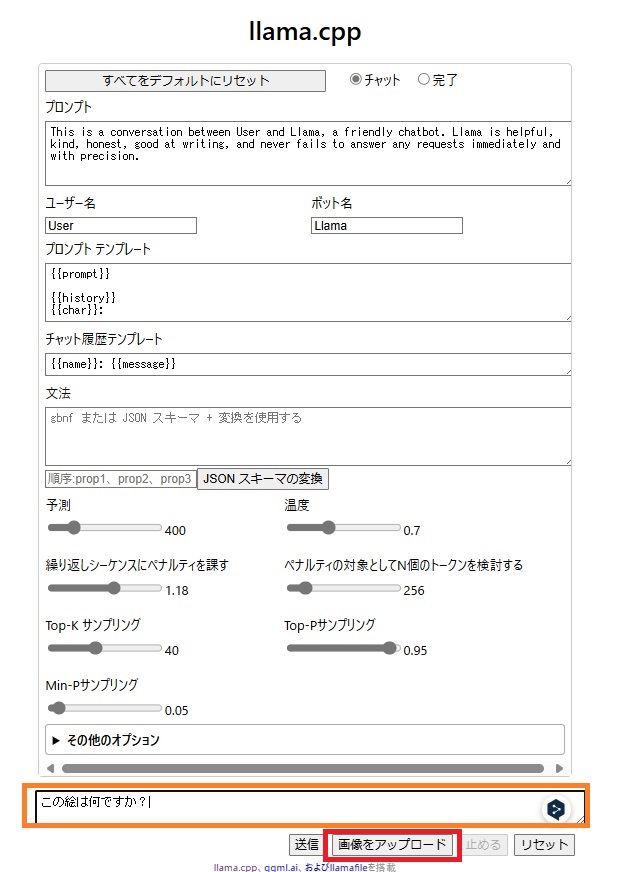
例えばモナリザを読み込んでそれが何なのか教えてもらいます。

画像をアップロードして、プロンプトを「この絵は何ですか?」としてみます。
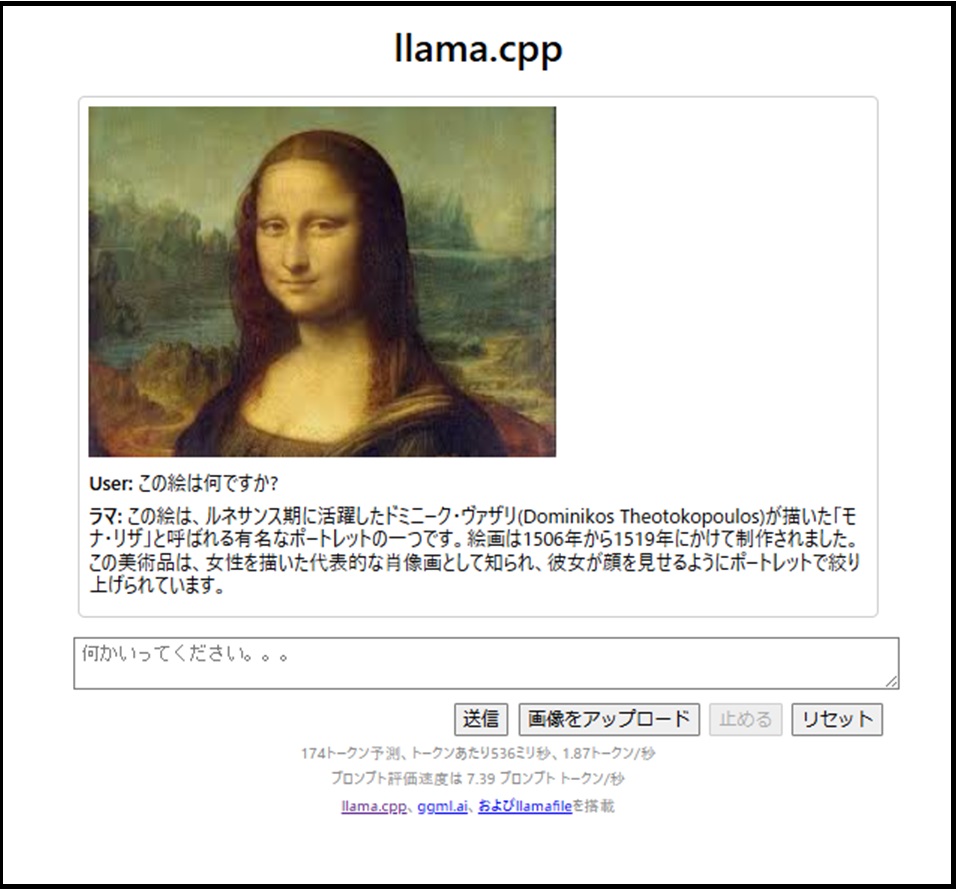
少々ひ弱なWindowsマシンなので1分強かかりましたが、回答はくれました(ちょっとホラが入ってます、画家はダ・ヴィンチです、Dominikos Theotokopoulosってエル・グレコのことのようです)。使っているのが量子化モデルなので精度は若干落ちているかも…..です。
昨今GPT-4omni という超多彩なマルチモーダルモデルが発表されています。使ってみたいですね。
ただGPT-4oは大きすぎるので、オンプレミスで使うなら複数LLMやSLMをLangChain などで使うのが現実的?
注1:モデルによっては対応できるものとそうでないものがあります。
例えばPhi-3-mini-4K-instructは、q4.gguf /fp16.ggufどちらの場合も
そのままllamafile.exeで実行しようとすると。unknown model architectureでロード失敗のエラーになりました。
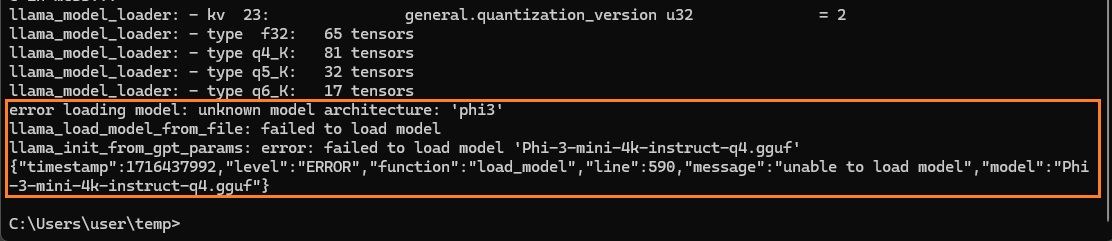
fp16.ggufのllamafile版(Phi-3-mini-4k-instruct.F16.llamafile)は大きすぎて実行さえできませんでした。
注2:llamafileのバージョン0.7が公開されています。
0.6の倍くらい高速で、おまけに英語の質問に日本語で応答が返ってきました…..?
注3:llamafileはllama.cppをベースにしているのでCPU を使うことが眼目ですが、もしNVIDIA 製のGPU を積んでいるなら -ngl 9999 オプションを付ければGPU オフロード(offloading)を有効にできます。つまり、推論演算が高速化されます。
Llamafileは、Apple Silicon上のApple Metal、Linux上のNvidia cuBLAS、およびWindows上のネイティブGPUサポートを含む幅広いGPUサポートを提供しています。最適なパフォーマンスを得るために、GPUサポートは動的にリンクされます。LMMで画像を認識させるとファンが高速に回転し始めて結構うるさいです。またMacの場合、Apple Silicon がサポートされいるので、ちょっと前のM1チップでも快適に動作するそうです。
ラズパイ5(ARM64)
OSイメージはRaspberry Pi OS Desktop (64-bit)Bookworm……Debianです。
Ubuntu Desktop 24.04 LTS (64-bit)でも可。
基本的にはllamafile公式の通りです(Using llamafile with external weights)。
作業フォルダーを作成してllamafile version 0.6とmistral をダウンロードして実行するだけ。
|
1 2 3 4 5 6 |
mkdir temp cd temp curl -L -o llamafile https://github.com/Mozilla-Ocho/llamafile/releases/download/0.6/llamafile-0.6 curl -L -o mistral.gguf https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.1-GGUF/resolve/main/mistral-7b-instruct-v0.1.Q4_K_M.gguf |
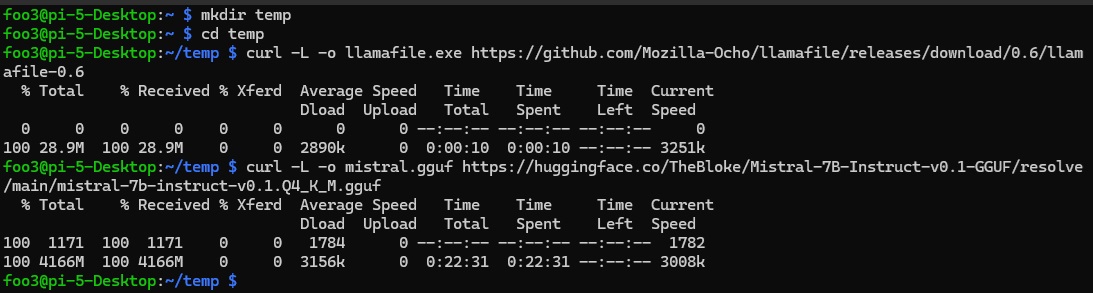
Linuxなので実行権を与えて実行します。
|
1 2 3 |
sudo chmod 755 llamafile ./llamafile -m mistral.gguf |
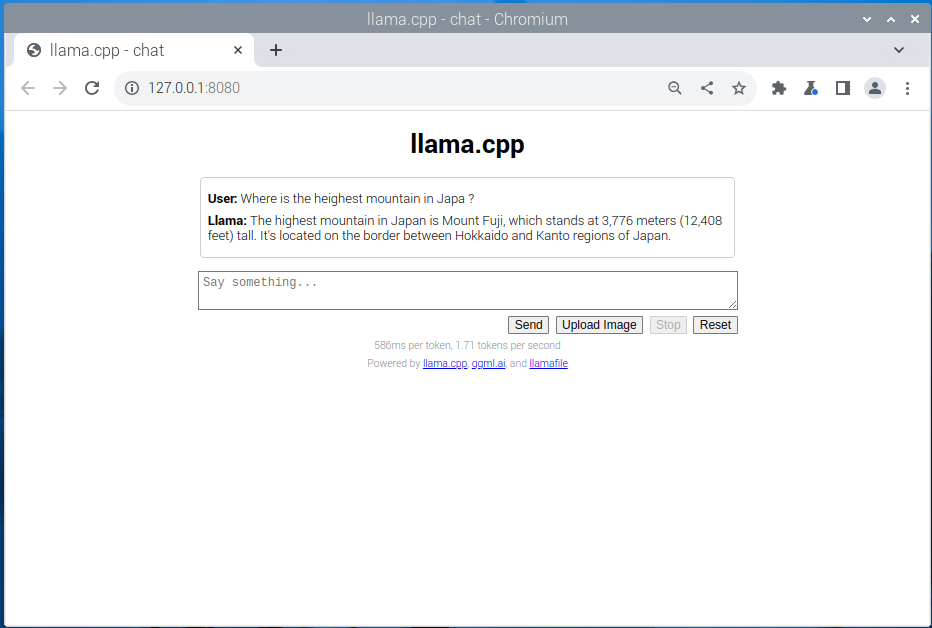
入力画面が開きます。
プロンプト「Where is the heighest mountain in Japan ?」を入力して実行、結果はだいたい20秒くらいで返ってきました。
ラズパイ5(8GB)ではWindows のような4GBの壁がないので、大きなllamafileでも実行はできます、一応。
llamafile公式のSLMモデルPhi-3-mini-4k-instruct(7.67 GB)の場合
|
1 2 3 4 5 |
curl -L -o phi-3-f16.llamafile https://huggingface.co/Mozilla/Phi-3-mini-4k-instruct-llamafile/resolve/main/Phi-3-mini-4k-instruct.F16.llamafile sudo chmod 755 phi-3-f16.llamafile ./phi-3-f16.llamafile |
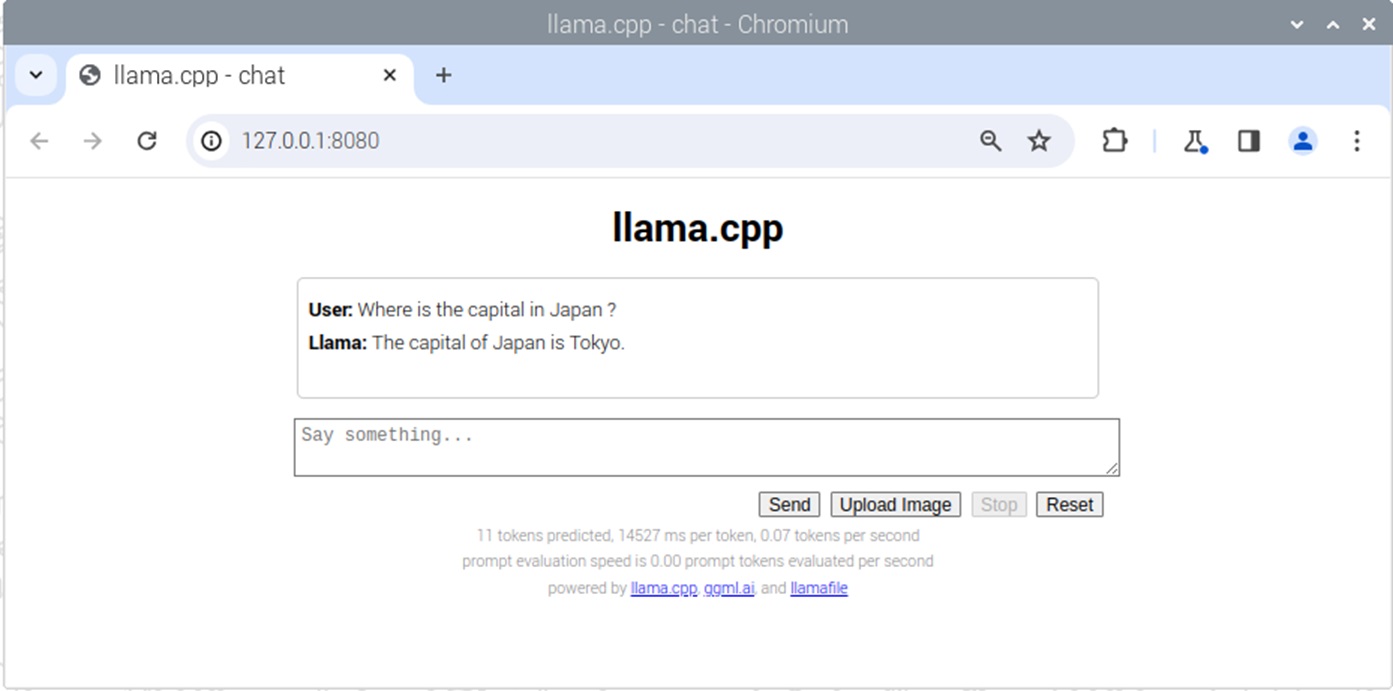
プロンプト:”Where is the capital in Japan ?”をやってみました。
40秒くらいから回答を返し始めますが、トークン生成はすごく貧弱です。回答を完結するのに3分くらいかかっています。
● SSH で外部から接続している場合、サーバーを公開しておきます
例えばllava-v1.5-7b-q4.llamafileの場合….
|
1 2 3 4 5 |
curl -L -o llava15.llamafile https://huggingface.co/Mozilla/llava-v1.5-7b-llamafile/resolve/main/llava-v1.5-7b-q4.llamafile sudo chmod 755 llava15.llamafile ./llava15.llamafile --host 0.0.0.0 -t 4 --port 8080 |
外部ブラウザーから
http://<ラズパイのIPアドレス> :8080
● xxxxx.llamafile はmオプションで自前以外の言語モデルを読み込んで使うことができます
例えばrocket-3b.Q5_K_M.llamafileという比較的小規模のllamafile を使ってみます。
Windowsでやってみます。
|
1 |
rocket-3b.Q5_K_M.llamafile.exe |
モナリザをアップロードしてみました。

これは普通の言語モデルなのでこの画像を認識できません。
こんな感じ。
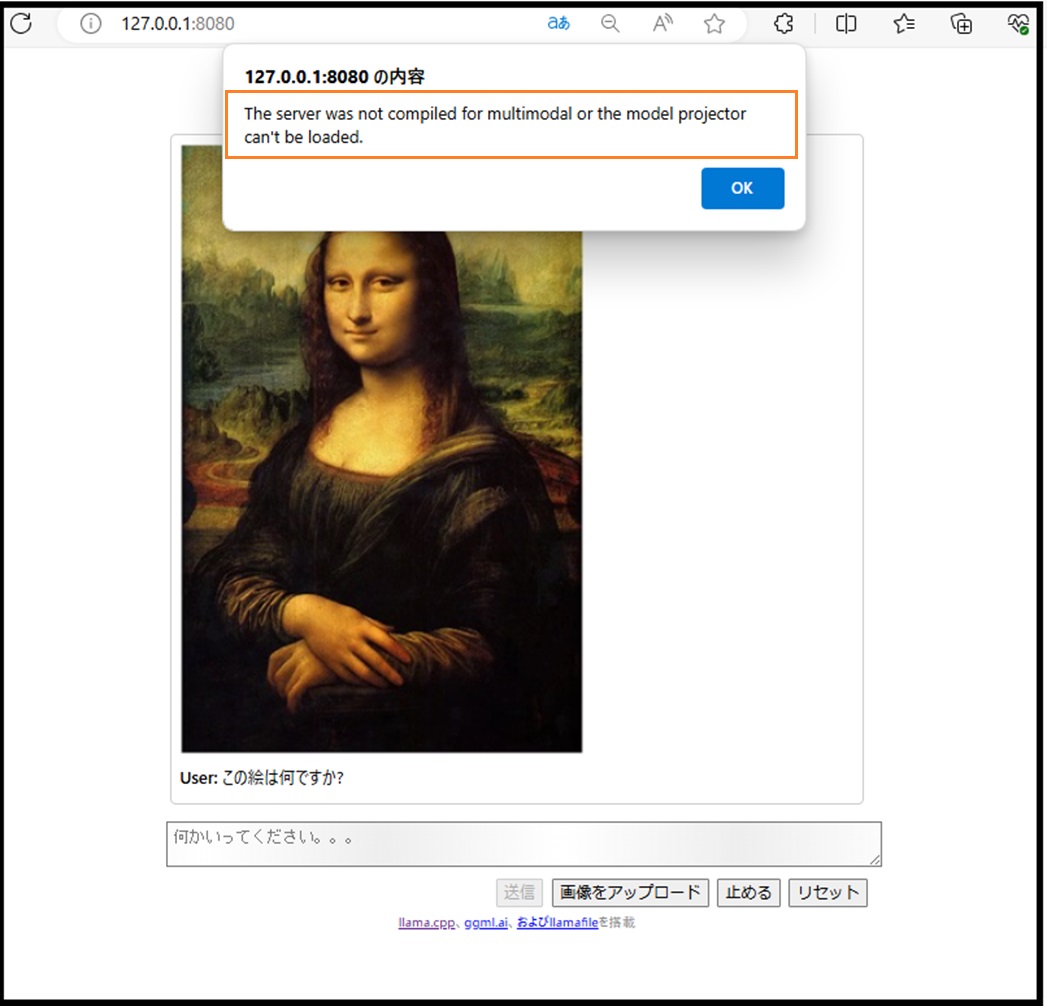
mオプションでLMM(llava-v1.5-7b-Q4_K.gguf)を使って推論実行してみます。
llamafileのhelpにあるように、mmprojオプションでllava-v1.5-7b-mmproj-Q4_0.ggufというファイルが必要です。
rocket-3b.Q5_K_M.llamafile.exe -m llava-v1.5-7b-Q4_K.gguf --mmproj llava-v1.5-7b-mmproj-Q4_0.gguf
LMMを読んでrocket-3b.Q5_K_M.llamafile.exeでも画像を認識できています。
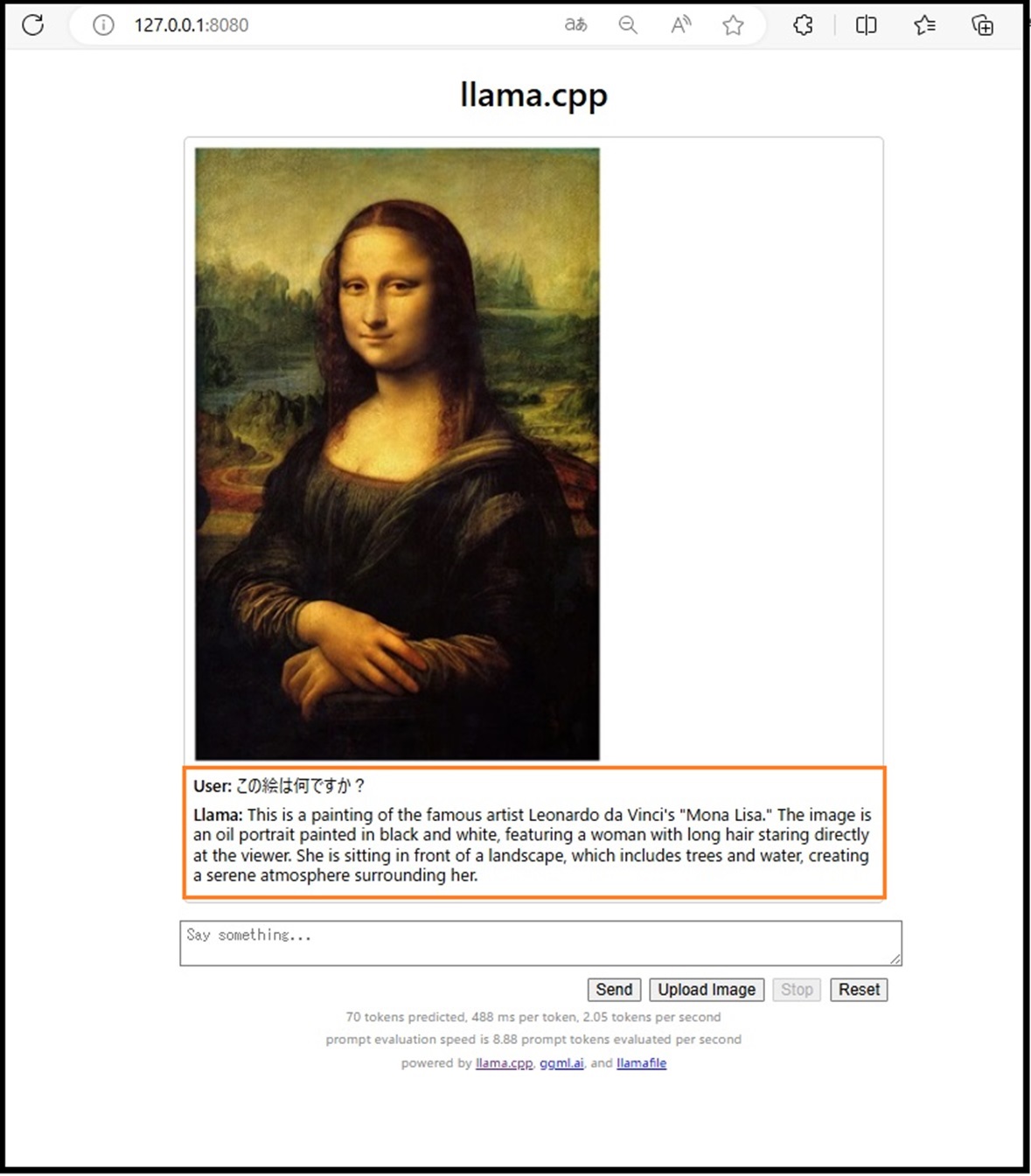
ただ残念ながらちょっとウソついてます。
Llama: This is a painting of the famous artist Leonardo da Vinci’s “Mona Lisa.” The image is an oil portrait painted in black and white, featuring a woman with long hair staring directly at the viewer. She is sitting in front of a landscape, which includes trees and water, creating a serene atmosphere surrounding her.
ラマ:これは有名な芸術家レオナルド・ダ・ヴィンチの「モナ・リザ」の絵です。 この画像は白黒で描かれた油絵で、見る者をまっすぐに見つめる長い髪の女性を特徴としています。 彼女は木々や水のある風景の前に座っており、彼女を取り巻く穏やかな雰囲気を作り出しています。
回答を返し始めるのに
Windows で1分半、ラズパイ5で3分弱くらいでした。
Appendix
Appendix2
llamafile HELP
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 530 531 532 533 534 535 536 537 538 539 540 541 542 543 544 545 546 547 548 549 550 551 552 553 554 555 556 557 558 559 560 561 562 563 564 565 566 567 568 569 570 571 572 573 574 575 576 577 578 579 580 581 582 583 584 585 586 587 588 589 590 591 592 593 594 595 596 597 598 599 600 601 602 603 604 605 606 607 608 609 610 611 612 613 614 615 616 617 618 619 620 621 622 623 624 625 626 627 628 629 630 631 632 633 634 635 636 637 638 639 640 641 642 643 644 645 646 647 648 649 650 651 652 653 654 655 656 657 658 659 660 661 662 663 664 665 666 667 668 669 670 671 672 673 674 675 676 677 678 679 680 681 682 683 684 685 686 687 688 689 690 691 692 693 694 695 696 697 698 699 700 701 702 703 704 705 706 707 708 709 710 711 712 713 714 715 716 717 718 719 720 721 722 723 724 725 726 727 728 729 730 731 732 733 734 735 736 737 738 739 740 741 742 743 744 745 746 747 748 749 750 751 752 753 754 755 756 757 |
LLAMAFILE(1) BSD General Commands Manual LLAMAFILE(1) NAME llamafile — large language model runner SYNOPSIS llamafile [--server] [flags...] -m model.gguf [--mmproj vision.gguf] llamafile [--cli] [flags...] -m model.gguf -p prompt llamafile [--cli] [flags...] -m model.gguf --mmproj vision.gguf --image graphic.png -p prompt DESCRIPTION llamafile is a large language model tool. It has use cases such as: - Code completion - Prose composition - Chatbot that passes the Turing test - Text/image summarization and analysis OPTIONS The following options are available: --version Print version and exit. -h, --help Show help message and exit. --cli Puts program in command line interface mode. This flag is implied when a prompt is supplied using either the -p or -f flags. --server Puts program in server mode. This will launch an HTTP server on a local port. This server has both a web UI and an OpenAI API com‐ patible completions endpoint. When the server is run on a desk system, a tab browser tab will be launched automatically that displays the web UI. This --server flag is implied if no prompt is specified, i.e. neither the -p or -f flags are passed. -m FNAME, --model FNAME Model path in the GGUF file format. Default: models/7B/ggml-model-f16.gguf --mmproj FNAME Specifies path of the LLaVA vision model in the GGUF file format. If this flag is supplied, then the --model and --image flags should also be supplied. -s SEED, --seed SEED Random Number Generator (RNG) seed. A random seed is used if this is less than zero. Default: -1 -t N, --threads N Number of threads to use during generation. Default: $(nproc)/2 -tb N, --threads-batch N Number of threads to use during batch and prompt processing. Default: Same as --threads --in-prefix-bos Prefix BOS to user inputs, preceding the --in-prefix string. --in-prefix STRING This flag is used to add a prefix to your input, primarily, this is used to insert a space after the reverse prompt. Here's an ex‐ ample of how to use the --in-prefix flag in conjunction with the --reverse-prompt flag: ./main -r "User:" --in-prefix " " Default: empty --in-suffix STRING This flag is used to add a suffix after your input. This is use‐ ful for adding an "Assistant:" prompt after the user's input. It's added after the new-line character (\n) that's automatically added to the end of the user's input. Here's an example of how to use the --in-suffix flag in conjunction with the --reverse-prompt flag: ./main -r "User:" --in-prefix " " --in-suffix "Assistant:" Default: empty -n N, --n-predict N Number of tokens to predict. - -1 = infinity - -2 = until context filled Default: -1 -c N, --ctx-size N Set the size of the prompt context. A larger context size helps the model to better comprehend and generate responses for longer input or conversations. The LLaMA models were built with a con‐ text of 2048, which yields the best results on longer input / in‐ ference. - 0 = loaded automatically from model Default: 512 -b N, --batch-size N Batch size for prompt processing. Default: 512 --top-k N Top-k sampling. - 0 = disabled Default: 40 --top-p N Top-p sampling. - 1.0 = disabled Default: 0.9 --min-p N Min-p sampling. - 0.0 = disabled Default: 0.1 --tfs N Tail free sampling, parameter z. - 1.0 = disabled Default: 1.0 --typical N Locally typical sampling, parameter p. - 1.0 = disabled Default: 1.0 --repeat-last-n N Last n tokens to consider for penalize. - 0 = disabled - -1 = ctx_size Default: 64 --repeat-penalty N Penalize repeat sequence of tokens. - 1.0 = disabled Default: 1.1 --presence-penalty N Repeat alpha presence penalty. - 0.0 = disabled Default: 0.0 --frequency-penalty N Repeat alpha frequency penalty. - 0.0 = disabled Default: 0.0 --mirostat N Use Mirostat sampling. Top K, Nucleus, Tail Free and Locally Typ‐ ical samplers are ignored if used.. - 0 = disabled - 1 = Mirostat - 2 = Mirostat 2.0 Default: 0 --mirostat-lr N Mirostat learning rate, parameter eta. Default: 0.1 --mirostat-ent N Mirostat target entropy, parameter tau. Default: 5.0 -l TOKEN_ID(+/-)BIAS, --logit-bias TOKEN_ID(+/-)BIAS Modifies the likelihood of token appearing in the completion, i.e. --logit-bias 15043+1 to increase likelihood of token ' Hello', or --logit-bias 15043-1 to decrease likelihood of token ' Hello'. -md FNAME, --model-draft FNAME Draft model for speculative decoding. Default: models/7B/ggml-model-f16.gguf --cfg-negative-prompt PROMPT Negative prompt to use for guidance.. Default: empty --cfg-negative-prompt-file FNAME Negative prompt file to use for guidance. Default: empty --cfg-scale N Strength of guidance. - 1.0 = disable Default: 1.0 --rope-scaling {none,linear,yarn} RoPE frequency scaling method, defaults to linear unless speci‐ fied by the model --rope-scale N RoPE context scaling factor, expands context by a factor of N where N is the linear scaling factor used by the fine-tuned model. Some fine-tuned models have extended the context length by scaling RoPE. For example, if the original pre-trained model have a context length (max sequence length) of 4096 (4k) and the fine- tuned model have 32k. That is a scaling factor of 8, and should work by setting the above --ctx-size to 32768 (32k) and --rope-scale to 8. --rope-freq-base N RoPE base frequency, used by NTK-aware scaling. Default: loaded from model --rope-freq-scale N RoPE frequency scaling factor, expands context by a factor of 1/N --yarn-orig-ctx N YaRN: original context size of model. Default: 0 = model training context size --yarn-ext-factor N YaRN: extrapolation mix factor. - 0.0 = full interpolation Default: 1.0 --yarn-attn-factor N YaRN: scale sqrt(t) or attention magnitude. Default: 1.0 --yarn-beta-slow N YaRN: high correction dim or alpha. Default: 1.0 --yarn-beta-fast N YaRN: low correction dim or beta. Default: 32.0 --ignore-eos Ignore end of stream token and continue generating (implies --logit-bias 2-inf) --no-penalize-nl Do not penalize newline token. --temp N Temperature. Default: 0.8 --logits-all Return logits for all tokens in the batch. Default: disabled --hellaswag Compute HellaSwag score over random tasks from datafile supplied with -f --hellaswag-tasks N Number of tasks to use when computing the HellaSwag score. Default: 400 --keep N This flag allows users to retain the original prompt when the model runs out of context, ensuring a connection to the initial instruction or conversation topic is maintained, where N is the number of tokens from the initial prompt to retain when the model resets its internal context. - 0 = no tokens are kept from initial prompt - -1 = retain all tokens from initial prompt Default: 0 --draft N Number of tokens to draft for speculative decoding. Default: 16 --chunks N Max number of chunks to process. - -1 = all Default: -1 -ns N, --sequences N Number of sequences to decode. Default: 1 -pa N, --p-accept N speculative decoding accept probability. Default: 0.5 -ps N, --p-split N Speculative decoding split probability. Default: 0.1 --mlock Force system to keep model in RAM rather than swapping or com‐ pressing. --no-mmap Do not memory-map model (slower load but may reduce pageouts if not using mlock). --numa Attempt optimizations that help on some NUMA systems if run with‐ out this previously, it is recommended to drop the system page cache before using this. See https://github.com/ggerganov/llama.cpp/issues/1437. --recompile Force GPU support to be recompiled at runtime if possible. --nocompile Never compile GPU support at runtime. If the appropriate DSO file already exists under ~/.llamafile/ then it'll be linked as-is without question. If a prebuilt DSO is present in the PKZIP content of the executable, then it'll be ex‐ tracted and linked if possible. Otherwise, llamafile will skip any attempt to compile GPU support and simply fall back to using CPU inference. --gpu GPU Specifies which brand of GPU should be used. Valid choices are: - AUTO: Use any GPU if possible, otherwise fall back to CPU in‐ ference (default) - APPLE: Use Apple Metal GPU. This is only available on MacOS ARM64. If Metal could not be used for any reason, then a fa‐ tal error will be raised. - AMD: Use AMD GPUs. The AMD HIP ROCm SDK should be installed in which case we assume the HIP_PATH environment variable has been defined. The set of gfx microarchitectures needed to run on the host machine is determined automatically based on the output of the hipInfo command. On Windows, llamafile release binaries are distributed with a tinyBLAS DLL so it'll work out of the box without requiring the HIP SDK to be installed. However, tinyBLAS is slower than rocBLAS for batch and image processing, so it's recommended that the SDK be installed anyway. If an AMD GPU could not be used for any reason, then a fatal error will be raised. - NVIDIA: Use NVIDIA GPUs. If an NVIDIA GPU could not be used for any reason, a fatal error will be raised. On Windows, NVIDIA GPU support will use our tinyBLAS library, since it works on stock Windows installs. However, tinyBLAS goes slower for batch and image processing. It's possible to use NVIDIA's closed-source cuBLAS library instead. To do that, both MSVC and CUDA need to be installed and the llamafile command should be run once from the x64 MSVC command prompt with the --recompile flag passed. The GGML library will then be compiled and saved to ~/.llamafile/ so the special process only needs to happen a single time. - DISABLE: Never use GPU and instead use CPU inference. This setting is implied by -ngl 0. -ngl N, --n-gpu-layers N Number of layers to store in VRAM. -ngld N, --n-gpu-layers-draft N Number of layers to store in VRAM for the draft model. -ts SPLIT, --tensor-split SPLIT How to split tensors across multiple GPUs, comma-separated list of proportions, e.g. 3,1 -mg i, --main-gpu i The GPU to use for scratch and small tensors. -nommq, --no-mul-mat-q Use cuBLAS instead of custom mul_mat_q CUDA kernels. Not recom‐ mended since this is both slower and uses more VRAM. --verbose-prompt Print prompt before generation. --simple-io Use basic IO for better compatibility in subprocesses and limited consoles. --lora FNAME Apply LoRA adapter (implies --no-mmap) --lora-scaled FNAME S Apply LoRA adapter with user defined scaling S (implies --no-mmap) --lora-base FNAME Optional model to use as a base for the layers modified by the LoRA adapter --unsecure Disables pledge() sandboxing on Linux and OpenBSD. --samplers Samplers that will be used for generation in the order, separated by semicolon, for example: top_k;tfs;typical;top_p;min_p;temp --samplers-seq Simplified sequence for samplers that will be used. -cml, --chatml Run in chatml mode (use with ChatML-compatible models) -dkvc, --dump-kv-cache Verbose print of the KV cache. -nkvo, --no-kv-offload Disable KV offload. -ctk TYPE, --cache-type-k TYPE KV cache data type for K. -ctv TYPE, --cache-type-v TYPE KV cache data type for V. CLI OPTIONS The following options may be specified when llamafile is running in --cli mode. -e, --escape Process prompt escapes sequences (\n, \r, \t, \´, \", \\) -p STRING, --prompt STRING Prompt to start text generation. Your LLM works by auto-complet‐ ing this text. For example: llamafile -m model.gguf -p "four score and" Stands a pretty good chance of printing Lincoln's Gettysburg Ad‐ dress. Prompts can take on a structured format too. Depending on how your model was trained, it may specify in its docs an in‐ struction notation. With some models that might be: llamafile -p "[INST]Summarize this: $(cat file)[/INST]" In most cases, simply colons and newlines will work too: llamafile -e -p "User: What is best in life?\nAssistant:" -f FNAME, --file FNAME Prompt file to start generation. --grammar GRAMMAR BNF-like grammar to constrain which tokens may be selected when generating text. For example, the grammar: root ::= "yes" | "no" will force the LLM to only output yes or no before exiting. This is useful for shell scripts when the --silent-prompt flag is also supplied. --grammar-file FNAME File to read grammar from. --prompt-cache FNAME File to cache prompt state for faster startup. Default: none --prompt-cache-all If specified, saves user input and generations to cache as well. Not supported with --interactive or other interactive options. --prompt-cache-ro If specified, uses the prompt cache but does not update it. --random-prompt Start with a randomized prompt. --image IMAGE_FILE Path to an image file. This should be used with multimodal mod‐ els. Alternatively, it's possible to embed an image directly into the prompt instead; in which case, it must be base64 encoded into an HTML img tag URL with the image/jpeg MIME type. See also the --mmproj flag for supplying the vision model. -i, --interactive Run the program in interactive mode, allowing users to engage in real-time conversations or provide specific instructions to the model. --interactive-first Run the program in interactive mode and immediately wait for user input before starting the text generation. -ins, --instruct Run the program in instruction mode, which is specifically de‐ signed to work with Alpaca models that excel in completing tasks based on user instructions. Technical details: The user's input is internally prefixed with the reverse prompt (or "### Instruction:" as the default), and followed by "### Response:" (except if you just press Return without any input, to keep generating a longer response). By understanding and utilizing these interaction options, you can create engaging and dynamic experiences with the LLaMA models, tailoring the text generation process to your specific needs. -r PROMPT, --reverse-prompt PROMPT Specify one or multiple reverse prompts to pause text generation and switch to interactive mode. For example, -r "User:" can be used to jump back into the conversation whenever it's the user's turn to speak. This helps create a more interactive and conversa‐ tional experience. However, the reverse prompt doesn't work when it ends with a space. To overcome this limitation, you can use the --in-prefix flag to add a space or any other characters after the reverse prompt. --color Enable colorized output to differentiate visually distinguishing between prompts, user input, and generated text. --silent-prompt Don't echo the prompt itself to standard output. --multiline-input Allows you to write or paste multiple lines without ending each in '\'. SERVER OPTIONS The following options may be specified when llamafile is running in --server mode. --port PORT Port to listen Default: 8080 --host IPADDR IP address to listen. Default: 127.0.0.1 -to N, --timeout N Server read/write timeout in seconds. Default: 600 -np N, --parallel N Number of slots for process requests. Default: 1 -cb, --cont-batching Enable continuous batching (a.k.a dynamic batching). Default: disabled -spf FNAME, --system-prompt-file FNAME Set a file to load a system prompt (initial prompt of all slots), this is useful for chat applications. -a ALIAS, --alias ALIAS Set an alias for the model. This will be added as the model field in completion responses. --path PUBLIC_PATH Path from which to serve static files. Default: /zip/llama.cpp/server/public --embedding Enable embedding vector output. Default: disabled --nobrowser Do not attempt to open a web browser tab at startup. LOG OPTIONS The following log options are available: -ld LOGDIR, --logdir LOGDIR Path under which to save YAML logs (no logging if unset) --log-test Run simple logging test --log-disable Disable trace logs --log-enable Enable trace logs --log-file Specify a log filename (without extension) --log-new Create a separate new log file on start. Each log file will have unique name: <name>.<ID>.log --log-append Don't truncate the old log file. EXAMPLES Here's an example of how to run llama.cpp's built-in HTTP server. This example uses LLaVA v1.5-7B, a multimodal LLM that works with llama.cpp's recently-added support for image inputs. llamafile \ -m llava-v1.5-7b-Q8_0.gguf \ --mmproj llava-v1.5-7b-mmproj-Q8_0.gguf \ --host 0.0.0.0 Here's an example of how to generate code for a libc function using the llama.cpp command line interface, utilizing WizardCoder-Python-13B weights: llamafile \ -m wizardcoder-python-13b-v1.0.Q8_0.gguf --temp 0 -r '}\n' -r '```\n' \ -e -p '```c\nvoid *memcpy(void *dst, const void *src, size_t size) {\n' Here's a similar example that instead utilizes Mistral-7B-Instruct weights for prose composition: llamafile \ -m mistral-7b-instruct-v0.2.Q5_K_M.gguf \ -p '[INST]Write a story about llamas[/INST]' Here's an example of how llamafile can be used as an interactive chatbot that lets you query knowledge contained in training data: llamafile -m llama-65b-Q5_K.gguf -p ' The following is a conversation between a Researcher and their helpful AI assistant Digital Athena which is a large language model trained on the sum of human knowledge. Researcher: Good morning. Digital Athena: How can I help you today? Researcher:' --interactive --color --batch_size 1024 --ctx_size 4096 \ --keep -1 --temp 0 --mirostat 2 --in-prefix ' ' --interactive-first \ --in-suffix 'Digital Athena:' --reverse-prompt 'Researcher:' Here's an example of how you can use llamafile to summarize HTML URLs: ( echo '[INST]Summarize the following text:' links -codepage utf-8 \ -force-html \ -width 500 \ -dump https://www.poetryfoundation.org/poems/48860/the-raven | sed 's/ */ /g' echo '[/INST]' ) | llamafile \ -m mistral-7b-instruct-v0.2.Q5_K_M.gguf \ -f /dev/stdin \ -c 0 \ --temp 0 \ -n 500 \ --silent-prompt 2>/dev/null Here's how you can use llamafile to describe a jpg/png/gif/bmp image: llamafile --temp 0 \ --image lemurs.jpg \ -m llava-v1.5-7b-Q4_K.gguf \ --mmproj llava-v1.5-7b-mmproj-Q4_0.gguf \ -e -p '### User: What do you see?\n### Assistant: ' \ --silent-prompt 2>/dev/null If you wanted to write a script to rename all your image files, you could use the following command to generate a safe filename: llamafile --temp 0 \ --image ~/Pictures/lemurs.jpg \ -m llava-v1.5-7b-Q4_K.gguf \ --mmproj llava-v1.5-7b-mmproj-Q4_0.gguf \ --grammar 'root ::= [a-z]+ (" " [a-z]+)+' \ -e -p '### User: The image has...\n### Assistant: ' \ --silent-prompt 2>/dev/null | sed -e's/ /_/g' -e's/$/.jpg/' three_baby_lemurs_on_the_back_of_an_adult_lemur.jpg Here's an example of how to make an API request to the OpenAI API compat‐ ible completions endpoint when your llamafile is running in the back‐ ground in --server mode. curl -s http://localhost:8080/v1/chat/completions \ -H "Content-Type: application/json" -d '{ "model": "gpt-3.5-turbo", "stream": true, "messages": [ { "role": "system", "content": "You are a poetic assistant." }, { "role": "user", "content": "Compose a poem that explains FORTRAN." } ] }' | python3 -c ' import json import sys json.dump(json.load(sys.stdin), sys.stdout, indent=2) print() PROTIP The -ngl 35 flag needs to be passed in order to use GPUs made by NVIDIA and AMD. It's not enabled by default since it sometimes needs to be tuned based on the system hardware and model architecture, in order to achieve optimal performance, and avoid compromising a shared display. SEE ALSO llamafile-quantize(1), llamafile-perplexity(1), llava-quantize(1), zipalign(1), unzip(1) Mozilla Ocho January 1, 2024 Mozilla Ocho |
Leave a Reply