
電子書籍ニューラルネットワークと深層学習はNeural Networkって何?を理解するのに手ごろな内容になっています。
また、このテキストにはいくつもExerciseや「証明してみてください」があるので理解が深まります。
ここでは、既存のフレームワークは使わず、書籍の中の第一章(Chapter 1)にあるシグモイドニューロンを使って数字を分類するニューラルネットワークの実習コードをスクラッチから試してみます。
基本的にこれらのコードを実行するのにGPUは使いません。
GPUが必要になるのはChapter6でTheanoライブラリを使う時くらいです。
MNISTデータセットを使った非常にシンプルなもので、ハイパーパラメータがどんなものか体験しながら学習できます。
PDF版 Word版(OpenOfficeでも開きますがLaTeXの表記が崩れます)
各コードはLinuxで動かすのが前提のようですが、ここではWindows(64Bit)でやってみます。
Python実行環境が必要ですが、Windowsの場合はAnacondaを使ってみます。
AnacondaのインストールはDarknetをWindowsで使ってみる(学習準備編)を参照
PythonコードやMNISTデータセットなどの一式はGitHubにあります。
ダウンロードして適当な場所(例:c:\)に解凍しておきます。
ここでは、C:¥neural-networks-and-deep-learning-masterとしておきます。
AnacondaおよびPython2.7もインストール済として進めます。
Anaconda Promptを起動します。
実行ソースのあるディレクトリへ移動しておきます。
コードはPython2.x用なので、環境を変えます(Python3.xの場合はこちら)。
>activate python27 <–ここは各自インストール時の設定で読み換え
>python
Pythonシェルに入ります。
MNISTデータセットをロードします。
>>> import mnist_loader
>>> training_data, validation_data, test_data = mnist_loader.load_data_wrapper()
ハイパーパラメータ
(Network設定)
MNISTの訓練用データは、手書き数字の28×28ピクセルの画像なので、入力層は28×28=784ニューロンからなっていいます。
30個の隠れニューロンを持ち、10個の出力ニューロンを持つネットワークを設定してみます。
>>> import network
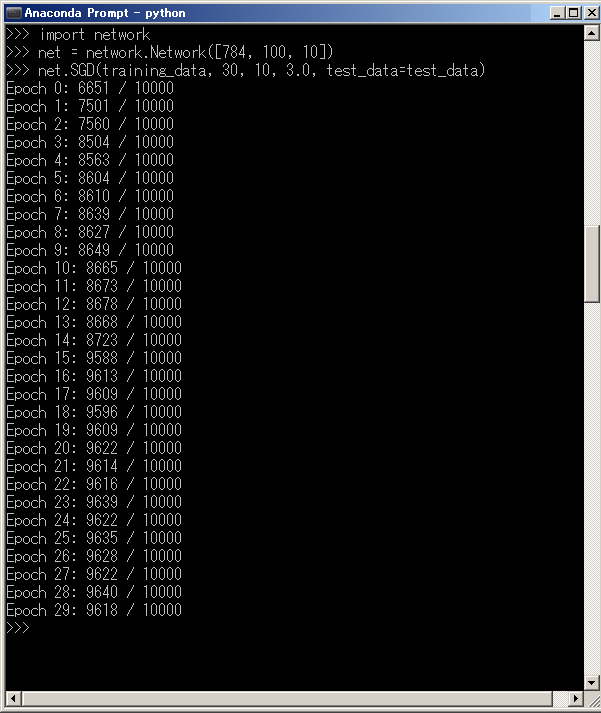
>>> net = network.Network([784, 30, 10])
30世代(Epoch)・ミニバッチサイズ10・訓練率η=3.0の条件で、MNISTのtraining_dataから確率的勾配降下法を使用して学習を実行する設定です。
Chapter1には、確率的勾配降下法(Stochastic Gradient Descent)とミニバッチのPythonコードも紹介されています。誤差逆伝播法(Backpropagation)のコードはChapter2以降にあります。
>>> net.SGD(training_data, 30, 10, 3.0, test_data=test_data)
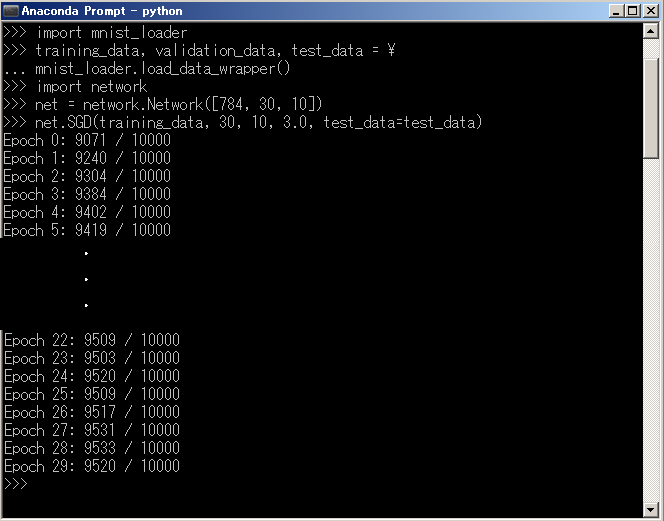
ピーク性能は28世代(Epoch 28)での95.33%でした。
テキスト通りではないですが、95%+αには到達していますね。
隠れニューロンを100個にしてみました。
確かに時間はかかりましたが、ピーク性能は28世代(Epoch 28)の96.40%でした。
なるほど、精度は上がってます。
データセットのロードと学習のコードはこんな感じです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 |
【mnist_loader】 import cPickle import gzip import numpy as np def load_data(): f = gzip.open('../data/mnist.pkl.gz', 'rb') training_data, validation_data, test_data = cPickle.load(f) f.close() return (training_data, validation_data, test_data) def load_data_wrapper(): tr_d, va_d, te_d = load_data() training_inputs = [np.reshape(x, (784, 1)) for x in tr_d[0]] training_results = [vectorized_result(y) for y in tr_d[1]] training_data = zip(training_inputs, training_results) validation_inputs = [np.reshape(x, (784, 1)) for x in va_d[0]] validation_data = zip(validation_inputs, va_d[1]) test_inputs = [np.reshape(x, (784, 1)) for x in te_d[0]] test_data = zip(test_inputs, te_d[1]) return (training_data, validation_data, test_data) def vectorized_result(j): e = np.zeros((10, 1)) e[j] = 1.0 return e 【network】 import random import numpy as np class Network(object): def __init__(self, sizes): self.num_layers = len(sizes) self.sizes = sizes self.biases = [np.random.randn(y, 1) for y in sizes[1:]] self.weights = [np.random.randn(y, x) for x, y in zip(sizes[:-1], sizes[1:])] def feedforward(self, a): for b, w in zip(self.biases, self.weights): a = sigmoid(np.dot(w, a)+b) return a def SGD(self, training_data, epochs, mini_batch_size, eta,test_data=None): if test_data: n_test = len(test_data) n = len(training_data) for j in xrange(epochs): random.shuffle(training_data) mini_batches = [ training_data[k:k+mini_batch_size] for k in xrange(0, n, mini_batch_size)] for mini_batch in mini_batches: self.update_mini_batch(mini_batch, eta) if test_data: print "Epoch {0}: {1} / {2}".format( j, self.evaluate(test_data), n_test) else: print "Epoch {0} complete".format(j) def update_mini_batch(self, mini_batch, eta): nabla_b = [np.zeros(b.shape) for b in self.biases] nabla_w = [np.zeros(w.shape) for w in self.weights] for x, y in mini_batch: delta_nabla_b, delta_nabla_w = self.backprop(x, y) nabla_b = [nb+dnb for nb, dnb in zip(nabla_b, delta_nabla_b)] nabla_w = [nw+dnw for nw, dnw in zip(nabla_w, delta_nabla_w)] self.weights = [w-(eta/len(mini_batch))*nw for w, nw in zip(self.weights, nabla_w)] self.biases = [b-(eta/len(mini_batch))*nb for b, nb in zip(self.biases, nabla_b)] def backprop(self, x, y): nabla_b = [np.zeros(b.shape) for b in self.biases] nabla_w = [np.zeros(w.shape) for w in self.weights] activation = x activations = [x] zs = [] for b, w in zip(self.biases, self.weights): z = np.dot(w, activation)+b zs.append(z) activation = sigmoid(z) activations.append(activation) delta = self.cost_derivative(activations[-1], y) * \ sigmoid_prime(zs[-1]) nabla_b[-1] = delta nabla_w[-1] = np.dot(delta, activations[-2].transpose()) for l in xrange(2, self.num_layers): z = zs[-l] sp = sigmoid_prime(z) delta = np.dot(self.weights[-l+1].transpose(), delta) * sp nabla_b[-l] = delta nabla_w[-l] = np.dot(delta, activations[-l-1].transpose()) return (nabla_b, nabla_w) def evaluate(self, test_data): test_results = [(np.argmax(self.feedforward(x)), y) for (x, y) in test_data] return sum(int(x == y) for (x, y) in test_results) def cost_derivative(self, output_activations, y): return (output_activations-y) def sigmoid(z): return 1.0/(1.0+np.exp(-z)) def sigmoid_prime(z): return sigmoid(z)*(1-sigmoid(z)) |
注:このコードでひっかかるところはあまりないと思われますが、最後の
sigmoid_prime(z)って何でしょう?
これは、その上で定義されているシグモイド関数の導関数ですが、これについてはニューラルネットワークと深層学習でも何も触れられていません(これは第三章の最初の演習になっています)。高校数学の復習問題です。シグモイド関数をzで微分します。連鎖律(合成関数の微分)を使ってみましょう。$$y(z) = 1 /(1 + e^{-z }) で、 u = (1 + e^{-z })、t= -zとします$$
途中でトリッキーと思える式変形が必要になりますが、頭の体操みたいなもんです、導関数をみちびいてみてください。y(z)’ = y(z)・(1 – y(z)) -> 解答
注:Gitクローンされたnetwrok.pyのコードとテキストのコードは少々違っています。
Gitクローンの方にはsigmoid_vecとかsigmoid_prime_vecとかの関数は使われていません、ただ、実行に問題はないです。
テキスト版のコードはGitHubにもうないので廃止されたのかも….。
ニューラルネットワークと深層学習に記述されているコードです(Python3.x版)
ubuntu 16.04 LTS + Python 3.xの環境の場合
数字を分類するニューラルネットワークの実装をやってみる2-1
(Pyhon3.xではmnist_loaderとnetworkのコードで若干修正が必要です)
Next
上記の学習用コードはCode repositoryにあるnetwork.pyのものです。
また、network3.pyにはTheanoを使った畳み込みネットワークのコードがあります。
ニューラルネットワークと深層学習の6章で使われていますが、ここには問題として「ネットワークを記録、再生する機能をnetwork3.pyに加えてください」というのがあります、これをやってみる予定(ちなみに、SaveとLoadのコードはnetwork2.pyで定義されています、これを参考にします)。
WisteriaHillは「さくらインターネット」の共用サーバーにお世話になっていますが、ここにはGPUを時間貸ししてくれるサービス(Tesla P40モデル)があります(さくら 高火力サーバー)。
1時間あたり300円前後だったと思います。
どうしてもGPUがいるんじゃぁ….という場合はこれを使うことにします。
AWSやGCP、Azure、FloydHub以外の選択肢です。
無料で使えます(研究用にってことで)
Leave a Reply