
ラズパイ3 + Julius では音声出力は、用意しておいたwavファイルをaplayで出力していただけでしたが、この出力の部分に、音声合成エンジンのOpenJTalkを使ってみます。
日本語音声合成はOSS界隈ではいくつかあります(Merlin とか)。深層学習を使ったものもありますが、ここはひとつ安定のOpenJTalkということで。

準備
出力周りを確認します。
ラズパイの音声出力は2系統あります。
ステレオミニジャックとHDMIです。
USBスピーカーを使う場合はステレオミニジャックになります。
ただし、USBのスピーカーとマイク一体型(ヘッドセット)はこんな感じ
カード番号とデバイス番号を調べます。
$aplay -l
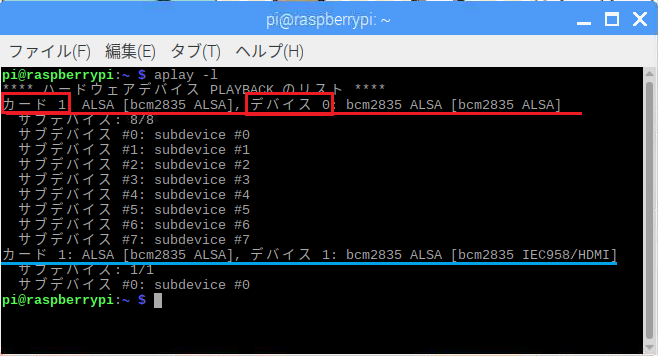
ステレオミニジャックのカード番号は1、デバイス番号は0です。
テストで以下が聞こえたらOK
$ aplay -Dhw:1,0 /usr/share/sounds/alsa/Front_Center.wav
注:
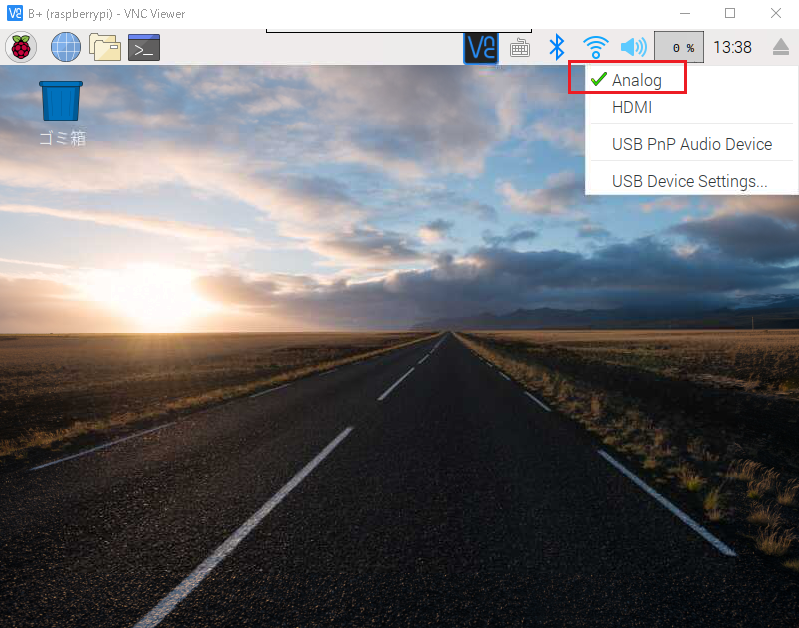
ミニジャックに接続したスピーカーから音が出ない場合
ここもチェック。
スピーカーアイコンを右クリック。
インストール
$ sudo apt-get update
$ sudo apt-get install open-jtalk
他の提案パッケージもインストールします。
$ sudo apt-get install open-jtalk-mecab-naist-jdic hts-voice-nitech-jp-atr503-m001
やってみます
$ echo “これはテストです” | open_jtalk -m /usr/share/hts-voice/nitech-jp-atr503-m001/nitech_jp_atr503_m001.htsvoice -x /var/lib/mecab/dic/open-jtalk/naist-jdic -ow ./open_jtalk_tmp.wav
$ aplay open_jtalk_tmp.wav
使っている音響モデル
/usr/share/hts-voice/nitech-jp-atr503-m001/nitech_jp_atr503_m001.htsvoice
辞書
/var/lib/mecab/dic/open-jtalk/naist-jdic
音響モデルを変えてみます。
***.htsvoiceファイルをダウンロードしたら
/home/pi/voiceというフォルダーを作って、そこに置いておきます。
で、やってみます。
$ echo “それはないわ” | open_jtalk -fm 0.55 -a 0.5 -jf 3.0 -r 1 -m /home/pi/voice/mei_happy.htsvoice -x /var/lib/mecab/dic/open-jtalk/naist-jdic -ow ./open_jtalk_mei.wav
$ aplay open_jtalk_mei.wav
声が気に入らなかったら触ってみるパラメーター
「a: all-pass constant」(オールパス値)
「b: postfiltering coefficient」(ポストフィルター係数)
「r: speech speed rate<strong」(スピーチ速度係数)
「fm :additional half-tone」(追加ハーフトーン)
「u: voiced/unvoiced threshold」(有声/無声境界値)
「jm: weight of GV for spectrum」(スペクトラム系列内変動の重み)
「jf: weight of GV for log F0」(F0系列内変動の重み)
Pythonのサンプルコードはこんな感じ。
wavファイルを作ってから出力する場合
【talk.py】
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
#!/usr/bin/env python3 #coding: utf-8 import sys import subprocess def jtalk(g,t): open_jtalk = ['open_jtalk'] dict = ['-x','/var/lib/mecab/dic/open-jtalk/naist-jdic'] if(g == 'female'): htsvoice = ['-m','/home/pi/voice/mei_happy.htsvoice'] elif(g == 'male'): htsvoice = ['-m','/usr/share/hts-voice/nitech-jp-atr503-m001/nitech_jp_atr503_m001.htsvoice'] halftone = ['-fm','0.55'] allpass = ['-a','0.5'] gvweight4fo = ['-jf','3.0'] speed = ['-r','1.0'] volume = ['-g','15.0'] #version 1.09以上 outwav = ['-ow','temp.wav'] cmd = open_jtalk + dict + htsvoice + speed + halftone + allpass+ volume + gvweight4fo + outwav p = subprocess.Popen(cmd,stdin=subprocess.PIPE) p.stdin.write(t.encode('utf-8')) p.stdin.close() p.wait() aplay = ['aplay','-q','temp.wav','-Dhw:1,0'] wr = subprocess.Popen(aplay) def main(): args = sys.argv gender = args[1] text = args[2] jtalk(gender,text) if __name__ == '__main__': main()$ |
|
1 2 |
$python3 jtalk.py 'female' 'あなたのおなまえは?' $python3 jtalk.py 'male' 'きみのなは?' |
スピーカーの音量調整
$amixer set PCM n%
n ->60~100
この範囲でレベルを設定してチェックしてみます。
$aplay /usr/share/sounds/alsa/Front_Center.wav
最新版インストール
sudo apt-get install open-jtalkでインストールするとVer1.07が入ってしまいます。
1.07では音量オプション(-g)が使えない。
2019/02/17現在、最新版は1.11
1.07をインストール済みの場合は削除しておきます。
|
1 |
$sudo apt-get purge open-jtalk |
まず、hts_engine_APIをインストール(これが無いとOpenJTalkのMakefileが作成されない)
|
1 2 3 4 5 6 7 8 9 10 11 |
$cd /home/pi $wget http://downloads.sourceforge.net/hts-engine/hts_engine_API-1.10.tar.gz $tar zxvf hts_engine_API-1.10.tar.gz $cd hts_engine_API-1.10 $./configure $make |
OpenJTalkを導入
|
1 2 3 4 5 6 7 |
$cd /home/pi $wget http://downloads.sourceforge.net/open-jtalk/open_jtalk-1.11.tar.gz $tar zxvf open_jtalk-1.11.tar.gz $cd open_jtalk-1.11 |
Makefile作成
|
1 2 3 4 5 |
$./configure --with-charset=UTF-8 --with-hts-engine-header-path=/home/pi/hts_engine_API-1.10/include --with-hts-engine-library-path=/home/pi/hts_engine_API-1.10/lib $make $sudo make install |
確認
|
1 2 |
$cd /home/pi $open_jtalk |
1.07の辞書でもOKなので必須というわけではないですが…….
|
1 2 3 4 5 |
$wget http://tenet.dl.sourceforge.net/project/open-jtalk/Dictionary/open_jtalk_dic-1.11/open_jtalk_dic_utf_8-1.11.tar.gz $tar zxvf open_jtalk_dic_utf_8-1.11.tar.gz $sudo cp -r open_jtalk_dic_utf_8-1.11 /var/lib/mecab/dic |
$ sudo apt-get install open-jtalk-mecab-naist-jdic hts-voice-nitech-jp-atr503-m001
こんな構成の場合
USBタイプのマイク・スピーカー一体型(ヘッドセット)
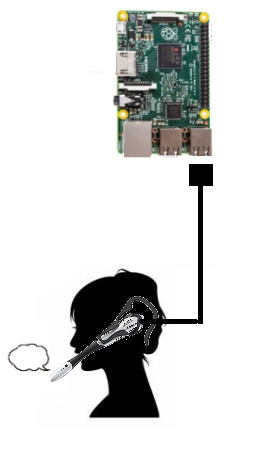
$aplay -l
で、[USB Audio]のカード番号とデバイス番号をチェック
例
カード番号=0、デバイス番号 = 0の場合
$ aplay -D plughw:0,0 xxx.wav
モノラル音源がいいかも…。
Appendex
複数のwavを連結する場合
soxを使います。
$sudo apt-get install sox
$sox s1.wav s2.wav …. out.wav
Pythonの場合
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
#!/usr/bin/env python3 # -*- coding: utf-8 -*- import wave def join_waves(inputs, output): try: fps = [wave.open(f, 'r') for f in inputs] fpw = wave.open(output, 'w') fpw.setnchannels(fps[0].getnchannels()) fpw.setsampwidth(fps[0].getsampwidth()) fpw.setframerate(fps[0].getframerate()) for fp in fps: fpw.writeframes(fp.readframes(fp.getnframes())) fp.close() fpw.close() except: print("error") if __name__ == '__main__': wav_list = ['/home/pi/tmp/00.wav','/home/pi/tmp/01.wav','/home/pi/tmp/02.wav','/home/pi/tmp/03.wav'] output_wav = '/home/pi/tmp/out.wav' join_waves(wav_list, output_wav) |
|
1 |
Leave a Reply