Scikit-Learnのcheat-sheetは使用するデータの内容と目的に応じて、どのアルゴリズムを使えばいいのか教えてくれます。
cheat-sheet:チート・シート:カンニングペーパーあるいは虎の巻…というくらいの意味
一部を日本語化してみました。
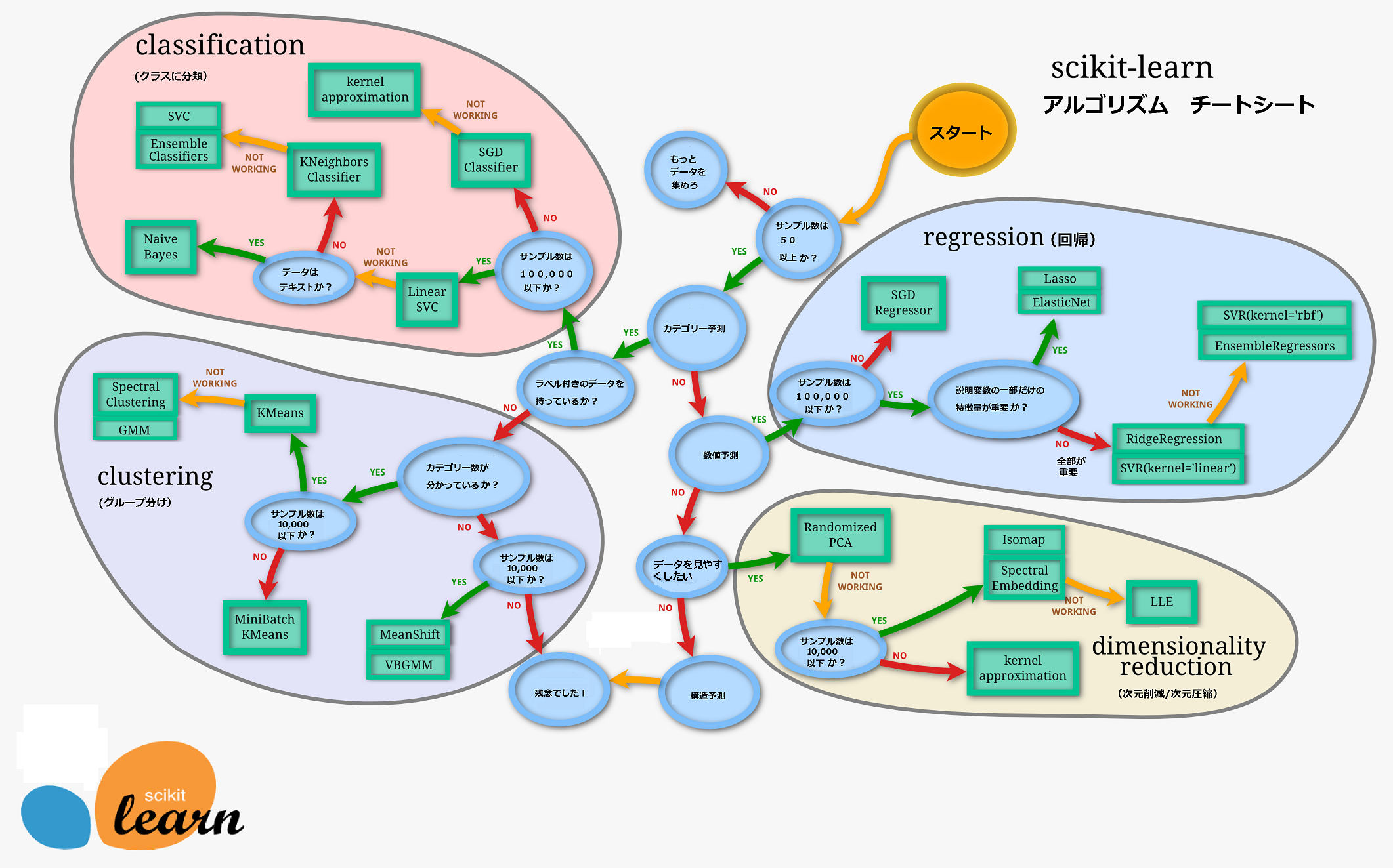
アルゴリズム一覧
classfication(クラス分類)
SGD(確率的勾配降下法) Classifier —- 線形なクラス分類
Kernel approximation(カーネル近似) —- 非線形なクラス分類
KNeighbors(K近傍法) Classifier —- 非線形なクラス分類
SVC(SVM Classification) –> Kernel SVC —- 非線形なクラス分類
Ensemble Classifier —- 非線形なクラス分類
Linear SVC —- 非線形なクラス分類
Naive Bayes(ナイーブベイズ)
regression(回帰)
線形
SGD Regression
Lasso
ElasticNet
SVR(kernel=’linear’)
非線形
SVR(サポートベクター回帰)(kernel=’rbf’)
EnsembleRegressors
RidgeRegression
clustering(グループ分け)
MeanShift
VBGMM
KMeans(K平均法)— 基本
MiniBatch KMeans
Spectral Clustering
GMM
dimensionality reduction(次元削減/次元圧縮)
Randomized PCA
Ispmap
Spectral Embedding
Kernel approximation(カーネル近似)–> Kernel PCA
LLE
このビデオ・レッスンでは非常に単純なデータを使っています。
だれでもできそうです。自分のデータを作ってやってみましょう。
参考までによく使われるデータのサンプルはこんな感じ。
classfication(クラス分類)
UC Irvine Machine Learning Repository から参照
regression(回帰)
Excel持っていれば、データファイルにはCSVが使えます。
scikit-learnではこいうデータはすでに用意されています。sklearn.datasetsで使えます。
各アルゴリズムを実装してみたい向きは、この方のブログをご参照ください。
Next
チート・シートの分岐の目安のデータ数はあくまでただの目安です。
データが少なくてもアルゴリズムの実行自体は可能です。。
Pythonで記述することで、各アルゴリズムが何をやっているのか見当をつけてみます。
やってみましょう
線形回帰やロジスティック回帰などの基本的なアルゴリズムをYoutubeのビデオレッスンで分かった気になろう(^^)…..理論と実装の両方で説明してくれます
その他のチート・シート(Scikit-Learnのcheat-sheetは少し古めです、以下のcheat-sheetでは新しめのアルゴリズムも使われています)
Microsoft Azureのチート・シート 、 日本語版
Leave a Reply