GoogleのColaboratoryをお借りしてこのテキストのコードとこのテキストのコードをやってみます。
ColaboratoryとJetson Nanoの実行速度を比較してみます(無謀ですが)
CPUのみで、フレームワークを使わずスクラッチから実装するパターン
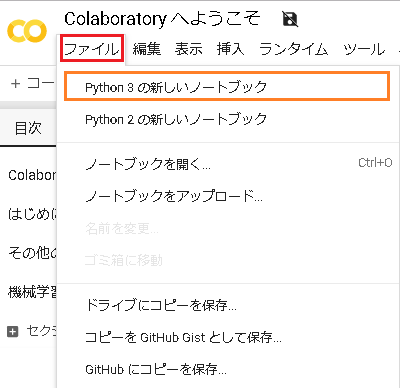
左のペインを開きます
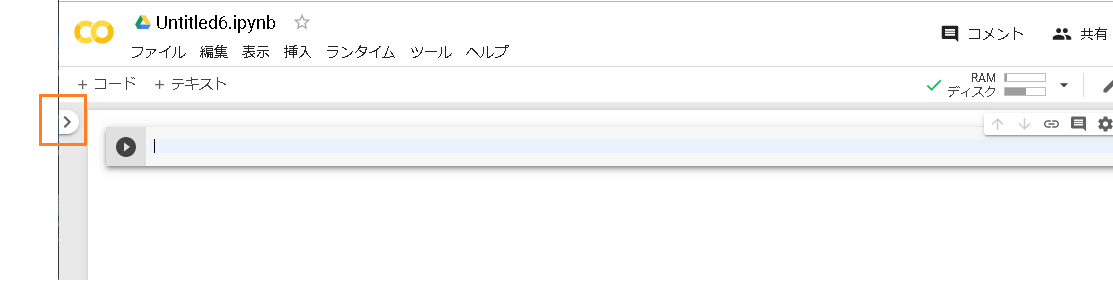
ファイルを選んで、ランタイムに接続します。
割り当て->接続->初期化
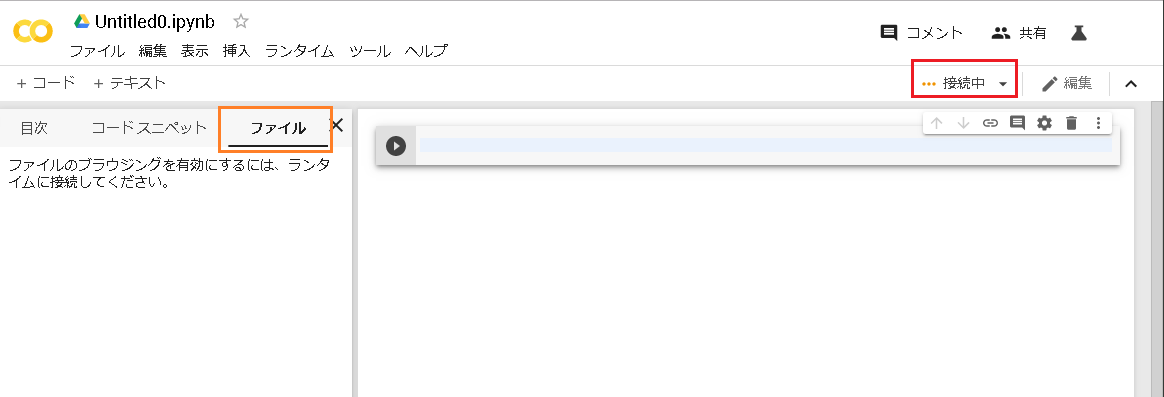
/contentが初期ディレクトリです。
必要なら新規にディレクトリーを作成して、対象のディレクトリーにファイルをアップロードします
新規にディレクトリを作るシェルコード
!mkdir src
ソースとデータのサンプルのnetwork2.pyとmnist_loader.pyを使います
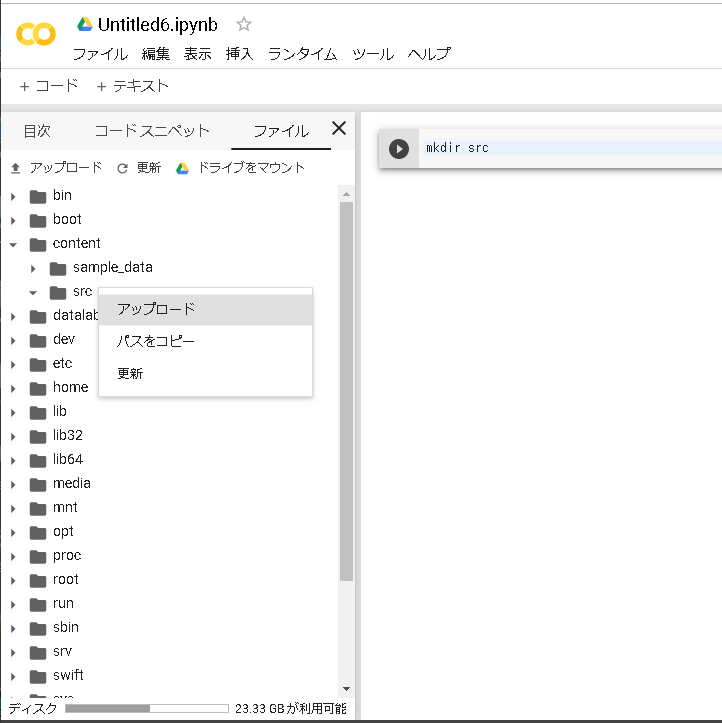
実行はソースをアップロードした/content/srcで行うので移動
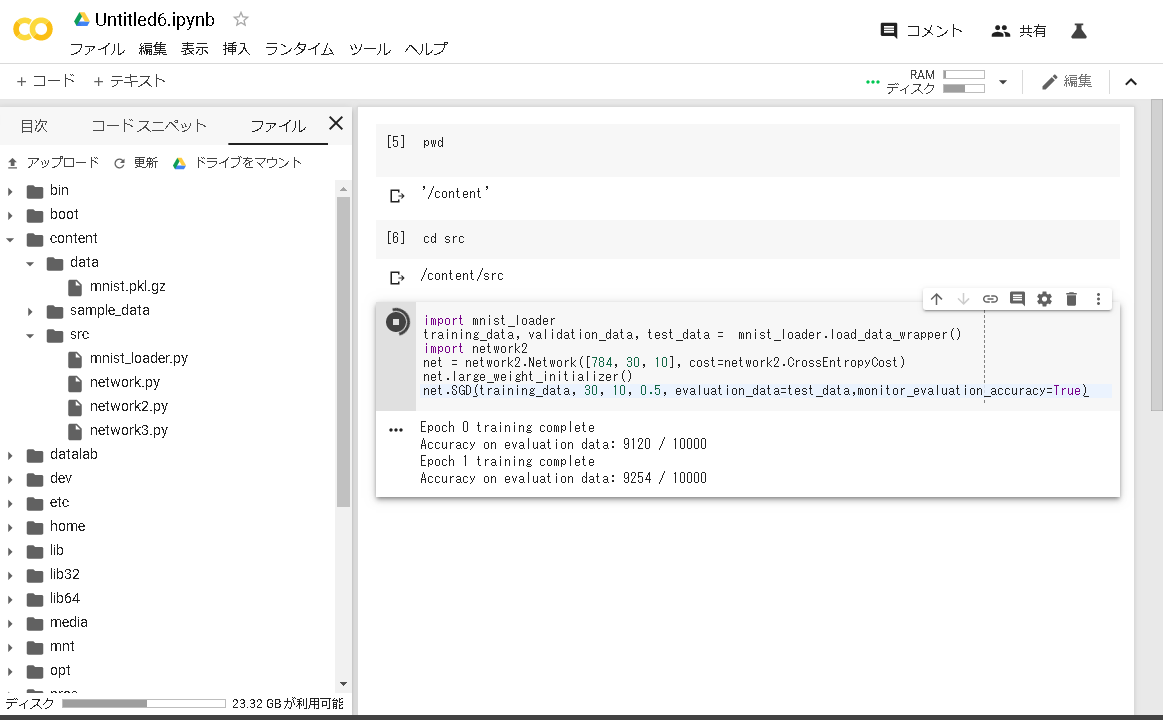
%cd /content/src
セルで以下を実行
|
1 2 3 4 5 6 7 |
import mnist_loader training_data, validation_data, test_data = mnist_loader.load_data_wrapper() import network2 net = network2.Network([784, 30, 10], cost=network2.CrossEntropyCost) net.large_weight_initializer() net.SGD(training_data, 30, 10, 0.5, evaluation_data=test_data,monitor_evaluation_accuracy=True) |
1EpochにつきColabで10秒くらい、Jetsonだと47秒くらいでした。
ではGPUを使ってみます。Theanoフレームワークを使います。
新規のNotebook
ランタイムを選んで「ランタイムのタイプを変更」
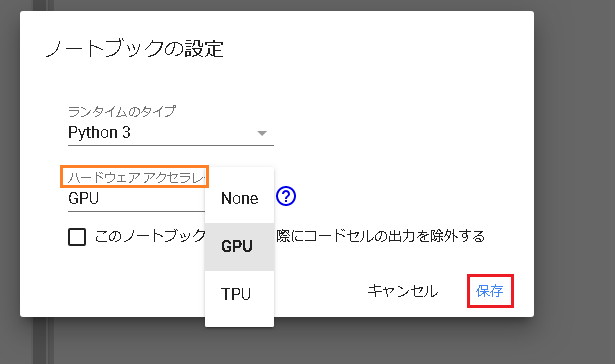
ハードウェアアクセラレータでGPUを選んで保存
確認
import tensorflow as tf
tf.test.gpu_device_name()
‘/device:GPU:0’
数字を分類するニューラルネットワークの実装をやってみる2-3から
まず、
network3.pyで100のニューロンを含む隠れ層を1つだけを持つ浅いネットワークを
エポック数60、学習率0.1、ミニバッチサイズ10、正規化なしの条件で実行してみます。
このソースではフレームワーク(Theano)を使い、外部のデータセット(mnist.pkl.gz)を呼んで実行してます。
src/network3.pyとdata/mnist.pkl.gzをディレクトリを作ってアップロードしておきます。
ディレクトリを移動
%cd /content/src
セルで以下を実行
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import network3 from network3 import Network from network3 import ConvPoolLayer, FullyConnectedLayer, SoftmaxLayer training_data, validation_data, test_data = network3.load_data_shared() mini_batch_size = 10 net = Network([FullyConnectedLayer(n_in=784, n_out=100),SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size) net.SGD(training_data, 60, mini_batch_size, 0.1,validation_data, test_data) |
注
Theanoが使う線形代数演算ライブラリ(BLAS)が見当たらないというメッセージがでるかも。
ただ実行は問題ないです。
ここをクリック
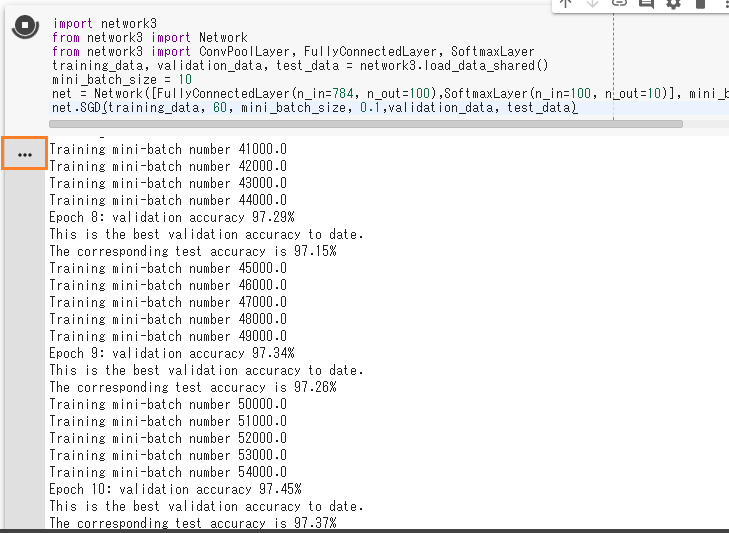
1EpochにつきColabで2秒くらい、Jetsonだと17秒くらいでした。
GPUの威力(2019/09/02 現在のGPUはNVIDIATesla k80 12GB)
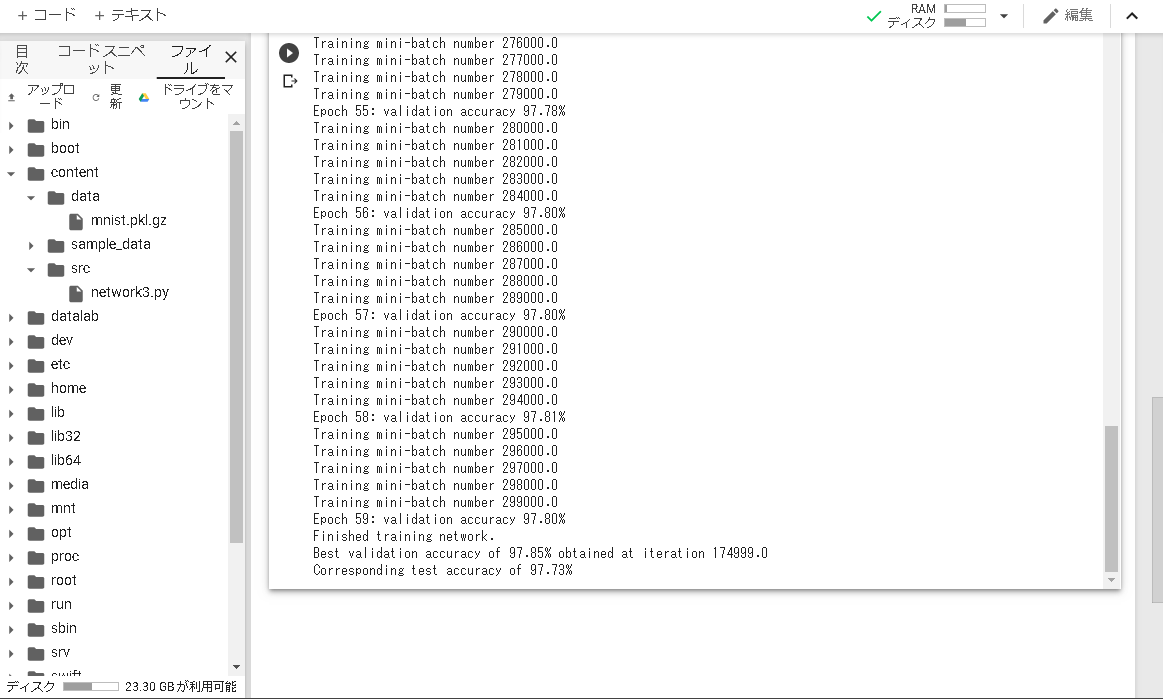
最後に数字を分類するニューラルネットワークの実装をやってみる2-3のTrial-7
結果を改良する別の手法としての訓練データの拡張を行い
サイズの大きな全結合層を追加してみて
ドロップアウトを全結合層に適用してみる、訓練のエポック数 40、全結合層内のニューロン数 1,000
上と同様に、新規でNotebookを開いてGPUを適用
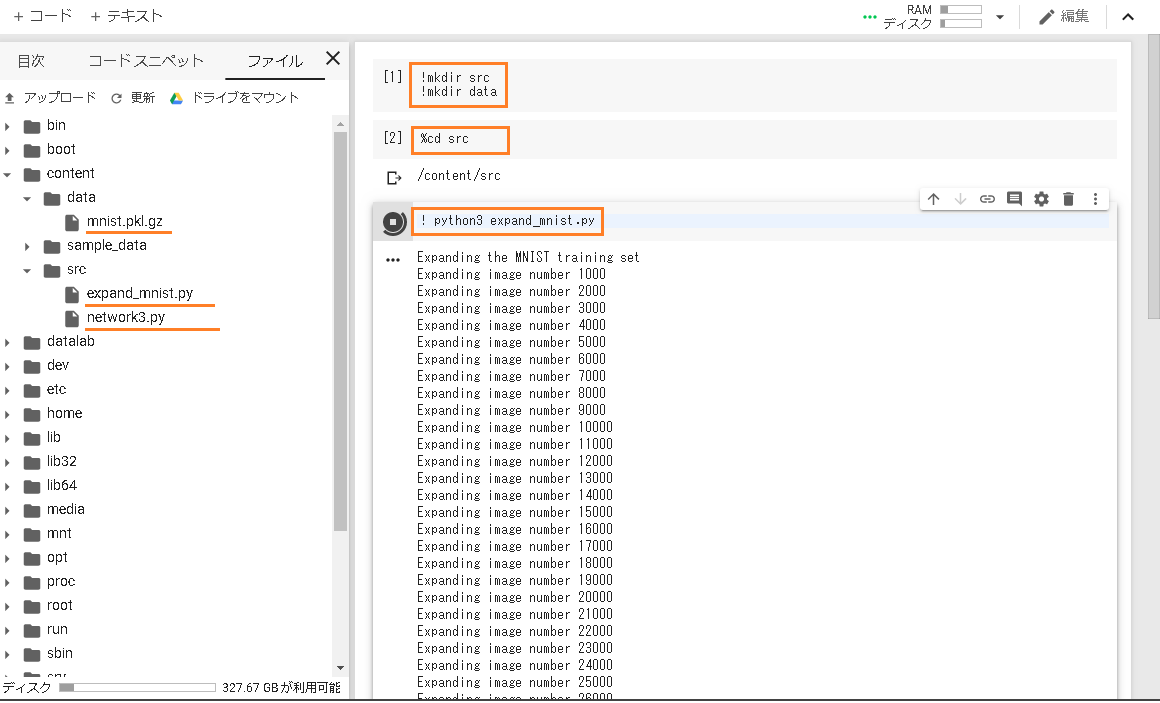
データとソースをアップロードしてデータの拡張を実行
! python3 expand_mnist.py
セルで以下を実行
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import network3 from network3 import ReLU from network3 import Network from network3 import ConvPoolLayer, FullyConnectedLayer, SoftmaxLayer mini_batch_size = 10 training_data, validation_data, test_data = network3.load_data_shared() expanded_training_data, _, _ = network3.load_data_shared( "../data/mnist_expanded.pkl.gz") net = Network([ ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28), filter_shape=(20, 1, 5, 5), poolsize=(2, 2), activation_fn=ReLU), ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12), filter_shape=(40, 20, 5, 5), poolsize=(2, 2), activation_fn=ReLU), FullyConnectedLayer( n_in=40*4*4, n_out=1000, activation_fn=ReLU, p_dropout=0.5), FullyConnectedLayer( n_in=1000, n_out=1000, activation_fn=ReLU, p_dropout=0.5), SoftmaxLayer(n_in=1000, n_out=10, p_dropout=0.5)], mini_batch_size) net.SGD(expanded_training_data, 40, mini_batch_size, 0.03, validation_data, test_data) |
1EpochにつきColabで13分30秒くらい、Jetsonだと54分くらいでした。
面倒なので途中で切り上げましたが、40エポック実行するのに
Colabで9時間、Jetsonで36時間かな?
ちなみに、Colabの時間制限は連続使用で12時間です。
ColabとJetson Nano で SSD-Mobilenet の転移学習をやってみます。
Jetson Nanoで学習済みモデルを使って、いろいろやってみる(2-2)転移学習(SSD-Mobilenet)
Appendix
Colab の環境チェック
GPU
上記の「ハードウェアアクセラレータでGPUを選んで保存」した場合のみnvidia-smiコマンドで情報を取得できます。
|
1 |
!nvidia-smi |
CPU
|
1 |
!cat /proc/cpuinfo |
OS
|
1 |
!cat /etc/os-release |
Pythonのバージョン
|
1 2 |
import sys print(sys.version) |
パッケージ情報
|
1 2 3 4 5 |
#OS !dpkg -l #Python !pip list |
メモリ
|
1 |
!cat /proc/meminfo |
ディスク
|
1 |
!df -hP |
Leave a Reply