
「型落ちPCのCPUのみで、量子化した7B(70億)パラメータのLLMを動かしてみる」では量子化済みのcalm2-7b-chat.Q2_K.ggufをダウンロードして使っていました。
ここではHuggingFaceにアップしてあるcyberagent/calm2-7b-chatをggufに変換後、q2_K型に量子化してから使ってみます。
環境は前と同様に型落ちPCでRAMを10GBに拡張したものを使います。

OSはUbuntu Server 22.04.3 LTS です。
OSをインストールして起動したら、必要なパッケージやライブラリなどをインストール。
|
1 2 3 4 |
sudo apt -y update sudo apt upgrade -y sudo apt install build-essential pkg-config libopenblas-dev -y |
pipが未インストールなら以下を実行しておきます。
|
1 2 3 |
sudo apt install python3-pip -y python3 -m pip install --upgrade pip |
トークナイズ用にsentencepieceをpipでインストールします。
|
1 |
pip3 install sentencepiece |
BLASを使うのでllama.cppを新たにインストールします。以前にmakeのみでビルドしたllama.cppはフォルダーごと削除しておいてください。
|
1 2 3 4 5 6 7 |
mkdir llama.cpp curl -L https://github.com/ggerganov/llama.cpp/archive/refs/tags/b1620.tar.gz | tar zx -C llama.cpp --strip-components=1 cd ~/llama.cpp make -j4 LLAMA_OPENBLAS=1 |
ダウンロードファイル用のディレクトリを作成しておきます。
|
1 2 |
cd ~/ mkdir -p models/hf models/gguf |
HuggingFaceから cyberagent/calm2-7b-chatをダウンロードします。
python3 -c 'import huggingface_hub; huggingface_hub.snapshot_download(repo_id="cyberagent/calm2-7b-chat", cache_dir="./models/hf")'
ダウンロードフォルダーへ移動。
cd ~/models/hf/models--cyberagent--calm2-7b-chat/snapshots/f666a1e43500643cb3ff8c988a6ea5b56afe934a
こんな感じ。
python でvocab.json(頻度の高いトークンのリスト)を作成します。
>python3
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
from transformers import AutoTokenizer import json with open("./config.json", "r") as config_file: config = json.load(config_file) tokenizer = AutoTokenizer.from_pretrained("./") vocab = tokenizer.vocab if config["vocab_size"] > tokenizer.vocab_size: META_TOKEN = "▁▁" for i in range(config["vocab_size"] - tokenizer.vocab_size): token = "{}{}".format(META_TOKEN, i) vocab[token] = tokenizer.vocab_size + i with open("vocab.json", "w") as vocab_file: json.dump(vocab, vocab_file) |
llama.cppフォルダーのトップへ移動
|
1 |
cd ~/llama.cpp |
GGUFファイルを作成します。
python3 convert.py --vocabtype bpe --outfile ~/models/gguf/calm2-7b-chat.gguf ~/models/hf/models--cyberagent--calm2-7b-chat/snapshots/f666a1e43500643cb3ff8c988a6ea5b56afe934a
q2_k型で量子化実行。
|
1 |
./quantize ~/models/gguf/calm2-7b-chat.gguf ~/models/gguf/calm2-7b-chat-q2_k.gguf q2_k |
同じような調子で、4-bit(q4_0)や5-bit(q5_k_m)などで量子化しておけば比較できます。
例によって「日本で一番高い山はどこですか?」と尋ねてみます。
初回はモデルの読み込みもあって若干時間がかかります。
|
1 2 |
./main -m ~/models/gguf/calm2-7b-chat-q2_k.gguf -n 500 -p "USER:日本で一番高い山はどこですか? ASSISTANT: " |
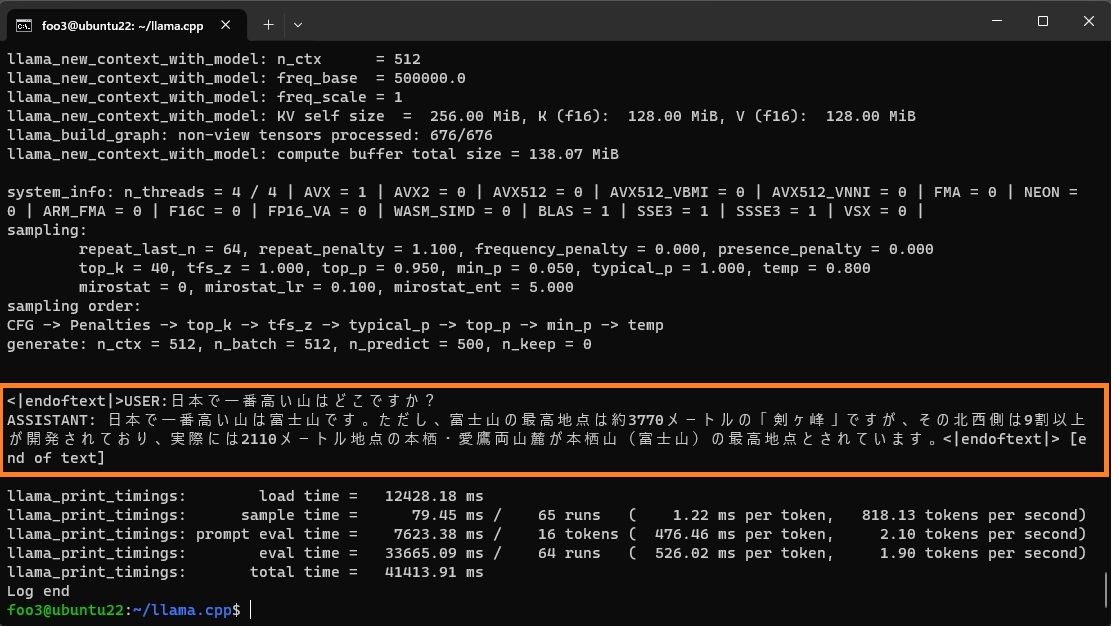
2回目以降はスムースです。
2~3秒のタイムラグで応答が返ってきました。
|
1 2 |
./main -m ~/models/gguf/calm2-7b-chat-q2_k.gguf -n 500 -p "USER:雨降りの準備はどうしたらいいですか? ASSISTANT: " |
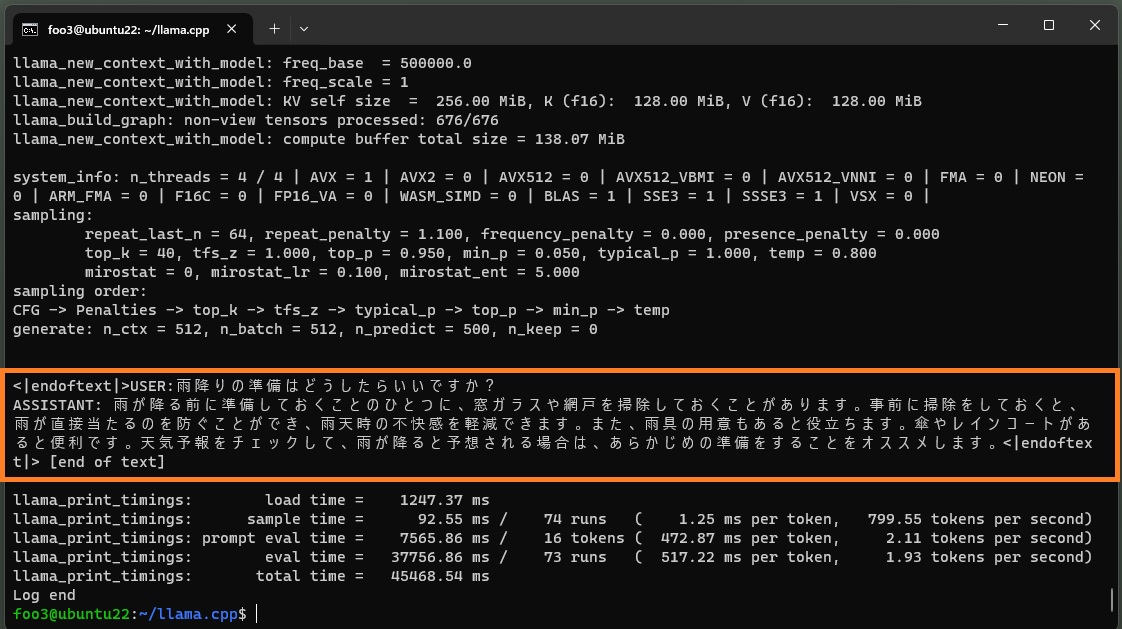
ちなみに4-bit量子化(q4_0型)したものでは、こういう応答になります。
|
1 2 |
./main -m ~/models/gguf/calm2-7b-chat-q4_0.gguf -n 500 -p "USER:日本で一番高い山はどこですか? ASSISTANT: " |
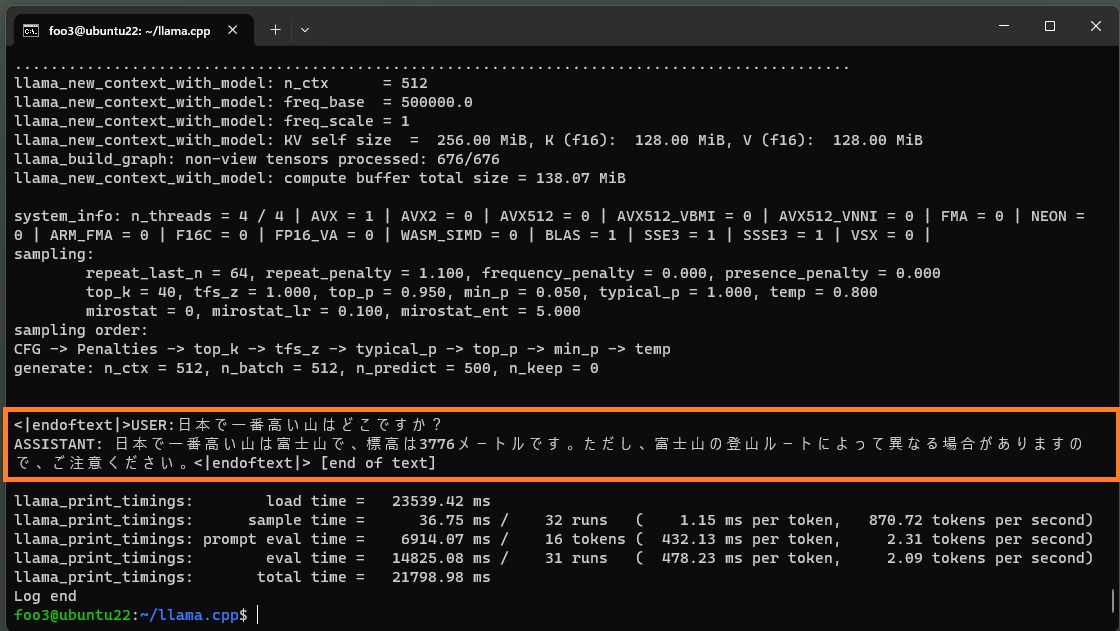
こういう答えを返すこともあります。
もはやファンタジーですが、妙に納得する人もいるかもしれません。
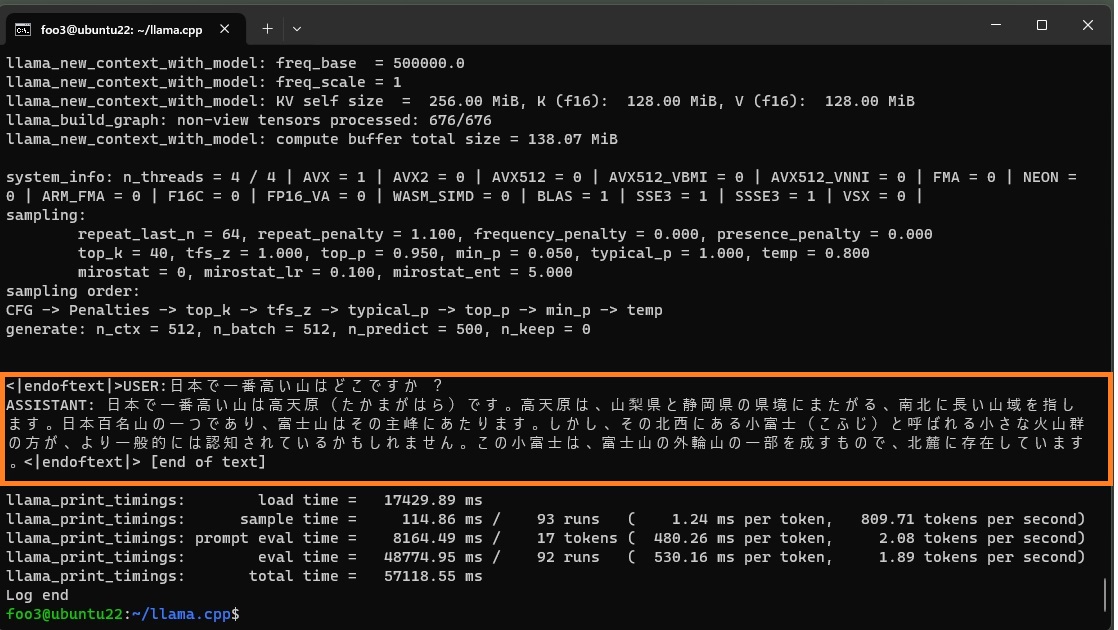
Appendix
他のモデルについて
●Rinna
rinna/youri-7b-chatでは.quantizeでエラー
error loading model: ERROR: byte not found in vocab
●ELYZA
elyza/ELYZA-japanese-Llama-2-7b-fast-instructでは.mainでエラー
GGML_ASSERT: llama.cpp:2695: codepoints_from_utf8(word).size() > 0
Aborted (core dumped)
このページでディスカッションされていますが、解決策は未だなし
Appendix2
HuggingFace Hub リンク
elyza/ELYZA-japanese-Llama-2-7b
量子化済み ELYZA-japanese-Llama-2-7b-fast-instruct
量子化済み rinna-youri-7b-chat
量子化済み cyberagent-open-calm-3b
量子化済み RakutenAI-7B-chat
Appendix3
今回、量子化を実行するに当たってllama.cpp をBLASオプション付きでビルドしました。
ただmainコマンドで推論を実行するだけなら、前回クローンしてmakeのみで作ったmainでも可能です。
また、今回使ったプアなPC環境でもオリジナルのggufファイルは実行は可能ですが、実用には程遠い遅さです。
Next
7Bのモデルをラズパイ5 – 8GB で動かしてみる
ラズパイ5(8GB)で、日本語対応の7B(70億)パラメータのLLMを量子化して使ってみる
Leave a Reply