
ラズパイ3+Juliusで音声認識 の続編…..みたいなもんです。
音声認識エンジンのJulius がVersion 4.6になってGPU対応になりました。
まぁ、それでJetson Nanoでやってみようかなと。
エッジレベルで使う日本語音声認識エンジンは2020/12/05現在、Julius 一択だと思われます。
MozillaのDeep Speechに期待しますが.

依存パッケージやモジュールをインストールしておきます
|
1 |
sudo apt install build-essential zlib1g-dev libsdl2-dev libasound2-dev git-lfs |
ソースコードをクローンしておきます(ver 4.6)
|
1 |
git clone https://github.com/julius-speech/julius.git |
config.guessとconfig.subが古いので、最新版に更新
以下から参照してファイルにしておきます。
config.guess
https://git.savannah.gnu.org/gitweb/?p=config.git;a=blob_plain;f=config.guess
config.sub
https://git.savannah.gnu.org/gitweb/?p=config.git;a=blob_plain;f=config.sub
ファイルにする場合は、UTF-8(BOM無し)で、改行はLFのみのUNIX形式にしておきます。
でないと以下のようなエラーが発生します。
configure: error: cannot run /bin/bash support/config.sub
checking build system type… support/config.guess: line 4: $’\r’: command not found
この2つのファイルを対象ディレクトリの同名ファイルに上書きします。
|
1 2 3 4 5 6 7 8 9 10 11 |
sudo cp config.guess ~/julius/adintool/ sudo cp config.guess ~/julius/jcontrol/ sudo cp config.guess ~/julius/support/ sudo cp config.guess ~/julius/msvc/Library_PortAudio/src/ sudo cp config.guess ~/julius/msvc/Library_PortAudio/src/bindings/cpp/build/gnu/ sudo cp config.sub ~/julius/adintool/ sudo cp config.sub ~/julius/jcontrol/ sudo cp config.sub ~/julius/support/ sudo cp config.sub ~/julius/msvc/Library_PortAudio/src/ sudo cp config.sub ~/julius/msvc/Library_PortAudio/src/bindings/cpp/build/gnu/ |
Juliusインストール
クローンしておいたフォルダーに移動します。
|
1 |
cd ~/julius |
リリースノート(日本語)にあるようにcudaのnvccでビルドします。
JetpackにはCUDAもCUDA toolkit もプレセットされています。現バージョンではcudaは以下の場所にあります。
|
1 |
/usr/local/cuda-10.2 |
cinfigureを以下のように構成
|
1 |
env CC=/usr/local/cuda-10.2/bin/nvcc CFLAGS=-O3 ./configure --enable-words-int |
ビルド実行
|
1 |
make -j4 |
juliusディレクトリでビルドを確認
|
1 |
ls -l julius/julius |
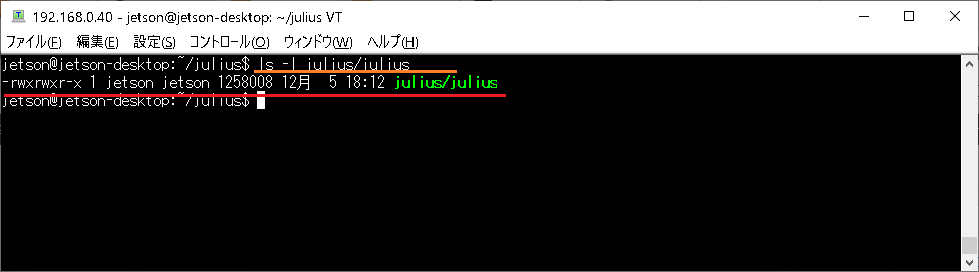
Julius Japanese Dictation-kitのインストール
git-lfsのインストール
|
1 |
git lfs install |
Dictation kitのソースコードをクローンしておきます。
|
1 |
git clone https://github.com/julius-speech/dictation-kit.git |
音声認識
USB接続のマイクを使います。
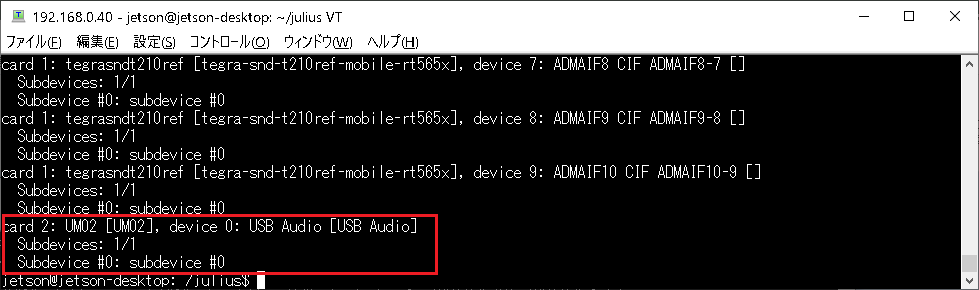
このマイクの番号を確認
|
1 |
arecord -l |
以下の例では、カード番号2、デバイス番号は0です。
新規ファイル .profileに記述します
sudo nano .profile
|
1 |
export ALSADEV="plughw:2,0" |
読み直します
source .profile
Juliusを起動
~/julius/julius/julius -C ~/julius/dictation-kit/main.jconf -C ~/julius/dictation-kit/am-gmm.jconf -nostrip
<<<Please Speak>>>が出たらマイクに発話

シェルスクリプト
【julius.sh】
|
1 2 3 |
#!/bin/bash source .profile ~/julius/julius/julius -C ~/julius/dictation-kit/main.jconf -C ~/julius/dictation-kit/am-gmm.jconf -nostrip |
実行権
|
1 |
sudo chmod u+x julius.sh |
実行
|
1 |
./julius.sh |
どのくらい精度を上げられるか検証
工事中
Leave a Reply