
先に公開されていた楽天のLLM (RakutenAI-7B-chat) を試してみます。このオリジナルのモデルと量子化モデルをColabとラズパイ5(8GB)で動作させてみます。
なおColabではオリジナルと量子モデルの両方、ラズパイ5(8GB)ではHuggingFaceにあるmmngaさんの量子化モデルをいろいろなパターンで動かしてみます。
Colab
Google Colab にアクセス
- ファイルー>ノートブックを新規作成。
- 編集ー>ノートブックの設定でT4 GPU にチェックを入れて保存(量子化用に使います)。
- 右メニュの「接続」をクリックしてランタイムに接続します。
Free Colab スペック(2024/04/16 現在)
OS:Ubuntu 22.04.3 LTS (Jammy Jellyfish)
CPU:Intel(R) Xeon(R) CPU @ 2.20GHz
GPU:Tesla T4 almost 15GBs ( CUDA version 12.2 )
RAM:12Gi
Python 3.10.12 (main, Nov 20 2023, 15:14:05) [GCC 11.4.0]
セルに以下をコピペして実行します。
● パッケージのインストール
bitsandbytesは量子化の際に必要なライブラリですが一緒にインストールしておきます。個別にインストールするとUTF-8 localeエラーが起こるようです。
|
1 |
!pip install -U transformers accelerate bitsandbytes |
● ライブラリの読み込み
|
1 |
from transformers import AutoModelForCausalLM, AutoTokenizer,BitsAndBytesConfig |
● トークナイザーの準備
|
1 2 3 |
tokenizer = AutoTokenizer.from_pretrained( "Rakuten/RakutenAI-7B-chat" ) |
● モデルの準備
|
1 2 3 4 5 6 |
model = AutoModelForCausalLM.from_pretrained( "Rakuten/RakutenAI-7B-chat", torch_dtype="auto", device_map="auto" ) model.eval() |
● 推論の実行
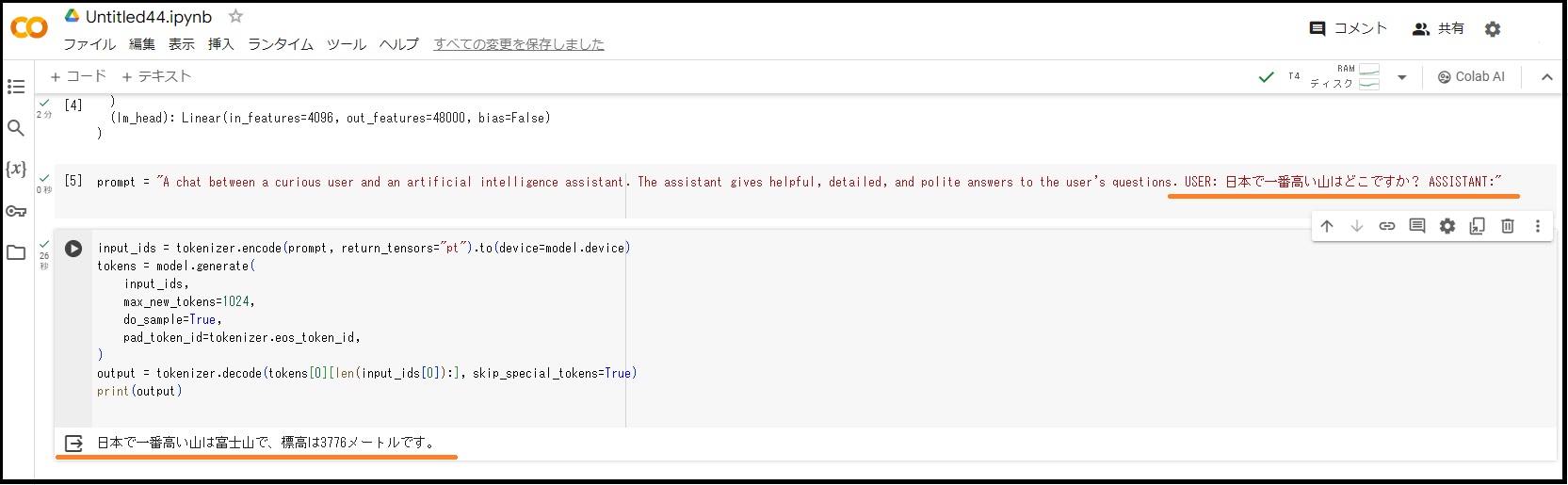
今回のプロンプトは「日本で一番高い山はどこですか?」です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# プロンプトの準備 prompt = "A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: 日本で一番高い山はどこですか? ASSISTANT:" # 推論の実行 input_ids = tokenizer.encode(prompt, return_tensors="pt").to(device=model.device) tokens = model.generate( input_ids, max_new_tokens=1024, do_sample=True, pad_token_id=tokenizer.eos_token_id, ) output = tokenizer.decode(tokens[0][len(input_ids[0]):], skip_special_tokens=True) print(output) |
結果
7Bサイズのモデルでもちゃんと答えてくれます。
では、今度はモデルを量子化してやってみます。
● 量子化設定
8bitの場合
|
1 2 3 |
quantization_config = BitsAndBytesConfig( load_in_8bit=True ) |
4bitの場合
|
1 2 3 |
quantization_config = BitsAndBytesConfig( load_in_4bit=True ) |
● モデルの準備
|
1 2 3 4 5 6 7 8 9 |
repo_id = "Rakuten/RakutenAI-7B-chat" model = AutoModelForCausalLM.from_pretrained( pretrained_model_name_or_path=repo_id, device_map={"": 'cuda:0'}, quantization_config=quantization_config ) model.eval() |
● プロンプト
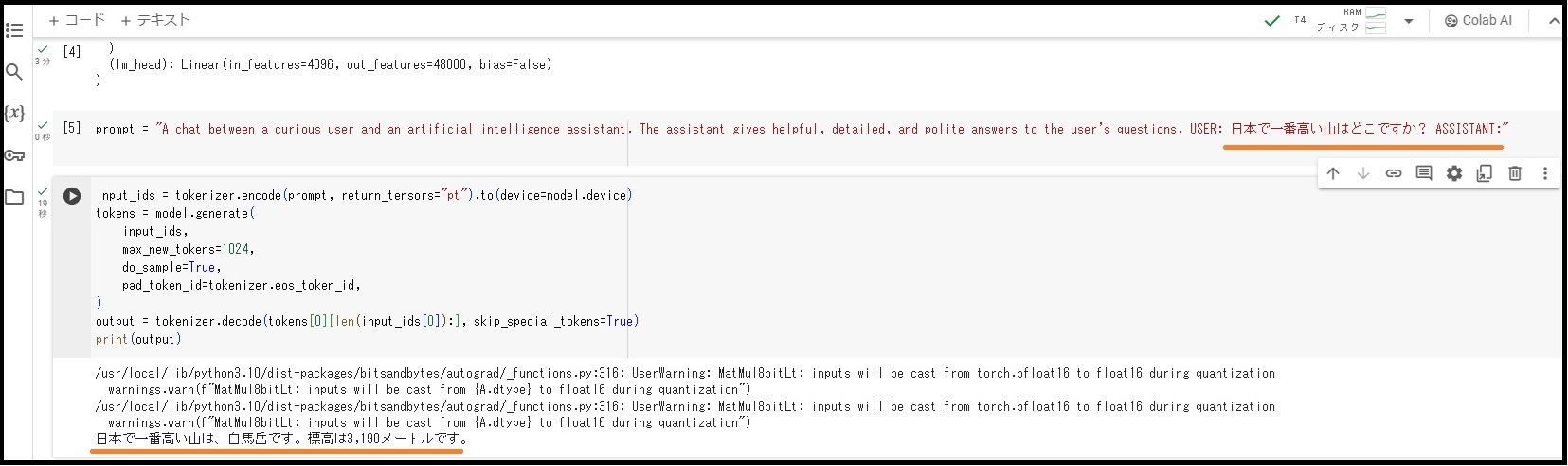
prompt = "A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: 日本で一番高い山はどこですか? ASSISTANT:"
● 推論の実行
|
1 2 3 4 5 6 7 8 9 |
input_ids = tokenizer.encode(prompt, return_tensors="pt").to(device=model.device) tokens = model.generate( input_ids, max_new_tokens=1024, do_sample=True, pad_token_id=tokenizer.eos_token_id, ) output = tokenizer.decode(tokens[0][len(input_ids[0]):], skip_special_tokens=True) print(output) |
しばしば精度の低下が見られます。
ラズパイ5(8GB)で量子化モデルを動かしてみる

OSイメージはRaspberry Pi OS Desktop (64-bit)Bookworm
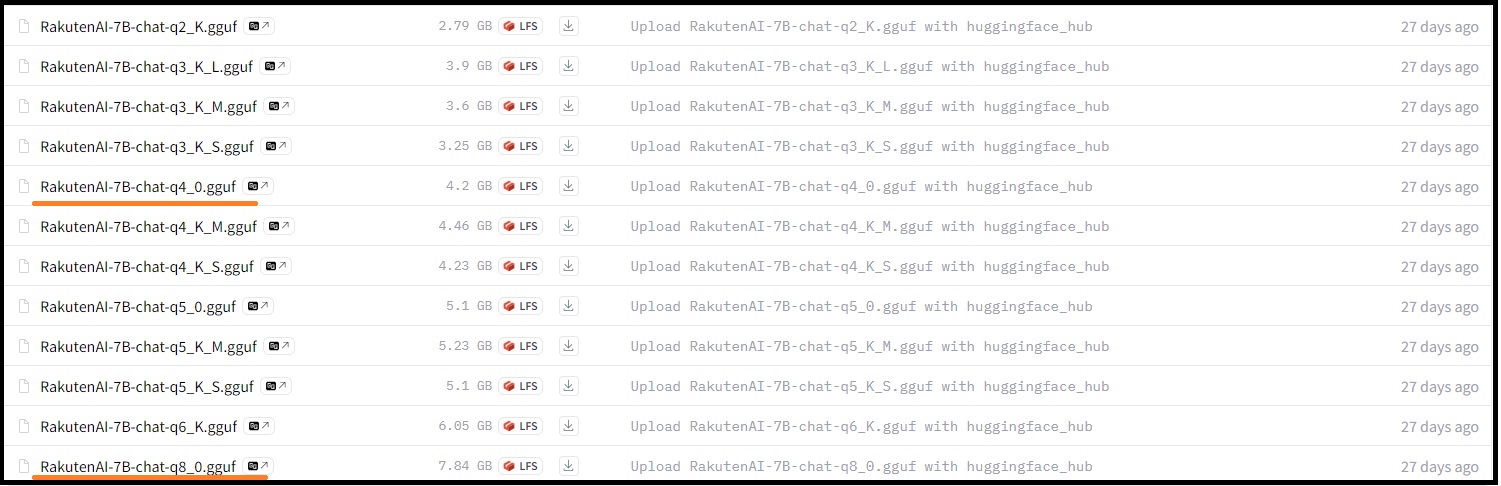
3つのRakutenAIモデルがHuggingFaceにアップされています。
このなかのchatモデルの量子化されたものをmmngaさんがアップされています。
量子化モデルは8bit(RakutenAI-7B-chat-q8_0.gguf)、4bit(RakutenAI-7B-chat-q4_0.gguf)を使ってみます。
別途フォルダーを作ってそこにダウンロードしておきます。
|
1 2 3 4 5 6 |
mkdir ~/models cd ~/models wget https://huggingface.co/mmnga/RakutenAI-7B-chat-gguf/resolve/main/RakutenAI-7B-chat-q8_0.gguf wget https://huggingface.co/mmnga/RakutenAI-7B-chat-gguf/resolve/main/RakutenAI-7B-chat-q4_0.gguf |
● llama.cppのコマンドで実行
llama.cppのインストールに関しては以下を参照。
ラズパイ5(8GB)で、日本語対応の7B(70億)パラメータのLLMを量子化して使ってみる
流れは以下のとおり。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
sudo apt install build-essential pkg-config libopenblas-dev -y python3 -m venv venv1 source venv1/bin/activate pip install transformers accelerate bitsandbytes sentencepiece mkdir llama.cpp curl -L https://github.com/ggerganov/llama.cpp/archive/refs/tags/b1620.tar.gz | tar zx -C llama.cpp --strip-components=1 cd ~/llama.cpp make -j4 LLAMA_OPENBLAS=1 deactivate |
〇 mainコマンド (直接実行)
初回は時間がかかりますが、2回目以降は結構高速です。
|
1 2 3 4 5 6 7 |
source venv1/bin/activate cd ~/models ~/llama.cpp/main -ngl 0 -t 4 -c 8192 --temp 0.0 -e \ -m "./RakutenAI-7B-chat-q8_0.gguf" \ -p "questions.\nUSER: 日本で一番高い山はどこですか?\nASSISTANT:" |
〇mainコマンド (対話モード実行)
-iオプションが対話モードの指定。
|
1 2 3 4 5 |
source venv1/bin/activate cd ~/models ~/llama.cpp/main -m "./RakutenAI-7B-chat-q8_0.gguf" -i --color -ins -n 1024 |
プロンプトを連続して記述できます。
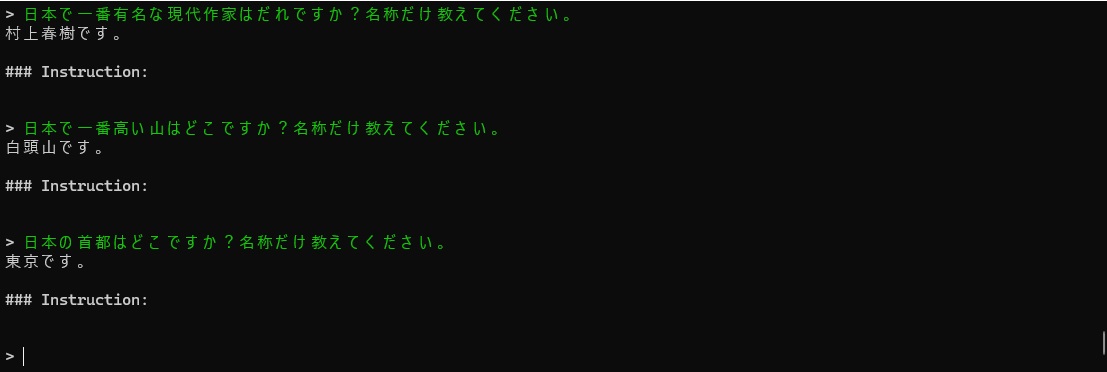
日本の首都はどこですか?名称だけ教えてください。
日本で一番有名は作家はだれですか?
日本で一番高い山はどこですか?
8bitはさすがに正解を答えてくれますが遅いです。
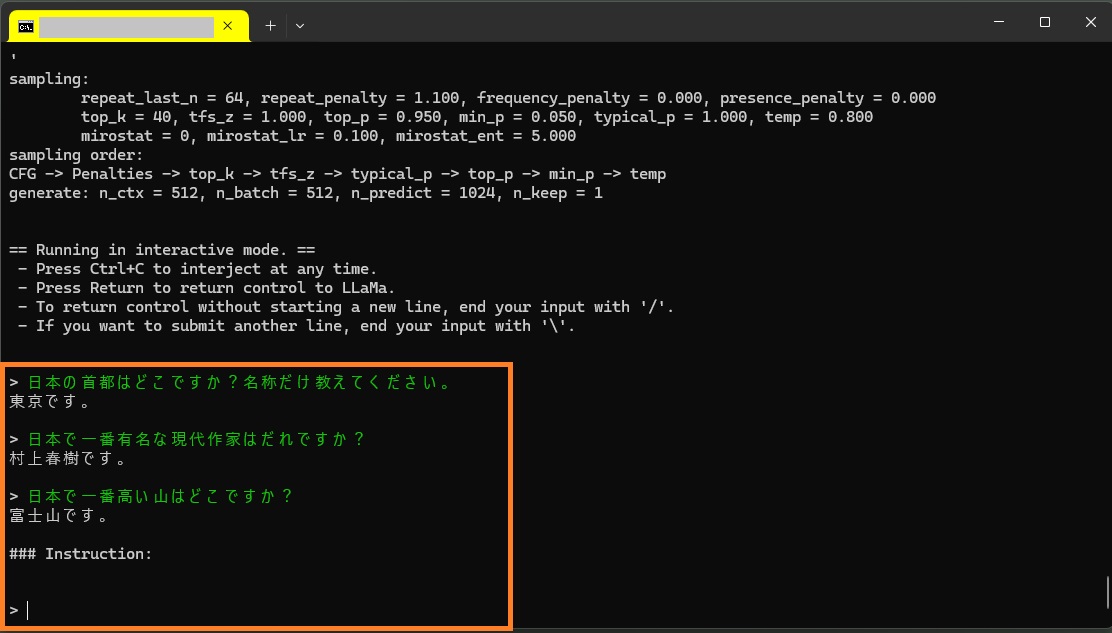
4bitはそれなりに高速ですがホラも入っています。
〇serverコマンド (Web実行)
サーバー
|
1 2 3 4 5 |
source venv1/bin/activate cd ~/models ~/llama.cpp/server -m ./RakutenAI-7B-chat-q8_0.gguf --host 0.0.0.0 -t 4 --port 8000 |
以下が表示されれば、他の端末のブラウザーからポート8000にアクセスできます。
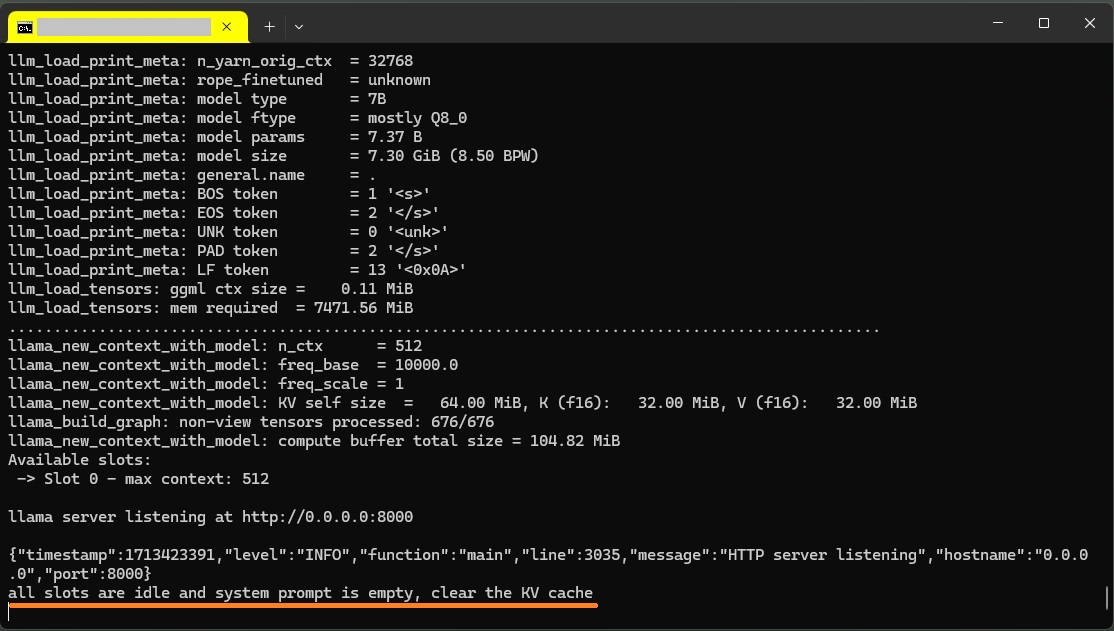
ブラウザー
http://<IPアドレス>:8000
Say something …. と書かれたフィールドにプロンプトを記述してSendボタンをクリック
推論が開始されます。
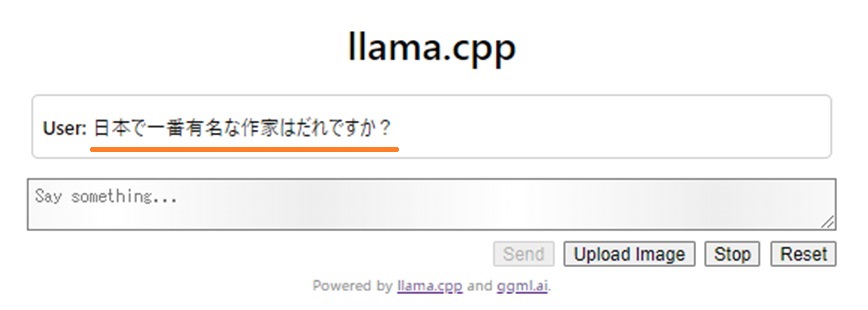
Sendボタンが再びアクティブになったら推論終了です。
なにやらもっともらしい回答ですが、さりげなくウソが混じってます。
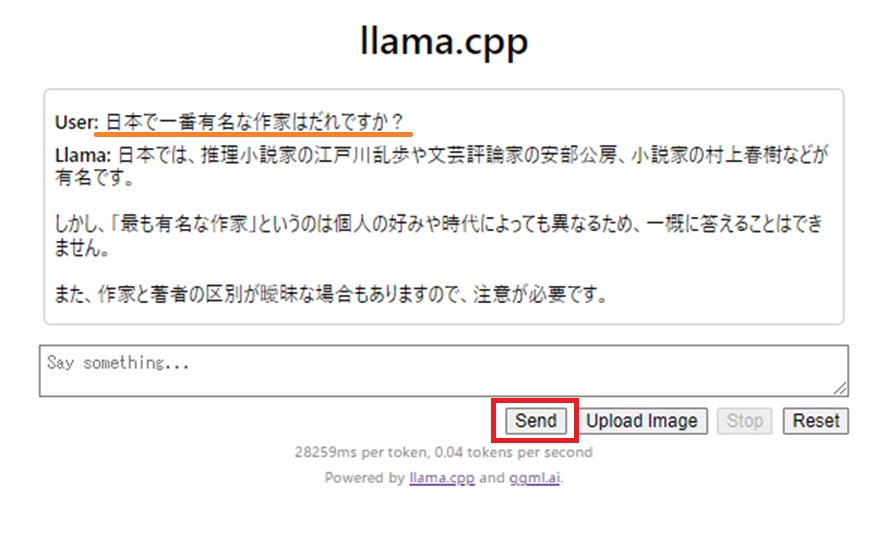
*作家と著者の違いについて昨今岩波文庫の回答が話題です…。
● Python で実行
〇 llama-cpp-pythonを使ってみる
llama-cpp-pythonパッケージをインストールします。
|
1 2 3 4 |
python3 -m venv venv1 source venv1/bin/activate pip install llama-cpp-python |
>sudo nano llamacpp.py
【llamacpp.py】
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
import os from llama_cpp import Llama hd = os.path.expanduser("~") llm = Llama(model_path = hd + "/models/RakutenAI-7B-chat-q4_0.gguf", chat_format="llama-2") while(True): q = input("なにか質問ある?") if (q != ""): a = llm.create_chat_completion( messages = [ {"role": "system", "content": q} ] ) print(a) |
>python3 llamacpp.py
「なにか質問ある?」に続けてプロンプトを記述してリターン。
日本で一番有名な作家はだれですか?
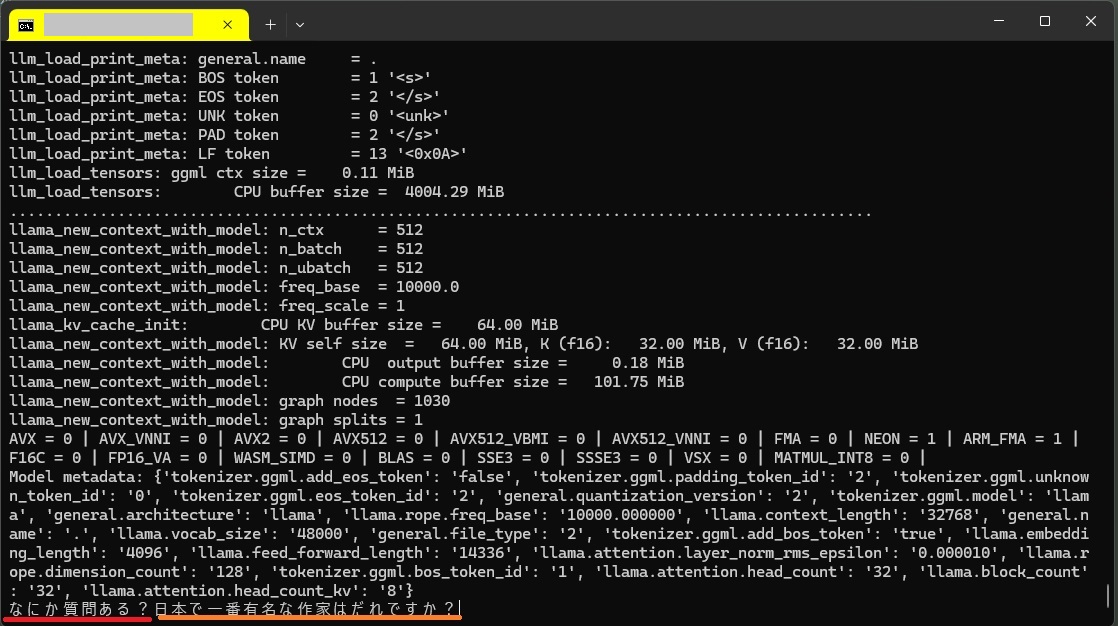
結果
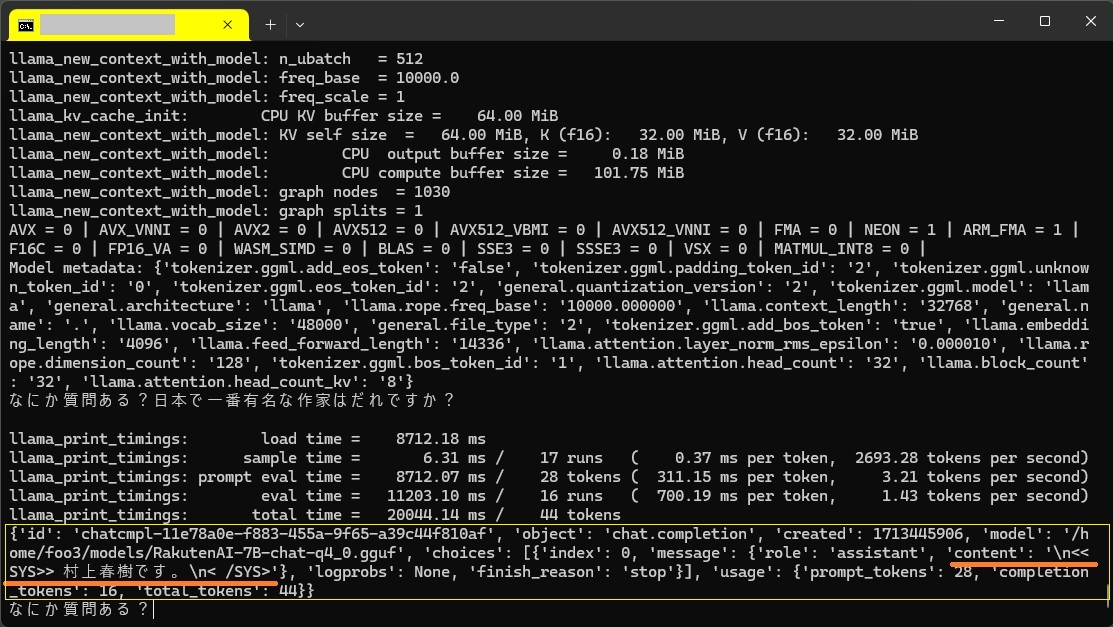
{'id': 'chatcmpl-dd3bc32c-e781-40f8-b57b-1ebdb135d23b', 'object': 'chat.completion', 'created': 1713501405, 'model': '/home/foo3/models/RakutenAI-7B-chat-q4_0.gguf', 'choices': [{'index': 0, 'message': {'role': 'assistant', 'content': '\n<<SYS>> 村上春樹です。\n<BR>[/INST]'}, 'logprobs': None, 'finish_reason': 'stop'}], 'usage': {'prompt_tokens': 28, 'completion_tokens': 19, 'total_tokens': 47}}
なにやらいっぱい出力されています。簡単にします。verbose=Falseにして冗長性をなくします。
llm = Llama(model_path = hd + “/models/RakutenAI-7B-chat-q4_0.gguf”, chat_format=”llama-2″,verbose=False)
結果の出力
print(a[‘choices’][0][‘message’][‘content’])
こんな感じ。

〇 LangChain を使ってみる
LangChain インストール
|
1 2 3 4 |
pythom3 -m venv venv1 source venv1/bin/activate pip install langchain |
ちなみに、langchain_community、langchain_core はpipで個別にinstallすることもできます。
pythonコンソールを起動して質問してみます。
>python3
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
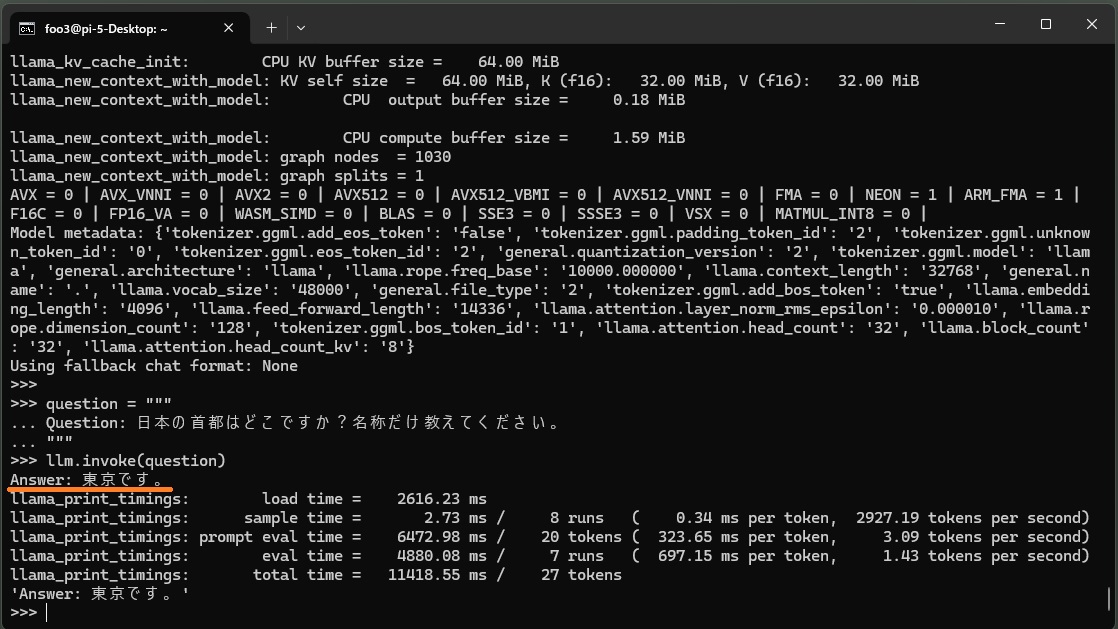
from langchain_community.llms import LlamaCpp from langchain_core.callbacks import CallbackManager, StreamingStdOutCallbackHandler import os callback_manager = CallbackManager([StreamingStdOutCallbackHandler()]) hd = os.path.expanduser("~") llm = LlamaCpp( model_path=hd + "/models/RakutenAI-7B-chat-q4_0.gguf", temperature=0.75, max_tokens=2000, top_p=1, callback_manager=callback_manager, verbose=True, ) question = """ Question: 日本の首都はどこですか?名称だけ教えてください。 """ llm.invoke(question) |
Leave a Reply