
ニューラルネットワークと深層学習の6章にあるnetwork3.pyをubuntu 16.04 + Python3.xでやってみます。
畳み込みニューラルネットワークの実装です。
ソース GitHub
Python 2.x -> Python 3.xへの主なコード修正はこのページ参照
network3.pyの修正コードは以下参照
network3.pyでは機械学習用ライブラリとしてTheanoを使っています。
Theanoのインストール
Kerasをubuntu 16.04 LTS へインストールのページにTheanoのインストも書いています。
Theanoはもう開発中止になっているので、別途Keras + TensorFlowでもやってみる予定。
ただ現状、TheanoもMNISTもこれ以上やる意味はないので、思案中。
感覚というか勘というか….を養う意味でいろいろいじってみるのは重要か?
Jetson Nano(ubuntu 18.04 LTS)でも実行できます。
network3.pyで100のニューロンを含む隠れ層を1つだけを持つ浅いネットワークを
エポック数60、学習率0.1、ミニバッチサイズ10、正規化なしの条件で実行してみます。
実行用ファイル
run3.py
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import network3 from network3 import Network from network3 import ConvPoolLayer, FullyConnectedLayer, SoftmaxLayer training_data, validation_data, test_data = network3.load_data_shared() mini_batch_size = 10 net = Network([FullyConnectedLayer(n_in=784, n_out=100),SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size) net.SGD(training_data, 60, mini_batch_size, 0.1,validation_data, test_data) |
$ python3 run3.py
テキストとほぼ同じ精度です(が、ここでもnetworkやnetwor2と同様に重みとバイアスはランダムに初期化されているので、たまたまだと思います)。
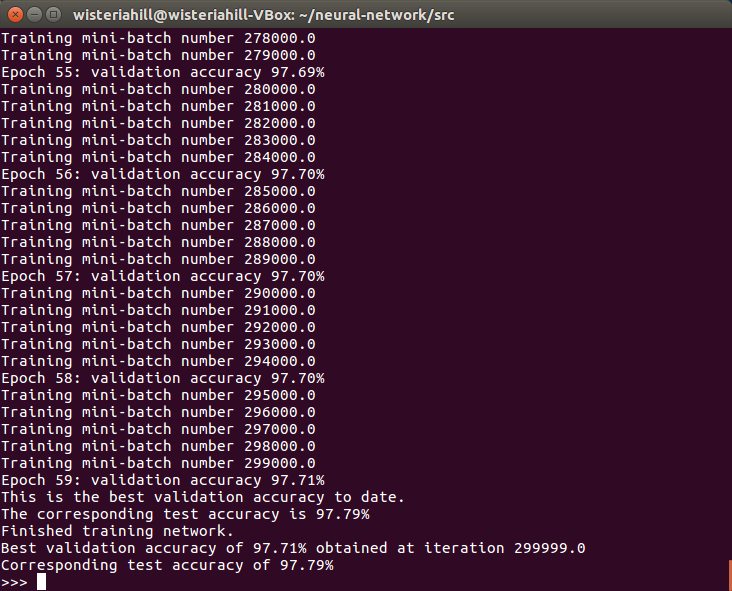
network3.py
Jetson NanoのようにGPUが使える環境ではGPU = Trueですが、その際Print文はコメントアウトしておきましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 |
import pickle as cPickle import gzip import numpy as np import theano import theano.tensor as T from theano.tensor.nnet import conv from theano.tensor.nnet import softmax from theano.tensor import shared_randomstreams #from theano.tensor.signal import downsample from theano.tensor.signal.pool import pool_2d def linear(z): return z def ReLU(z): return T.maximum(0.0, z) from theano.tensor.nnet import sigmoid from theano.tensor import tanh GPU = True if GPU: #print ("Trying to run under a GPU. If this is not desired, then modify "+\ # "network3.py\nto set the GPU flag to False.") try: theano.config.device = 'gpu' except: pass theano.config.floatX = 'float32' else: print ("Running with a CPU. If this is not desired, then the modify "+\ "network3.py to set\nthe GPU flag to True.") def load_data_shared(filename="../data/mnist.pkl.gz"): f = gzip.open(filename, 'rb') training_data, validation_data, test_data = cPickle.load(f,encoding='latin1') f.close() def shared(data): shared_x = theano.shared( np.asarray(data[0], dtype=theano.config.floatX), borrow=True) shared_y = theano.shared( np.asarray(data[1], dtype=theano.config.floatX), borrow=True) return shared_x, T.cast(shared_y, "int32") return [shared(training_data), shared(validation_data), shared(test_data)] class Network(object): def __init__(self, layers, mini_batch_size): self.layers = layers self.mini_batch_size = mini_batch_size self.params = [param for layer in self.layers for param in layer.params] self.x = T.matrix("x") self.y = T.ivector("y") init_layer = self.layers[0] init_layer.set_inpt(self.x, self.x, self.mini_batch_size) for j in range(1, len(self.layers)): prev_layer, layer = self.layers[j-1], self.layers[j] layer.set_inpt( prev_layer.output, prev_layer.output_dropout, self.mini_batch_size) self.output = self.layers[-1].output self.output_dropout = self.layers[-1].output_dropout def SGD(self, training_data, epochs, mini_batch_size, eta, validation_data, test_data, lmbda=0.0): training_x, training_y = training_data validation_x, validation_y = validation_data test_x, test_y = test_data num_training_batches = size(training_data)/mini_batch_size num_validation_batches = size(validation_data)/mini_batch_size num_test_batches = size(test_data)/mini_batch_size l2_norm_squared = sum([(layer.w**2).sum() for layer in self.layers]) cost = self.layers[-1].cost(self)+\ 0.5*lmbda*l2_norm_squared/num_training_batches grads = T.grad(cost, self.params) updates = [(param, param-eta*grad) for param, grad in zip(self.params, grads)] i = T.lscalar() train_mb = theano.function( [i], cost, updates=updates, givens={ self.x: training_x[i*self.mini_batch_size: (i+1)*self.mini_batch_size], self.y: training_y[i*self.mini_batch_size: (i+1)*self.mini_batch_size] }) validate_mb_accuracy = theano.function( [i], self.layers[-1].accuracy(self.y), givens={ self.x: validation_x[i*self.mini_batch_size: (i+1)*self.mini_batch_size], self.y: validation_y[i*self.mini_batch_size: (i+1)*self.mini_batch_size] }) test_mb_accuracy = theano.function( [i], self.layers[-1].accuracy(self.y), givens={ self.x: test_x[i*self.mini_batch_size: (i+1)*self.mini_batch_size], self.y: test_y[i*self.mini_batch_size: (i+1)*self.mini_batch_size] }) self.test_mb_predictions = theano.function( [i], self.layers[-1].y_out, givens={ self.x: test_x[i*self.mini_batch_size: (i+1)*self.mini_batch_size] }) best_validation_accuracy = 0.0 for epoch in range(epochs): #for minibatch_index in range(num_training_batches): for minibatch_index in range(int(num_training_batches)): iteration = num_training_batches*epoch+minibatch_index if iteration % 1000 == 0: print("Training mini-batch number {0}".format(iteration)) cost_ij = train_mb(minibatch_index) if (iteration+1) % num_training_batches == 0: #validation_accuracy = np.mean([validate_mb_accuracy(j) for j in range(num_validation_batches)]) validation_accuracy = np.mean([validate_mb_accuracy(j) for j in range(ini(num_validation_batches))]) print("Epoch {0}: validation accuracy {1:.2%}".format( epoch, validation_accuracy)) if validation_accuracy >= best_validation_accuracy: print("This is the best validation accuracy to date.") best_validation_accuracy = validation_accuracy best_iteration = iteration if test_data: #test_accuracy = np.mean([test_mb_accuracy(j) for j in range(num_test_batches)]) test_accuracy = np.mean([test_mb_accuracy(j) for j in range(ini(num_test_batches))]) print('The corresponding test accuracy is {0:.2%}'.format( test_accuracy)) print("Finished training network.") print("Best validation accuracy of {0:.2%} obtained at iteration {1}".format( best_validation_accuracy, best_iteration)) print("Corresponding test accuracy of {0:.2%}".format(test_accuracy)) class ConvPoolLayer(object): def __init__(self, filter_shape, image_shape, poolsize=(2, 2), activation_fn=sigmoid): self.filter_shape = filter_shape self.image_shape = image_shape self.poolsize = poolsize self.activation_fn=activation_fn n_out = (filter_shape[0]*np.prod(filter_shape[2:])/np.prod(poolsize)) self.w = theano.shared( np.asarray( np.random.normal(loc=0, scale=np.sqrt(1.0/n_out), size=filter_shape), dtype=theano.config.floatX), borrow=True) self.b = theano.shared( np.asarray( np.random.normal(loc=0, scale=1.0, size=(filter_shape[0],)), dtype=theano.config.floatX), borrow=True) self.params = [self.w, self.b] def set_inpt(self, inpt, inpt_dropout, mini_batch_size): self.inpt = inpt.reshape(self.image_shape) conv_out = conv.conv2d( input=self.inpt, filters=self.w, filter_shape=self.filter_shape, image_shape=self.image_shape) #pooled_out = downsample.max_pool_2d( # input=conv_out, ds=self.poolsize, ignore_border=True) pooled_out = pool_2d( input=conv_out, ws=self.poolsize, ignore_border=True) self.output = self.activation_fn( pooled_out + self.b.dimshuffle('x', 0, 'x', 'x')) self.output_dropout = self.output class FullyConnectedLayer(object): def __init__(self, n_in, n_out, activation_fn=sigmoid, p_dropout=0.0): self.n_in = n_in self.n_out = n_out self.activation_fn = activation_fn self.p_dropout = p_dropout self.w = theano.shared( np.asarray( np.random.normal( loc=0.0, scale=np.sqrt(1.0/n_out), size=(n_in, n_out)), dtype=theano.config.floatX), name='w', borrow=True) self.b = theano.shared( np.asarray(np.random.normal(loc=0.0, scale=1.0, size=(n_out,)), dtype=theano.config.floatX), name='b', borrow=True) self.params = [self.w, self.b] def set_inpt(self, inpt, inpt_dropout, mini_batch_size): self.inpt = inpt.reshape((mini_batch_size, self.n_in)) self.output = self.activation_fn( (1-self.p_dropout)*T.dot(self.inpt, self.w) + self.b) self.y_out = T.argmax(self.output, axis=1) self.inpt_dropout = dropout_layer( inpt_dropout.reshape((mini_batch_size, self.n_in)), self.p_dropout) self.output_dropout = self.activation_fn( T.dot(self.inpt_dropout, self.w) + self.b) def accuracy(self, y): "Return the accuracy for the mini-batch." return T.mean(T.eq(y, self.y_out)) class SoftmaxLayer(object): def __init__(self, n_in, n_out, p_dropout=0.0): self.n_in = n_in self.n_out = n_out self.p_dropout = p_dropout self.w = theano.shared( np.zeros((n_in, n_out), dtype=theano.config.floatX), name='w', borrow=True) self.b = theano.shared( np.zeros((n_out,), dtype=theano.config.floatX), name='b', borrow=True) self.params = [self.w, self.b] def set_inpt(self, inpt, inpt_dropout, mini_batch_size): self.inpt = inpt.reshape((mini_batch_size, self.n_in)) self.output = softmax((1-self.p_dropout)*T.dot(self.inpt, self.w) + self.b) self.y_out = T.argmax(self.output, axis=1) self.inpt_dropout = dropout_layer( inpt_dropout.reshape((mini_batch_size, self.n_in)), self.p_dropout) self.output_dropout = softmax(T.dot(self.inpt_dropout, self.w) + self.b) def cost(self, net): "Return the log-likelihood cost." return -T.mean(T.log(self.output_dropout)[T.arange(net.y.shape[0]), net.y]) def accuracy(self, y): "Return the accuracy for the mini-batch." return T.mean(T.eq(y, self.y_out)) def size(data): "Return the size of the dataset `data`." return data[0].get_value(borrow=True).shape[0] def dropout_layer(layer, p_dropout): srng = shared_randomstreams.RandomStreams( np.random.RandomState(0).randint(999999)) mask = srng.binomial(n=1, p=1-p_dropout, size=layer.shape) return layer*T.cast(mask, theano.config.floatX) |
工事中
テキストの課題を解かねば……
テキストの6章ではnetwork3.pyでいろいろな実験的試みを行っています。
GPUを使う場面もありそうです、さくらインターネットの高火力サーバーも使ってみる予定です。
network3.pyを使っていろいろなニューラルネットワークを試してみる
第六章で試しているコードです、ご参考までに。
データ拡張用のexpand_mnist.pyは実行すると本当に数分かかります。
全部をJetson Nanoで実行するのはチトつらい。GoogleのColaboratoryがいいかもしれない、現状Theanoも使えます。2019/04/04時点ではTheano==1.0.4のようです(最終バージョン)。
やってみたいアイデアがあったらコードを書いて実装してみて動くようだったらColabにあげる….という感じ?
(Trial-1)
100のニューロンを含む隠れ層1、訓練のエポック数は 60 、学習率は η=0.1、ミニバッチサイズは 10、正規化なしの条件で実行
>>>import network3
>>>from network3 import Network
>>>from network3 import ConvPoolLayer, FullyConnectedLayer, SoftmaxLayer
>>>training_data, validation_data, test_data = network3.load_data_shared()
>>>mini_batch_size = 10
>>>net = Network([FullyConnectedLayer(n_in=784, n_out=100),SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
>>>net.SGD(training_data, 60, mini_batch_size, 0.1,validation_data, test_data)
JetsonでJupyter-notebook
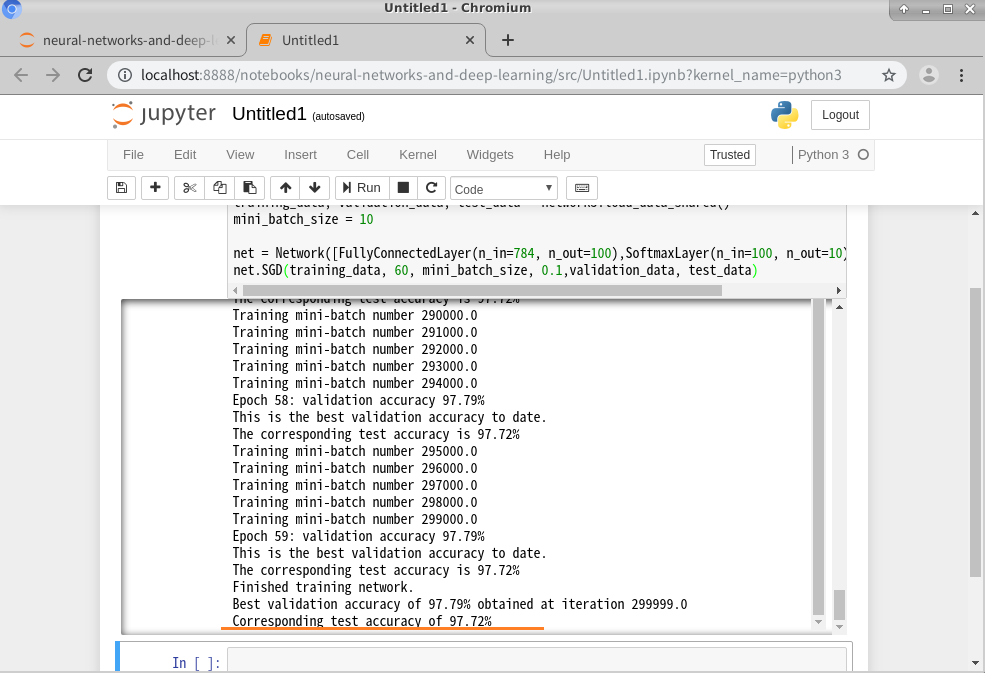
(Trial-2)
ネットワークの最初の層へ、畳み込み-プーリング層を挿入
>>>import network3
>>>from network3 import Network
>>>from network3 import ConvPoolLayer, FullyConnectedLayer, SoftmaxLayer
>>>training_data, validation_data, test_data = network3.load_data_shared()
>>>mini_batch_size = 10
>>>net = Network([
ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
filter_shape=(20, 1, 5, 5),
poolsize=(2, 2)),
FullyConnectedLayer(n_in=20*12*12, n_out=100),
SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
>>>net.SGD(training_data, 60, mini_batch_size, 0.1,
validation_data, test_data)
(Trial-3)
2つ目の畳み込み-プーリング層を挿入
>>>import network3
>>>from network3 import Network
>>>from network3 import ConvPoolLayer, FullyConnectedLayer, SoftmaxLayer
>>>training_data, validation_data, test_data = network3.load_data_shared()
>>>mini_batch_size = 10
>>>net = Network([
ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
filter_shape=(20, 1, 5, 5),
poolsize=(2, 2)),
ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12),
filter_shape=(40, 20, 5, 5),
poolsize=(2, 2)),
FullyConnectedLayer(n_in=40*4*4, n_out=100),
SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
>>>net.SGD(training_data, 60, mini_batch_size, 0.1,
validation_data, test_data)
(Trial-4)
活性化関数をシグモイドではなく、ReLUに変更、訓練のエポック数 60 、学習率 η=0.03 で訓練、パラメータ λ=0.1 としてL2 正規化を使用
>>>import network3
>>>from network3 import ReLU
>>>from network3 import Network
>>>from network3 import ConvPoolLayer, FullyConnectedLayer, SoftmaxLayer
>>>training_data, validation_data, test_data = network3.load_data_shared()
>>>mini_batch_size = 10
>>>net = Network([
ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
filter_shape=(20, 1, 5, 5),
poolsize=(2, 2),
activation_fn=ReLU),
ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12),
filter_shape=(40, 20, 5, 5),
poolsize=(2, 2),
activation_fn=ReLU),
FullyConnectedLayer(n_in=40*4*4, n_out=100, activation_fn=ReLU),
SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
>>>net.SGD(training_data, 60, mini_batch_size, 0.03,
validation_data, test_data, lmbda=0.1)
(Trial-5)
結果を改良する別の手法としての訓練データの拡張
訓練データの各画像を1ピクセルずつ上下左右のいずれかの方向にずらして、入力の 50,000 のMNISTの訓練画像を、 250,000 に増やすことによって過適合を防ぐ効果が期待できる
$ python3 expand_mnist.py
>>>import network3
>>>from network3 import ReLU
>>>from network3 import Network
>>>from network3 import ConvPoolLayer, FullyConnectedLayer, SoftmaxLayer
>>>mini_batch_size = 10
>>>training_data, validation_data, test_data = network3.load_data_shared()
>>>expanded_training_data, _, _ = network3.load_data_shared(
“../data/mnist_expanded.pkl.gz”)
>>>net = Network([
ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
filter_shape=(20, 1, 5, 5),
poolsize=(2, 2),
activation_fn=ReLU),
ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12),
filter_shape=(40, 20, 5, 5),
poolsize=(2, 2),
activation_fn=ReLU),
FullyConnectedLayer(n_in=40*4*4, n_out=100, activation_fn=ReLU),
SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
>>>net.SGD(expanded_training_data, 60, mini_batch_size, 0.03,
validation_data, test_data, lmbda=0.1)
(Trial-6)
サイズの大きな全結合層を追加してみる
>>>import network3
>>>from network3 import ReLU
>>>from network3 import Network
>>>from network3 import ConvPoolLayer, FullyConnectedLayer, SoftmaxLayer
>>>mini_batch_size = 10
>>>training_data, validation_data, test_data = network3.load_data_shared()
>>>expanded_training_data, _, _ = network3.load_data_shared(
“../data/mnist_expanded.pkl.gz”)
>>>net = Network([
ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
filter_shape=(20, 1, 5, 5),
poolsize=(2, 2),
activation_fn=ReLU),
ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12),
filter_shape=(40, 20, 5, 5),
poolsize=(2, 2),
activation_fn=ReLU),
FullyConnectedLayer(n_in=40*4*4, n_out=100, activation_fn=ReLU),
FullyConnectedLayer(n_in=100, n_out=100, activation_fn=ReLU),
SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
>>>net.SGD(expanded_training_data, 60, mini_batch_size, 0.03,
validation_data, test_data, lmbda=0.1)
(Trial-7)
ドロップアウトを全結合層に適用してみる、訓練のエポック数 40、全結合層内のニューロン数 1,000
訓練するエポック数を 40 に減らすことで、ドロップアウトが過適合を抑制するため、高速に学習できる
ドロップアウトはニューロンの多くを効率的に省いているので、全結合層内のニューロン数の増量が必要
>>>import network3
>>>from network3 import ReLU
>>>from network3 import Network
>>>from network3 import ConvPoolLayer, FullyConnectedLayer, SoftmaxLayer
>>>mini_batch_size = 10
>>>training_data, validation_data, test_data = network3.load_data_shared()
>>>expanded_training_data, _, _ = network3.load_data_shared(
“../data/mnist_expanded.pkl.gz”)
>>>net = Network([
ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
filter_shape=(20, 1, 5, 5),
poolsize=(2, 2),
activation_fn=ReLU),
ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12),
filter_shape=(40, 20, 5, 5),
poolsize=(2, 2),
activation_fn=ReLU),
FullyConnectedLayer(
n_in=40*4*4, n_out=1000, activation_fn=ReLU, p_dropout=0.5),
FullyConnectedLayer(
n_in=1000, n_out=1000, activation_fn=ReLU, p_dropout=0.5),
SoftmaxLayer(n_in=1000, n_out=10, p_dropout=0.5)],
mini_batch_size)
>>>net.SGD(expanded_training_data, 40, mini_batch_size, 0.03,
validation_data, test_data)
Leave a Reply