
この方のページを参考にしました。
詳細は譲って、手続きのみをさっさと。
【Google側での作業】
ラズパイでブラウザー(既定はChromium)を開いて、
ACTION CONSOLEでプロジェクトを新規に作成。
以下は例です。
Project
MyAssistant
Language->Japanese
Country->Japan
————————————-
ページを閉じず別タブでGoogle Assistant APIを有効にする
ProjectがMyAssistantになっていることを確認。
有効をクリック
OAuth同意画面のタブをクリック
メールアドレスを設定して保存
————————————-
元のタブに戻って、
緑のアイコンの「Device registration」をクリック
REGISTER MODEL
3つ目のTypeは選びづらいです。根気よくアイコンが変わる場所を探します。
XXX_Project
XXX_Project_A
Lights
Device Model idは控えておきます、後で使います。
myassistant-*****-xxx_project-yyyyyy <=Device Model ID
「REGISTER MODEL」をクリック
「Download OAuth 2.0 credetials」でダウンロード
「NEXT」ボタンをクリックします。
次に、traitsを保存(SAVE TRAITS)するためのページに遷移しますが、ここでは「SKIP」をクリックしてスキップします。
project IDを確認しておく
バーガーアイコンー>Overview
myassistant-***** <= project ID
別タブでアクティビティ管理画面へ
下記の4点の設定を確認してください。
- 「ウェブとアプリのアクティビティ」を有効(青色)に
- 「Chrome の閲覧履歴と Google サービスを使用するウェブサイトやアプリでのアクティビティを含める」にチェック
- 「端末情報」を有効(青色)に
- 「音声アクティビティ」を有効(青色)に
【ラズパイ側での作業】
ターミナルを開く
ダウンロードしたjsonファイルを/home/piに移動しておく
$ mv Downloads/*.json .
仮想環境にAssistantをインストールします。
$ sudo apt-get update
$ sudo apt-get install python3-dev python3-venv
WisteriaHillではこのinstallは失敗しましたが、影響はないようです(?)。
$ python3 -m venv env
$ env/bin/python -m pip install pip setuptools
$ source env/bin/activate
(env) $ sudo apt-get install portaudio19-dev libffi-dev libssl-dev
(env) $ python -m pip install google-assistant-library
(env)$ python -m pip install google-assistant-sdk[samples]
(env) $ python -m pip install google-auth-oauthlib[tool]
|
1 |
(env)$ google-oauthlib-tool --scope https://www.googleapis.com/auth/assistant-sdk-prototype --scope https://www.googleapis.com/auth/gcm --save --headless --client-secrets client_secret_VVVVVVVV.apps.googleusercontent.com.json |
表示されるURLに移動して、Authrization Codeを取得して、ターミナル画面にペーストして完了。
|
1 |
(env) $ googlesamples-assistant-hotword --project_id myassistant-***** --device_model_id myassistant-*****-xxx_project-yyyyyy |
OR
(env) $ google-assistant-demo
●Error 401になる場合
learn moreで対象ページ移動
不足情報(メールの登録など)を補って保存
●Failed to register device PERMISSION_DENIED (403):
Assistant APIが有効になっていない場合もあるので管理画面で有効化
●日本語が認識されない場合
こういうやり方をするそうです
Android端末のアシスタントアプリ(なければPlayからDL)で日本語設定
設定->アシスタントのタブ->アシスタントデバイスー>(作成したプロジェクト名)->アカウントに基づく情報を有効化
●python -m pip install google-assistant-sdk[samples]がExceptionエラーで途中で止まる
理由は不明ですが、エラーにかまわず、最後までインストールを実行し、最後にもう一度、実行します。
何の問題もなくsamplesが入ってしまいます。理由は不明です。
シェルスクリプトでAssistantの仮想環境を起動
仮想環境用のシェルスクリプト
【grpc.sh】
|
1 2 3 4 5 6 7 |
#!/bin/bash cd /home/pi source env/bin/activate googlesamples-assistant-hotword--project-id <プロジェクトID> --device-model-id <デバイスモデルID> |
ターミナルでgrpc.shを実行するシェルスクリプト
【grpc_wakeon.sh】
|
1 2 |
#!/bin/bash lxterminal -e /home/pi/Desktop/grpc.sh |
grpc_wakeon.shに実行権をつけてダブルクリックで起動
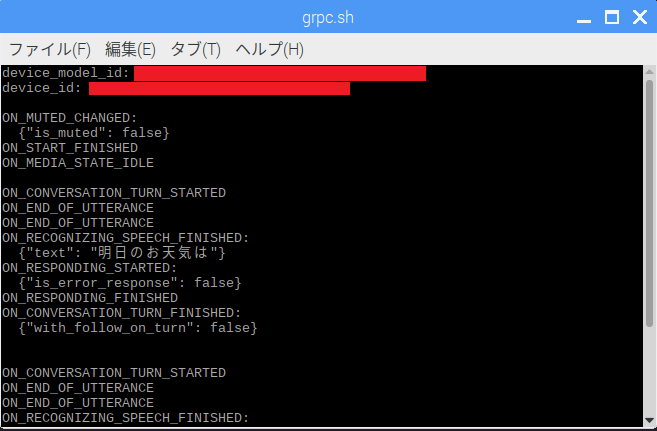
Google Assistant Libraryのhotwordで「ok,google」してお天気を尋ねたの図。
hotwordのメインコード
/home/pi/env/bin/googlesamples-assistant-hotword
↓
/home/pi/env/lib/python3.5/site-packages/googlesamples/assistant/library/hotword.py
/home/pi/env/lib/python3.5/site-packages/google/assistant/library/*
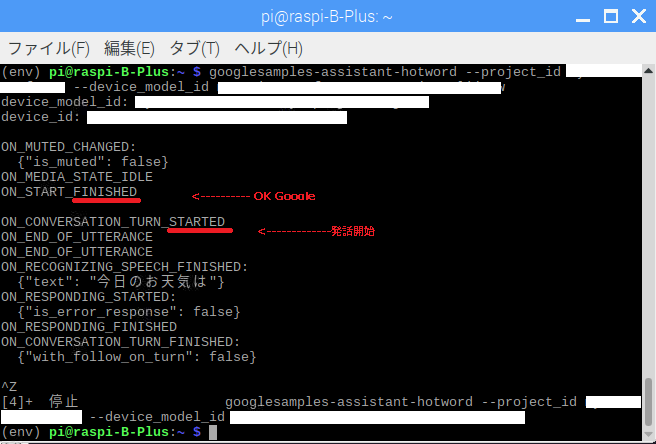
また、hotwordではなくReturnキーをトリガーにすることもできます。
以下のGoogle Assistant Service のpushtotalkとtextinputはhotwordとは異なるコード体系を使っています(gRPC)。
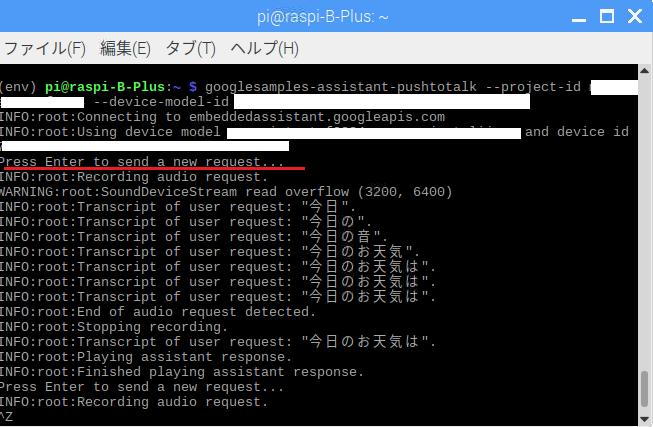
pushtotalkを使った例
hotwordとはオプションの綴りが違います
devaice_model_id -> device-model-id
コードを修正(?)すれば、トリガー無しの連続認識も可能です。
連続認識の場合は、SampleAssistantの中の以下のコードを書き換えます。
|
1 2 3 4 5 6 7 8 9 10 11 |
while True: if wait_for_user_trigger: click.pause(info='Press Enter to send a new request...') continue_conversation = assistant.assist() # wait for user trigger if there is no follow-up turn in # the conversation. wait_for_user_trigger = not continue_conversation # If we only want one conversation, break. if once and (not continue_conversation): break |
ここをシンプルに以下のように記述
|
1 2 |
while True: continue_conversation = assistant.assist() |
この場合、環境ノイズも拾っているみたいで、nullというか空が返ってきているようだけど、これもリクエストにカウントされているのかな?認識できない場合はノーカウント?
要調査です。
どうも環境ノイズもカウントしているっぽいですね。Juliusがウェイクワードをキャッチするまでは、continue_conversation = assistant.assist()をブロックしておいた方がいいようです。
あるいは、文字入力をトリガーにして応答を返すこともできます。
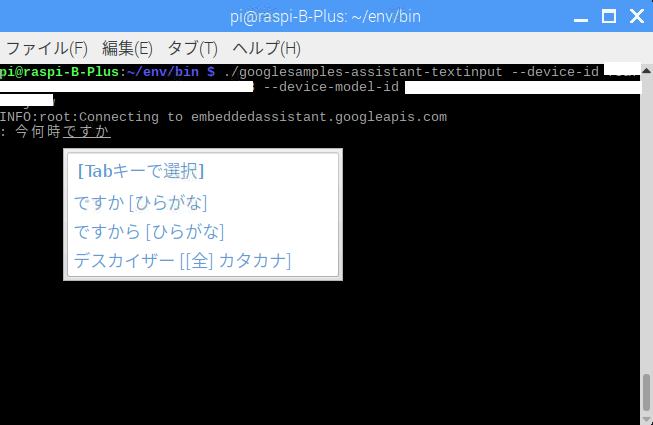
textinputを使った例
textinput ではdevice-idのオプションが必要
googlesamples-assistant-pushtotalkの画面で表示されるので控えておきましょう
この場合は音声応答ではなく文字で応えてくれます。
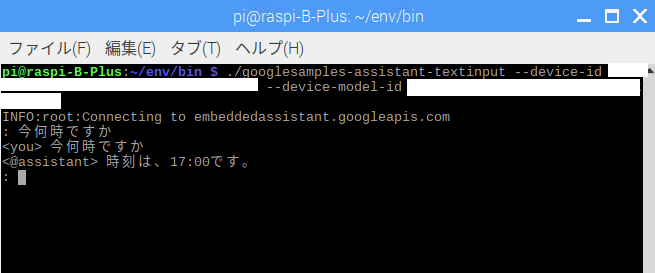
なお、pushtotalkもtextinputもServiceというシステムのサブセットのようなもので、まったく別々のものというわけではないです。
Assistant SDKにあるpushtotalk.pyとtextinput.pyのコードを見比べるとじんわり分かります。
従って、例えばpushtotalkで音声認識した結果と応答を共にテキスト形式で取得するということも可能です。
逆に、文字入力を受けて、応答を音声で出力することも可能です(Googleの音声合成の声が気に入ってればの話ですけど)。
JulilusとGoogle Assistantを連携させてみる
JuliusをフロントエンドにしてAssistantと連携するワケ。
〇現状では、認識精度はAssistantの方が上。
Juliusの認識精度をAssistant並みに向上できれば連携は不要なのだが。
〇Assistantには制限がある(引っかかったらJulius単体に切り替え)。
クラウドが使えない環境でスタンドアローンの自己完結型でも使いたい。
〇ウェイクワード(ホットワード)に好きなものを使いたい。
こういうものもあるそうです(Porcupine と Snowboy)
WisteriaHillはスマートスピーカーを使う予定はないので見送っています。
〇応答に他の音声合成エンジンを使いたい。
〇色々な家電やセンサーの制御に使いたい。
〇Assistantは発声を認識して結果を返してくれるだけで十分。応答は必ずしも必要ではない。
〇応答結果を他のメディア(メールやブラウザー、メモ、即応性の良いUSBサーマルレシートプリンターなど)に渡したい。
サーマルプリンターはレシートに使うわけではなく、メモ程度のものをさっさと印刷するのに使います。
〇「繰り返して」というようなフレーズをJulius側で認識できれば、Assistantの応答を聞き直せるようにしたい。Assistantを使うかどうかの判断をJuliusサイドに任せる(繰り返して…というワードの認識精度は結構高いです)。
〇質問したら即応答が返ってきたり、淡々と「わかりません」とか「おやくにたてそうもありません」みたいに応える、あの愛想の無さを何とかしたい。
…..etc
Juliusを使ったプロセスとAssistantのプロセスはsocketで接続しています。
マイクからの音声はJuliusとAssistantの両方に渡されます。
Assistantの方はまずはブロックしておきます。
Juliusがウェイクワードを拾ってからAssistantのブロックを解除します。
Juliusサイドからは「はいはーい」みたいな返答を返します。これがAssistantに命令なり質問なりを行うキュー出しになります。
こうすることで、Assistantが無意味に環境ノイズを拾いまくるのを防ぎます。
Julius -> Assistant
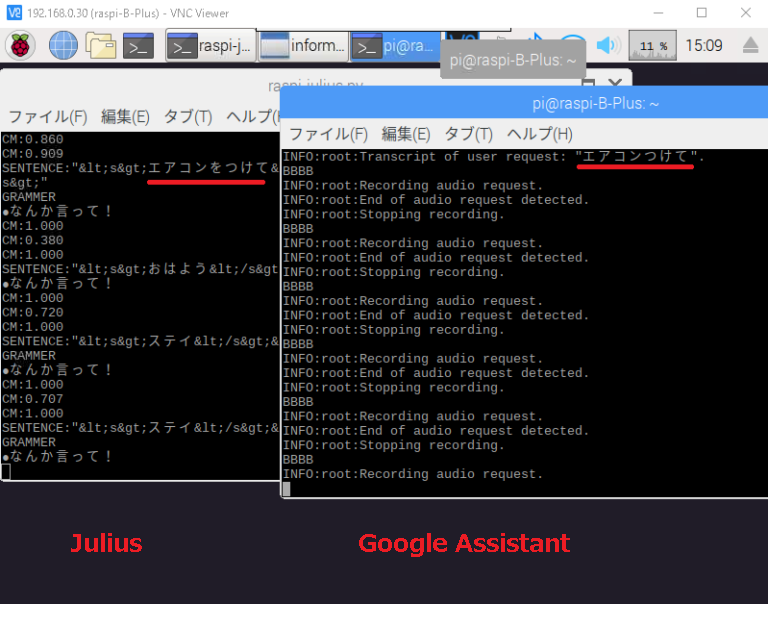
Assistant -> Julius
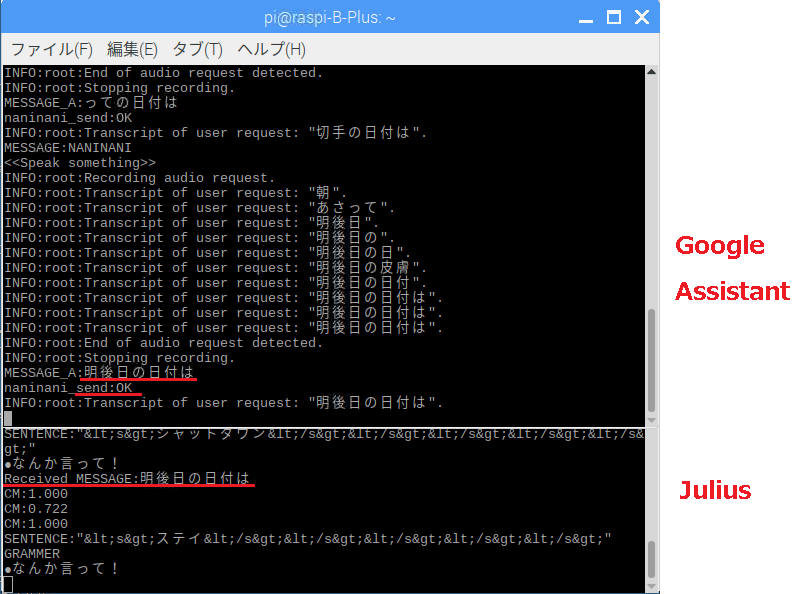
JuliusとAssistantを連携させる場合、厄介なのは家電制御にも使う場合です。
発話内容が、「~して!」というお願い系なのか「~って何?」という質問系なのかをJulius側で判断しないといけない。
Assistantからは発声の認識と、発話内容についての応答の2つの結果が返ってくるので発声の認識結果から家電制御するか応答をそのまま音声合成して流すかの判断。
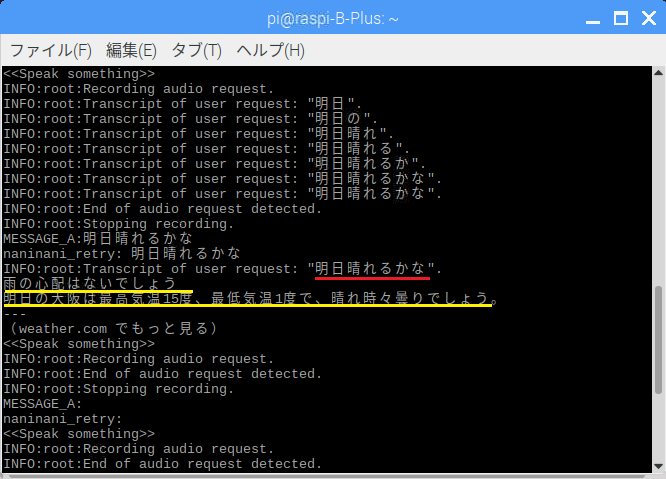
例えば、お願い系の発話
赤が発声の認識結果、黄色が応答です。Google Homeは使う予定はないのでこんな応答になっています。
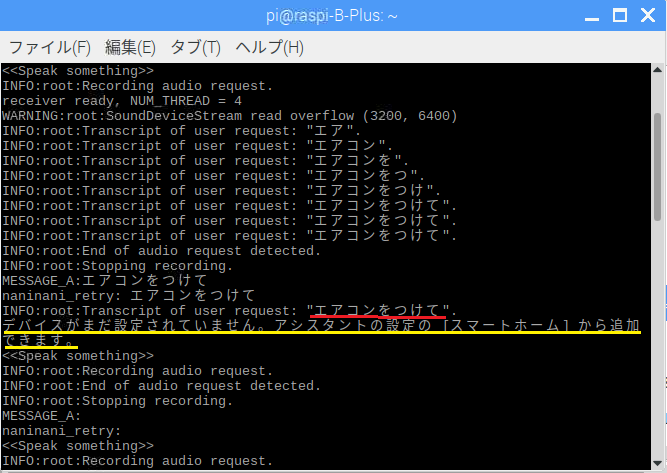
質問系ならこんな感じ。
間違って認識した結果の応答は棄却するという判断も必要。
形態素解析だけで何とかなるものなのか思案してみます。
あるキーワードが含まれるかどうかだけなら、分かち書きがあればいいだけだけど…。
要は、ワードと品詞と並び順で判断できるのか……ということ。
同じような応答が返ってくるようなら、そこで判断してもいいですし。
ウェイクワード(ホットワード)を別にする….という手もあるし。
Juliusについてはこのページ参照
コードの紹介とかその他いろいろ準備中
レーベンシュタイン距離が判断に使えるか調べてみます。
マイクからの入力をJuliusとAssistantの両方に渡す
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
pcm.!default { type asym capture.pcm "mic" playback.pcm "speaker" } pcm.mic { type plug slave { pcm "hw:0,0" } } pcm.speaker { type plug slave { pcm "hw:0,0" } } |
この状態で一度Juliusを起動して、走っているのを確認して終了。 今度はAssistantを起動して、走っているのを確認して終了。 次に、.soundrcを改名(例:.soundrc_X)しておきます。 で、Juliusを起動して、同時にAssistantを起動します。 両方機能すると思います。 もっとうまいやり方があると思うので調査中。 *注
考え方が間違ってる?
両方に渡されないのは.asoundrcが原因なのだから削除すればいい....が正解?
-->JulisやAssistantがマイクのような入力デバイスを見失って起動できない場合があります。
ALSA設定ファイル(/home/pi/.asoundrc)が原因の場合があります。
対策 -> 削除
このALSA設定ファイルはメニュバーの設定で出力先の変更をしたり、ハード的に変更したりすると勝手に作られてしまうので注意が必要です。
Leave a Reply